Da alcuni mesi, moltissimi sviluppatori Python si stanno spostando verso l’utilizzo di uv, un gestore di pacchetti estremamente veloce che sostituisce strumenti come pip, pipx, poetry, pyenv, virtualenv e non solo.
Oltre al fattore della velocità, i vantaggi di uv si vedono nel lavoro quotidiano. Questo programma rende semplicissimo gestire più versioni di Python, il virtual environment per il progetto, il tracciamento delle dipendenze multipiattaforma e l’installazione di comandi da usare con il terminale. Il Python Developer Tooling Handbook contiene una guida molto ben fatta su come iniziare a usare uv, nonché un tutorial che spiega come usarlo per pubblicare un pacchetto Python.
Talvolta succede di voler usare una versione per Windows di Python anche su Linux, cosa che solitamente viene fatta in modo “manuale” con l’ausilio di Wine. L’esempio più comune è la necessità di compilare un file eseguibile (exe) con PyInstaller, per poi distribuirlo a dei client Windows.
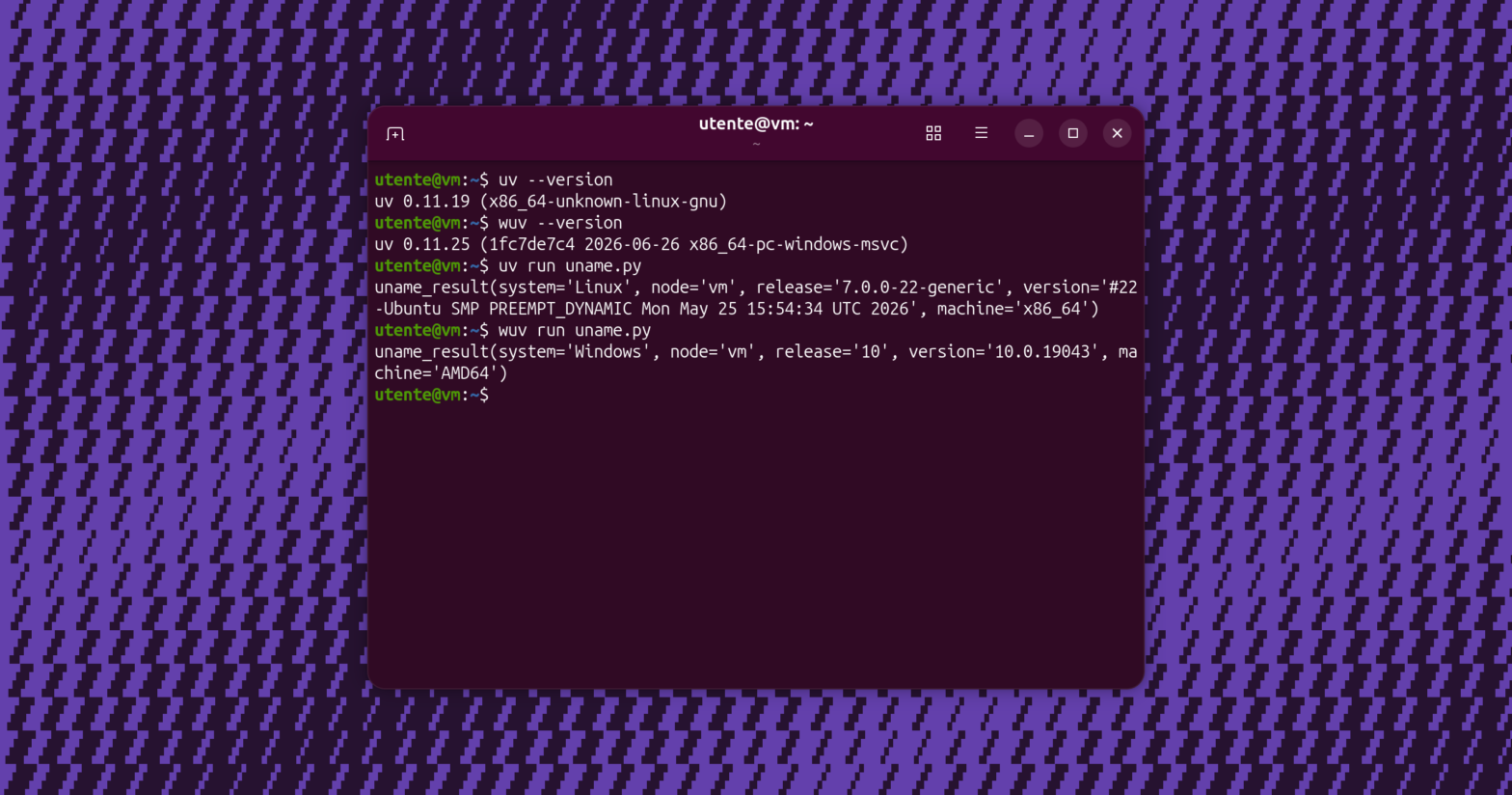
Il fatto che uv nasconda tutta la complessità di gestire le dipendenze e le diverse versioni di Python dietro un singolo comando fa davvero gola, quindi volevo ottenere un risultato analogo anche in presenza di Wine. Per questo ho pubblicato uv-wine, cioè un insieme di script per impostare la propria macchina Linux di sviluppo. Dopo l’installazione si ottengono due nuovi comandi: wuv e wuvx.
Lo script richiede di avere già installato uv per Linux, e di avere a disposizione Wine e Wget, oltre a Git. L’installazione è semplicissima: dopo aver clonato il repository, basta lanciare l’apposito script:
git clone https://github.com/Lazza/uv-wine
cd uv-wine
./setup-uv-wine.shVerrà creato un prefisso pulito per Wine dentro a $HOME/.winepython, con una installazione di Python 3.12 e uv. I due nuovi script saranno collocati nel percorso $HOME/.local/bin/.
Per usare uv sotto Wine nel proprio progetto, sarà sufficiente sostituire il comando uv con wuv, per esempio lanciando PyInstaller in questo modo:
wuv sync
wuv run pyinstaller --onefile main.pyPer evitare conflitti, il virtual environment così gestito viene collocato nel percorso nascosto .winenv invece del solito .venv.
Infine, segnalo che l’uso di Python sotto Wine può causare problemi nel caso di librerie che comprendono codice nativo. Per esempio potreste osservare errori legati a ucrtbase.dll. Non si tratta di un problema di uv né dei miei script, bensì della compatibilità di alcune dipendenze con Wine.
A volte il downgrade può risolvere il problema (quando è agevole farlo). Per fare una prova, potete sperimentare che la versione 2.5.0 di Numpy scatena l’errore, mentre la versione 2.2.0 no. Tenetelo a mente!