Ieri ho sviluppato un importante aggiornamento allo script per guardare e scaricare i video da Rai.tv e Rai Replay, grazie anche alla segnalazione e al supporto di Domenico, un lettore che mi domandava come scaricare la prima parte del film su Olivetti.
Infatti la Rai ha pubblicato entrambe le parti, andate in onda il 28 e 29 ottobre, sul servizio Rai Replay, tuttavia la prima parte è stata resa disponibile solo tramite Silverlight (noi pinguini non possiamo nemmeno guardarla) e nella versione per cellulari e tablet. Nessun file MP4 per le Smart TV.
Come avrete già letto qui sul blog, il mio script usava proprio la versione Smart TV per servirvi un file MP4 ad alta qualità. Questo comportava anche il fatto che i video non disponibili per la televisione intelligente risultassero non cliccabili, oltre che non scaricabili.
Da oggi, con la versione 6.0 potete vedere e scaricare anche la versione per tablet. 😀 Questo è necessario solo quando non è disponibile un file MP4, infatti lo script seleziona automaticamente il video migliore e vi fornisce il link per scaricarlo, oppure la linea di comando necessaria.
Infatti se siete costretti a servirvi della versione per tablet, potete usare Gnome Mplayer oppure VLC media player per visualizzare lo stream in formato M3U8 e il software FFmpeg per effettuare il download. Il mio script si occupa di estrarre automaticamente la qualità più alta per voi e genera da solo la linea di comando adeguata.
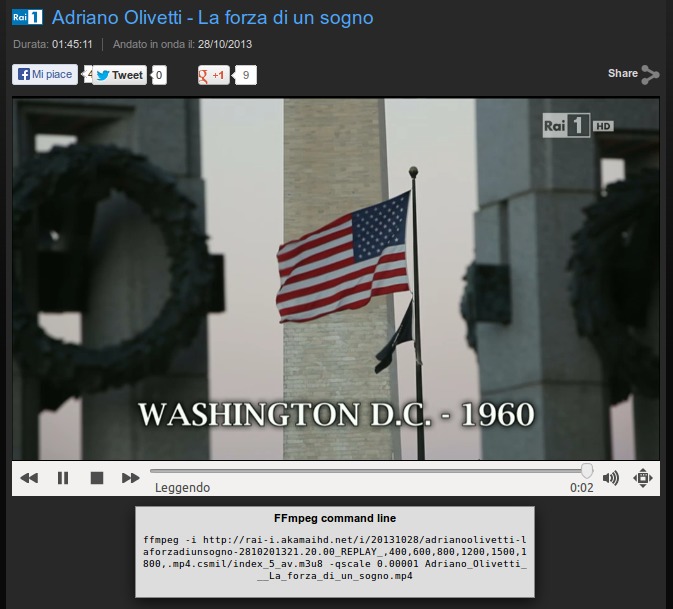
Output della nuova versione dello script, che consente di scaricare anche i video disponibili solo per dispositivi mobili
Se avete già lo script l’aggiornamento dovrebbe essere automatico. Se volete aggiornare manualmente oppure se volete installarlo da zero, trovate tutti i dettagli nel mio post apposito, assieme alle istruzioni dettagliate per usare la nuova funzionalità. 😉
Il 30 Novembre a Udine si terrà l’Open Source Day 2013, una importante «manifestazione organizzata annualmente da AsCI ed IGLU Gruppo Linux Udine con lo scopo di divulgare, tramite talk, workshop e molto altro, i programmi e la filosofia Open Source». Quest’anno sono stato invitato a partecipare come relatore e terrò una conferenza su Gimp, la quale è stata inclusa all’interno del percorso Multimedia:
Percorso Multimedia (Aula 1)
09.30 — 10.15 RuneAudio: embedded Hi-Fi music player (Andrea Coiutti)
10.30 — 11.15 Mixxx: diventa un DJ col software libero (Micky Perini)
Gli altri percorsi della manifestazione sono Embedded, Professional, Security e Forensics. È superfluo dire che approfitterò dell’occasione per seguire quanti più interventi possibile relativi all’informatica forense. 😉 Per maggiori informazioni vi rimando al programma ufficiale linkato qui sotto.
Data la recente chiusura del repository Medibuntu, ho aggiornato la mia guida all’installazione dei codec, la quale rimane attualmente uno degli articoli più consultati su questo blog. Le indicazioni sono valide anche per le versioni precedenti di Ubuntu (almeno dalla 12.04 in poi). 😉
Nel caso in cui abbiate ancora attivato il repository di Medibuntu, vi consiglio di disattivarlo al fine di non ricevere errori durante gli aggiornamenti.
Come avrete notato non ho scritto molto quest’estate, inoltre ho tenuto in sospeso un paio di articoli addirittura dal tardo 2012. Questo è successo per una signora molto dispotica chiamata “tesi di laurea”, la quale tuttavia oggi è stata gentilmente salutata e non disturberà più. 😀 Nel frattempo ho provveduto anche ad aggiornare questo strumento (lo script) messo a disposizione sul blog, e se lo utilizzate è importante che leggiate di seguito.
I miei script per salvare i video dai siti di Rai, Mediaset e La7 hanno riscosso un successo notevole e vengono utilizzati quotidianamente da molte persone. Questo mi fa molto piacere, tuttavia recentemente ci sono stati alcuni problemi con lo script per video.mediaset.it.
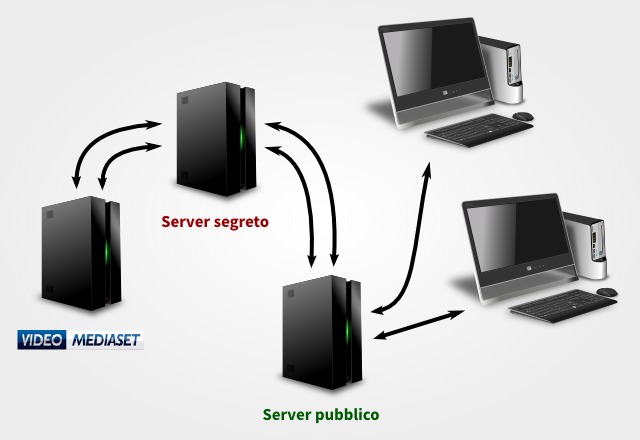
I più tecnici tra di voi avranno infatti già notato che il mio script per Greasemonkey e Tampermonkey, installato dagli utenti, si interfaccia con un server intermedio per ottenere i link ai video. La situazione è illustrata meglio in figura e di seguito è spiegato passo-passo.
Schema di funzionamento dello script per il download da Video Mediaset
Procedimento:
l’utente scarica Greasemonkey o Tampermonkey e poi installa il mio script
lo script chiede al server pubblico (in verde) gli indirizzi dei file corrispondenti al video visualizzato dall’utente
il server pubblico interroga il server segreto (in rosso) richiedendogli di scovare i link
quest’ultimo trova i link sul sito di Mediaset e li rimanda indietro
il mio script mostra in un riquadro i video e l’utente li visualizza
Il server pubblico era (ed è) una pagina ospitata su uno dei tanti servizi di free hosting statunitensi. Si tratta del sito il cui indirizzo è incluso nel codice sorgente del mio script. Tale pagina ha lo scopo di interfacciarsi e mascherare il vero server (quello “segreto”) che si occupa di trovare i link per voi. Quest’ultimo è ubicato in Italia e si maschera sia da PC che da telefono cellulare. Non è opportuno che io fornisca ulteriori dettagli in merito. 😉
Gli scopi sono due:
estrarre anche i link in formato MP4 per cellulari, cosa non possibile su Chrome senza interventi manuali e tediosi da parte dell’utente
permettere anche a chi risiede all’estero di vedere le trasmissioni
Veniamo al problema: il tremendo successo dello script, unito ad alcuni problemi ricorrenti al precedente servizio di hosting, hanno fatto sì che per alcuni giorni i link non comparissero, in quanto il sito veniva disattivato perché sovraccarico. Questo inoltre è successo più di una volta ed è risultato per me nel ricevere numerosi commenti, tweet e messaggi via email chiedendo lumi, oppure suggerendo che lo script dovesse essere aggiornato.
Non sarebbe stato un problema anche se ero in tesi, ad eccezione del fatto che voi utenti avreste dovuto attendere qualche giorno. Tuttavia il fatto che non dipendesse da me rendeva impossibile risolvere la situazione rapidamente, a meno di non cambiare completamente le cose.
È quello che ho fatto.
Ho attuato lo spostamento del server pubblico (di fatto un “collo di bottiglia”) su un altro hosting, che uso già per il mio blog secondario. Ho usato, con un po’ di simpatia, l’indirizzo http://video.lazza.dk (non si vede granché perché non è un sito con contenuti, ha il solo lo scopo di servire il mio script). 😀
Oltre a questo, mi sono premurato di proteggere il sito dal “troppo successo”: ora il dominio viene gestito tramite CloudFlare, un servizio che fa da CDN e DNS. Senza entrare nei dettagli, diciamo che tiene a disposizione delle copie degli indirizzi dei video più cliccati, così spesso il server pubblico non viene neppure “toccato” e l’utente riceve subito una risposta. Inoltre protegge da attacchi informatici di vario genere.
Questo riduce il carico e aumenta drasticamente l’affidabilità del servizio. Per questo è importantissimo che controlliate di avere lo script aggiornato. Da stasera, coloro i quali saranno rimasti alla versione vecchia per qualche motivo, vedranno un video “di avvertimento” che li invita ad aggiornare.
Per aggiornare lo script recarsi nell’apposito articolo e seguire le istruzioni per installarlo. La versione aggiornata sostituirà quella precedente.
Ricordo che se utilizzate già una versione non troppo vecchia dello script l’aggiornamento dovrebbe essere automatico e sarà già avvenuto mentre state navigando. 😉 Mi spiace per aver richiesto la vostra attenzione per il tempo necessario a leggere questo post, tuttavia lo script viene acceduto in media da 250 visitatori unici ogni giorno, con picchi di 1000 richieste di video quotidiane, perciò è necessario prendere le misure necessarie affinché tutto funzioni bene. 🙂
Con grande piacere vi annuncio che anche quest’anno GrappaLUG si occupa di organizzare il Linux Day a Bassano del Grappa. La data che vi dovete segnare in calendario è il 26 ottobre 2013. Per chi ancora non lo sapesse, il Linux Day è una giornata culturale sul software libero. Cito dal volantino:
Il Linux Day è una giornata nazionale dedicata alla divulgazione della cultura informatica, in particolare quella legata al software libero. Durante l’evento si svolgono diversi interventi a tema, è aperto un laboratorio per tutto il giorno dove si possono provare le applicazioni libere e i membri di GrappaLUG sono a disposizione del pubblico per domande o dubbi.
Si tratta di un evento ad accesso libero e gratuito che interessa a tutti perché tutti siamo utenti di software libero, direttamente o indirettamente. Google (incluso Youtube) e Facebook usano molto software libero per fornire i loro servizi, e Linux è anche la base di Android e delle Smart TV. Se usate uno qualsiasi di questi prodotti, potete goderveli perché esiste il software libero, quindi perché non scoprirne di più? 😉
Quest’anno il focus di GrappaLUG è quello di realizzare un volantino completo in digitale, tant’è vero che non abbiamo ancora stampato nulla di cartaceo ed è probabile che non lo faremo o sarà in tiratura molto limitata. Perciò eccone qui un’anteprima, cliccate e potrete leggere il programma completo e gli orari. Vi aspettiamo! 🙂
Volantino digitale del Linux Day 2013 a Bassano del Grappa
Nei meandri della rete a volte si nascondono delle vere e proprie gemme. Un lettore mi ha recentemente segnalato questa, indicata nel blog di Andrea Ferroni in un articolo anche un po’ vecchiotto, eppure bella e funzionante. Cito testualmente:
Installate, se non li avete già, i pacchetti mplayer e xmlstarlet. Scaricate questo script sul vostro computer, rendetelo eseguibile e rinominatelo da “rai.txt” a “rai”. A questo punto eseguitelo da console e vi comparirà l’elenco dei canali. La procedura, per chi ha Ubuntu, Debian o derivate, è:
sudo apt-get install mplayer xmlstarlet
wget -O rai http://fabrizio.zellini.org/magick/rai.txt
chmod +x rai
Per vedere RAI1, ad esempio, è sufficiente lanciarlo come ./rai 1, per RAI Sport ./rai sport.
Aggiungo anche che se non lo avete dovete installare pure curl, come mi è stato segnalato nei commenti. Lo script è stato realizzato da Fabrizio Zellini e nella sua semplicità è geniale: usa gli stream della Rai indicando gli header necessari a convincere il server che “va tutto bene” e quindi si visualizzano le dirette con Mplayer. Il risultato è una aggiunta perfetta al mio script che consente invece di vedere i video on demand del medesimo sito.
Una mia nota personale: se nel codice dello script cambiate il comando da mplayer a gnome-mplayer (posto che abbiate installato quest’ultimo) avrete la possibilità di usare una GUI un po’ più ricca e che consente di impostare il rapporto di aspetto e cose simili. 😉
È anche questo il bello del software libero: l’unione fa la forza!
Se state pensando che Sage sia “solo” un software open source per fare matematica siete un pochino riduttivi. Certo, è un software — o meglio una distribuzione software con un’interfaccia Python unificata — progettato per dare del filo da torcere a strumenti commerciali come Mathematica e Matlab, tuttavia nulla vi dice che lo potete usare solo per studiare matematica o fare delle ricerche scientifiche.
Ho deciso di scrivere questo post tanto per mostrare un uso “simpatico” e insolito di questo software libero, ovvero quello di risparmiare nella scelta del piano telefonico. Di recente sono tornato dalla Danimarca, perciò era il momento di passare a TIM, dato che è l’unica ad avere offerte decenti per l’utilizzo che ne faccio io e più o meno l’80% delle persone tra i 16 e i 24 anni in Italia, in particolare parlo di TIM Young.
Il “problema” quando si sceglie un operatore è che molti, se non tutti, decidono (a parte le possibili opzioni) di usare il classico piano tariffario di base che costa un buon prezzo al minuto, ma ha lo scatto alla risposta e viene tariffato a scatti anticipati di 30 secondi. Tuttavia spesso esiste anche un piano senza scatto alla risposta e tariffato al secondo, anche se il prezzo al minuto è più alto. Nel caso di TIM i piani che ho valutato sono:
Piani base di TIM presi in considerazione
Ebbene, vi mostrerò come usare Sage per dimostrare che TIM ZeroScatti è più conveniente di TIM 12 e che gli operatori si fanno una valanga di soldi con lo scatto alla risposta.
Partiamo dal principio: per gli SMS si vede subito che costano meno, ma quello poco importa visto che TIM Young dà 1000 SMS al mese inclusi nel prezzo, quindi ci interessano le chiamate. La prima cosa da fare è definire due funzioni per rappresentare le tariffe. Sage ci permette di definire e rappresentare su un grafico funzioni completamente arbitrarie, ma non solo cose del tipo 3x²+sin(x), bensì vere e proprie funzioni programmate in Python (anzi, nel linguaggio esteso di Sage). Ecco il codice per i due piani:
def tim_12(s):
s = floor(s)
while (s % 30 != 0):
s += 1
return 18 + 12*(s/60)
def tim_zeroscatti(s):
s = floor(s)
return ceil(s*20/60)
La prima è più complicata perché oltre ad arrotondare i secondi a un numero intero, ovviamente, bisogna anche incrementarli fino ad un multiplo di 30, poi sommare lo scatto. A questo punto, è sufficiente usare le funzionalità grafiche di Sage per creare in pochi semplici comandi un grafico molto chiaro:
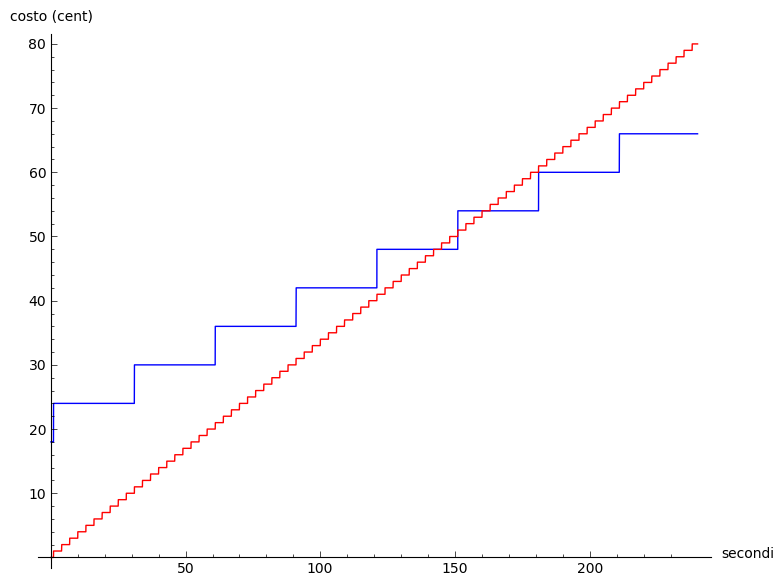
Risultato finale con in rosso la tariffa ZeroScatti
Il risultato finale è che possiamo vedere a colpo d’occhio com’è la situazione. Se anche voi come me siete persone che non stanno sempre 30 minuti al telefono ad ogni chiamata, ma anzi solitamente le vostre chiamate durano meno di 2 minuti e 40 secondi allora significa che vi conviene notevolmente usare un piano tariffario senza scatto.
Detto questo, ovviamente ci vogliono pochi minuti a cambiare il codice per adattarlo alle tariffe di altri operatori e fare diverse prove in modo da scegliere la migliore, l’importante è che prima di cambiare operatore conosciate tutti i piani tariffari che potete scegliere, perché al negozio solitamente evitano di dirveli adducendo scuse cretine (ho sentito di persona frasi come “ah sì ci sarebbe anche quello che dice, però sono 20 cent al minuto”). Se non volete installare subito Sage potete provare e modificare il mio codice direttamente online sul Sage Cell Server.
L’Optical Character Recognition è il famoso processo per cui un software analizza una immagine di un testo (solitamente stampato) e tenta di effettuarne la conversione in un documento modificabile. Questo può essere sia un semplice file di testo che una pagina formattata, dipende dal software. Sotto piattaforma Linux esistono diversi strumenti molto validi per questo “lavoro”, a cui si aggiungono alcuni siti web che svolgono questo compito. Tuttavia, io desideravo in particolare effettuare una operazione che sta diventando sempre più popolare, ovvero il cosiddetto PDF sandwich. Ci possono essere due situazioni in cui potete trovarvi ad avere questa necessità:
Possedete un PDF di pagine scansionate, magari a partire da immagini belle pulite e ottimizzate con ScanTailor.
Avete un PDF di un articolo scientifico compilato con LaTeX, quindi sembra che ci sia il “testo vero” ma in realtà se provate a fare copia incolla (o una ricerca) tutto quello che viene fuori sono caratteri apparentemente privi di senso. Un esempio è questo paper, tra quelli che devo leggere per la mia tesi.
In entrambi i casi, il vostro scopo è ottenere un documento il cui aspetto esteriore sia lo stesso (quindi mantenendo le immagini) ma che sia ricercabile. Ciò viene realizzato da software appositi che creano un livello trasparente con del “vero testo” usando le tecniche OCR. Il risultato non sempre è perfetto, ma sicuramente è molto meglio di avere documenti totalmente non ricercabili. Ci sono alcuneguide e script in merito, nonché un live CD nato per fare solo questo.
Tuttavia sono tutte tecniche basate sullo stesso principio: usano Tesseract oppure Cuneiform per creare un file hocr e poi hocr2pdf per creare il risultato finale. Io ho provato personalmente numerosi tutorial e programmi ma il problema è sempre lo stesso: il testo sovraimposto è spesso di dimensioni sbagliate, un po’ a casaccio, e a volte è completamente spostato rispetto alle parole visualizzate. Insomma, il risultato è indegno.
La soluzione funzionante
Alla fine mi sono arreso e ho optato per un software per Windows tramite Wine, in particolare PDF-Xchange Viewer. È un programma che nella versione a pagamento fa un sacco di cose che a me non servono, ma la versione gratuita ha un motore OCR niente male che allinea il testo precisamente e riconosce le colonne abbastanza bene.
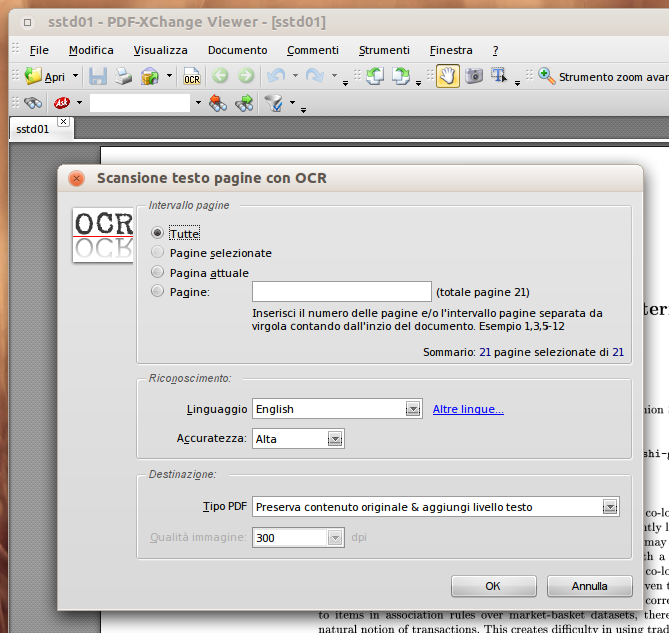
Finestra OCR del programma
La finestra di riconoscimento è molto semplice da usare e consente di scegliere la lingua e il tipo di PDF. Se il vostro PDF contiene già immagini scegliete la prima voce, ovvero Preserva contenuto originale & aggiungi livello testo. Se invece è un PDF con “falso testo” l’altra opzione vi consente di convertirlo in immagini e poi effettuare il riconoscimento. Se lo fate, vi consiglio una risoluzione di 200, che va bene anche per la stampa. A mio avviso 300 è esagerato, e crea file molto grandi. Alla fine vi basta salvare il documento PDF.
Note di installazione
Il programma si installa molto facilmente con Wine e nelle preferenze è possibile impostarlo in italiano e disattivare le voci PRO dal menu. Per effettuare l’OCR in italiano vi servirà il pacchetto di lingua addizionale, che trovate in questa pagina. L’unico problema è che a volte, con alcune versioni di Wine e (pare) di più nei sistemi a 64bit, il programma crasha quando si salva (seppure di solito il file viene salvato lo stesso). Per questo io vi consiglio di provare a installarlo con PlayOnLinux, nel quale potete testare diverse versioni di Wine e trovare un setup che per voi sia perfetto, anche se comunque non è obbligatorio farlo.
Se il vostro sistema operativo è a 64bit, potete anche risparmiare tempo e scaricare questo file .polApp [62 MB] che ho creato esportandolo da PlayOnLinux. Potete importarlo dal menu del programma, alla voce Plugins » PlayOnLinux Vault » Avanti » Restore an application. Contiene il programma impostato in italiano, i dizionari europei per l’OCR e il tema wooden per un aspetto migliore. A me funziona senza crashare, avendo impostato una versione vecchia di Wine (1.5.28).
Se invece usate Linux a 32bit e sperimentate i crash, provate anche la versione portable, alcuni asseriscono che funzioni meglio. Fatemi sapere se vi funziona e che ne pensate del programma!
Di recente la mia multifunzione HP si è rotta, ed ho dovuto procurarmi un’altra stampante con scanner integrato. Ho sempre apprezzato HP per il fatto che sviluppa driver ufficiali open source per Linux, rendendo l’utilizzo dei suoi prodotti veramente semplice (tralasciando la stampa su CD e cose del genere). Tuttavia, sappiamo bene che le cartucce di inchiostro HP hanno prezzi da usura e gli ultimi modelli implementano misure sempre più stringenti per contrastare le cartucce non ufficiali o ricaricate. No comment poi sul fatto che per cambiare un colore bisogna gettare tutta la cartuccia tricromatica.
Per questo motivo, ho ritenuto molto intelligente l’osservazione del negoziante che mi ha proposto di acquistare una multifunzione Brother: le cartucce costano poco e l’hardware funziona bene. Prima ho voluto informarmi, e dopo aver verificato che la stampante e lo scanner funzionano con Linux senza problemi anche in modalità wireless, ho optato per la Brother DCP-J140W.
La stampante in questione, qui mostrata con l’alloggiamento delle quattro cartucce aperto
Professional Printing Resolutions. Vivid, borderless photo printing up to 6000 x 1200.
4-Cartridge Ink System. Only replace the cartridge that needs to be replaced.
N-in-1 Printing and Copying. Helps save money by allowing you to print or copy multiple pages on one page.
Flatbed Copying and Scanning. Flatbed copier makes it convenient to copy bound, thick or odd sized documents.
A dire la verità, l’unico difetto è che i driver sono proprietari, perciò Ubuntu non li include e richiedono di essere installati manualmente. Di seguito vi spiegherò come fare per installare la stampante con una configurazione wireless, cioè connessa ad un router e accessibile da qualsiasi computer nella vostra rete domestica. È la configurazione più semplice da realizzare e anche più comoda da usare.
Collegamento wifi della stampante
Per prima cosa procuratevi dal Solutions Center della Brother la manualistica in italiano. In particolare usate la Guida di installazione rapida che vi spiegherà come collegare alla corrente il dispositivo, installare le cartucce e fare un test di stampa. Seguite i passi da 1 a 7, nelle prime sei pagine. La prima accensione della stampante è un processo leggermente lungo, in quanto effettua una pulizia approfondita, e richiede un paio di fogli di carta almeno.
A questo punto, potete iniziare la configurazione del wifi, tralasciando il “finto menefreghismo” di Brother che al passo 8 vi minaccia con affermazioni del tipo:
Queste istruzioni di installazione sono valide per Windows® XP Home/XP Professional x64 Edition, Windows Vista®, Windows® 7 e Mac OS X (versioni 10.5.8, 10.6.x e 10.7.x).
In realtà per attivare il collegamento wireless non dovrete neppure usare il vostro computer, e Brother stessa fornisce i driver anche per Linux. Per questo motivo, dirigetevi senza timore al passo 9 che si trova a pagina 13. Al passo 10, seguite l’opzione B — Configurazione manuale dal pannello di controllo — e assicuratevi di avere annotato il nome della vostra rete wireless e la relativa password. Saltate a pagina 19 e seguite quello che dice.
Quando siete arrivati alla dicitura «L’impostazione senza fili è completa» avete quasi terminato, l’ultima cosa da fare è segnarvi l’indirizzo IP assegnato alla stampante, perché vi servirà per lo scanner. Per farlo, premete Menu sulla stampante, poi scegliete 3. Rete » 1. TCP/IP » 2. Indirizzo IP. Verrà visualizzato qualcosa di simile a 192.168.001.181. Scrivetevelo elidendo gli zeri iniziali dei quattro numeri, per esempio il mio indirizzo diventa 192.168.1.181.
Installazione dei driver per la stampa e la scansione
Ora la stampante è attiva e pronta ad essere adoperata da qualsiasi computer collegato alla LAN. Bisogna però installare i driver sul computer per attivare la stampa e la scansione. Questa parte (per Linux) non è inclusa nel manuale di cui sopra, tuttavia il sito Brother ha una sezione apposita per i driver del pinguino, con pacchetti DEB e RPM.
Procuratevi i due pacchetti DEB presenti nella tabella dedicata alla DCP-J140W e salvateli e se usate Ubuntu a 64bit leggete i prerequisiti indicati qui. A questo punto dovreste essere in grado di installarli semplicemente facendoci doppio clic sopra, oppure da terminale con:
sudo dpkg -i dcp*.deb
Ora aprite l’interfaccia web di CUPS all’indirizzo http://localhost:631/printers e cliccate sulla stampante DCPJ140W. Poi cliccate sul menu a tendina Administration » Modify Printer. Se vi viene richiesto fate il login con i vostri username e password di Ubuntu. Dovreste impostare la stampante Brother che si trova alla voce Discovered Network Printers (potrebbe risultare duplicata) e poi premere su Continue.
Vi verrà presentata un’altra schermata dove potete cambiare alcuni parametri, se volete, e infine potete confermare. Quando vi chiede che driver utilizzare, lasciate la scelta impostata. Alla fine l’importante è che la stampante risulti come stampante di rete, con una posizione “simile” a dnssd://Brother%20DCP-J140W._pdl-datastream._tcp.local/.
Per quanto riguarda lo scanner, vi basta installare il pacchetto DEB di brscan4, stando attenti a scegliere quello giusto per il vostro sistema (32bit o 64bit). L’altro programma serve per scansionare automaticamente premendo il pulsante e salvare l’immagine su uno dei PC, ma non l’ho installato perché non mi serve e non fa parte del driver in sé.
Una volta che avrete installato il pacchetto di brscan4, usate il terminale per aggiungere il vostro scanner, avendo cura di usare l’indirizzo IP che avete precedentemente annotato, per esempio così:
brsaneconfig4 -a name=DCP-J140W model=DCP-J140W ip=192.168.1.181
A questo punto aprite un qualsiasi programma per scansionare e fate una prova.
Note finali
La procedura per i driver la potete ovviamente ripetere per i vari computer che avete. Sicuramente ci si mette meno tempo a farla che non a spiegarla e in pochi minuti tutto è funzionante. Anche se la stampa borderless a me non viene esattamente senza bordi (solitamente rimane un bordo di 1mm su qualche lato) devo dire che questa stampante è molto soddisfacente.
Considerando poi che online si trovano anche 10 cartucce a poco più di 10 euro, direi che il gioco vale la candela. Inoltre, esiste un trucco per allungare la vita delle cartucce!
Mi sono già lamentato numerose volte di quanto il sito Rai.tv sia un disastro di incoerenze multiple, in cui più o meno ogni video viene inserito con metodi leggermente diversi e trovare i link per scaricarli è un procedimento abbastanza arzigogolato. Due esempi di “inutile complicazione” che il mio script non riusciva a gestire sono i seguenti, dovuti al fatto che il sito Rai “dichiara” il tipo di video nella pagina, in modo totalmente a caso, a volte.
I video di «Chi l’ha visto», tipo questo — nel codice manca il riferimento al video in formato MP4, ma viene indicato doppiamente lo stesso URL al video, inclusa la variabile videourl_wmv, ed estensioneVideo e MediaItem.type sono impostate ad indicare il formato WMV… peccato che il video sia un file MP4
Questa puntata de «I migliori Anni» — è letteramente la fiera dell’incoerenza: MediaItem.type fa riferimento al formato WMV, estensioneVideo indica CSM ma il file è di tipo MP4
Ora, a parte il fatto che anche un ragazzino di 13 anni saprebbe sviluppare il sito in modo più coerente e sensato, capite bene che questa tragedia di informazioni contraddittorie creava serie difficoltà al mio script che cercava di capire che tipo di video c’era sotto e come gestirlo.
Oggi ho rianalizzato la questione e ho inserito ulteriori controlli per aggirare questi problemi. In particolare, se il sito fornisce un esplicito URL al file MP4 posso andare tranquillo, altrimenti in caso di “sospetto WMV” lo script prima controlla che questo sia coerente con il Content-type, dopodiché se è affermativo si occupa di verificare se è un vero file o uno stream MMS. Il controllo di coerenza dovrebbe impedire di cadere nella trappola delle false informazioni, e da quanto ho potuto testare è del tutto robusto.
Già che c’ero, ho aggiornato lo script per gestire altri casi di video (ormai alla Rai non sanno più cosa inventarsi), come ad esempio questa puntata del «Maurizio Costanzo Talk». Ho trovato questo video guardando gli esempi dal piccolo web-service di Paolo Pancaldi, che fa più o meno le stesse cose del mio script (tranne Rai Replay e la riproduzione con player nativo) ma in “stile lato server”, perciò un grazie a Paolo per avermelo fatto scoprire.
Se avete già lo script e volete aggiornare manualmente oppure se volete installarlo da zero, trovate tutti i dettagli nel mio post apposito.