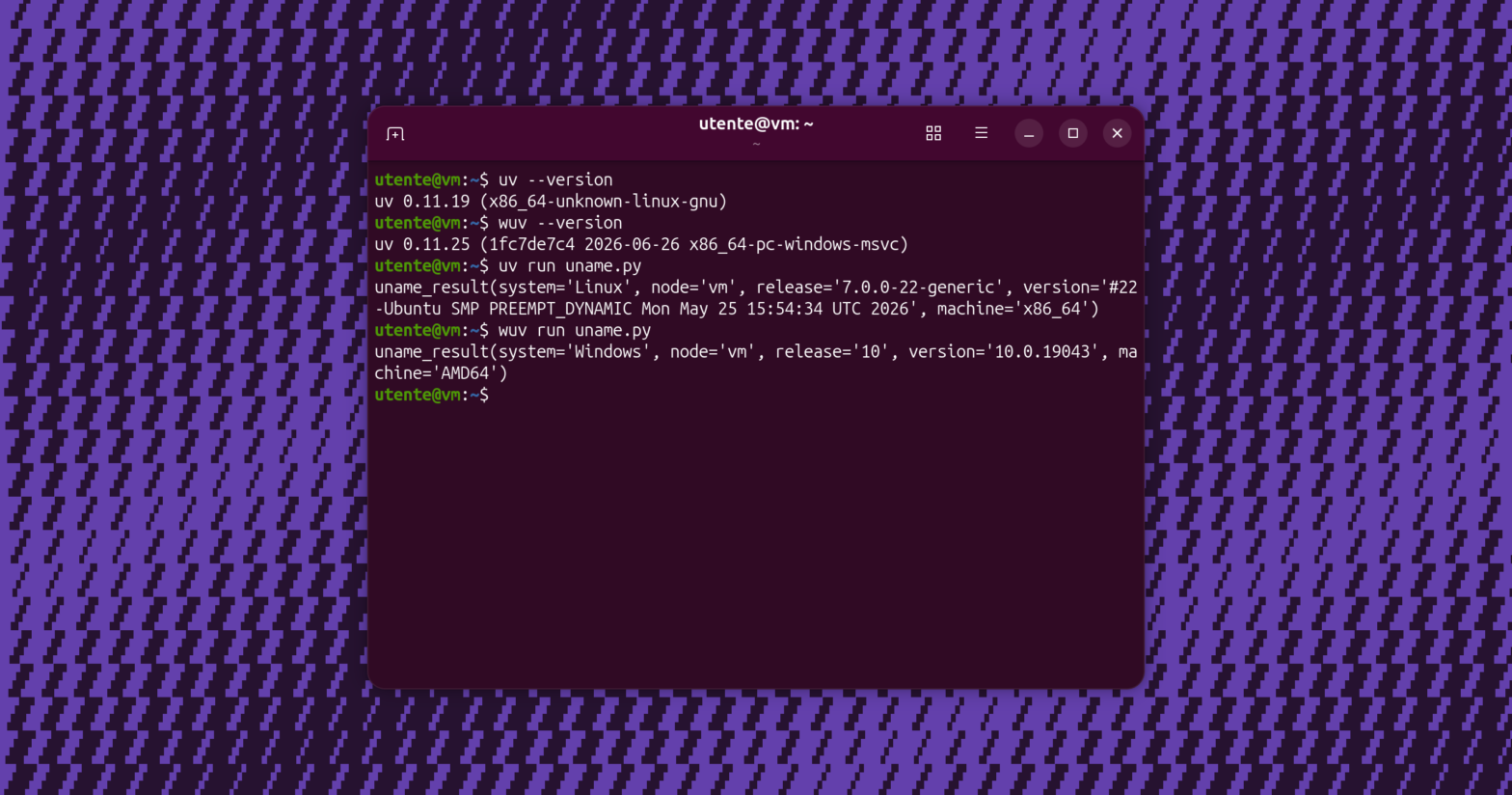
Da alcuni mesi, moltissimi sviluppatori Python si stanno spostando verso l’utilizzo di uv, un gestore di pacchetti estremamente veloce che sostituisce strumenti come pip, pipx, poetry, pyenv, virtualenv e non solo. Oltre al fattore della velocità, i vantaggi di uv si vedono nel lavoro quotidiano. Questo programma rende semplicissimo gestire più versioni di Python, ilContinua a leggere “Creare eseguibili Windows da Linux con PyInstaller e uv”
Archivi della categoria: Linux
Strumenti open-source per l’informatica forense al Linux Day 2025 di Vicenza

Anche quest’anno a ottobre si svolgerà il Linux Day, la principale iniziativa italiana per conoscere e approfondire Linux e il software libero. Dal 2001 in tutta Italia si possono trovare vari eventi locali con talk, workshop, spazi per l’assistenza tecnica e dimostrazioni pratiche di software e hardware libero. Quest’anno la giornata sarà dedicata alla privacy,Continua a leggere “Strumenti open-source per l’informatica forense al Linux Day 2025 di Vicenza”
Registrare i video di Rai Play usando Stacher

Da qualche giorno diversi utilizzatori del mio script per scaricare i video da Rai Play mi stanno segnalando che si riscontrano difficoltà nel salvare i video in formato MP4, in particolare in quanto compare un messaggio di errore. A questo punto è necessaria una piccola parentesi tecnica per capire cosa sta succedendo: lo script funzionaContinua a leggere “Registrare i video di Rai Play usando Stacher”
Adeguare un sito WordPress al GDPR in pochi semplici passaggi

La serie di serate divulgative, gratuite e aperte a tutti del LUG di Vicenza continua fino a fine mese. Il 20 giugno terrò un intervento dedicato agli adeguamenti necessari per poter pubblicare un sito web con WordPress in modo che sia rispettoso del GDPR e della privacy degli utilizzatori: WordPress è il gestore di contenutiContinua a leggere “Adeguare un sito WordPress al GDPR in pochi semplici passaggi”
Tutelare la propria privacy senza sforzo con i frontend alternativi

Anche per l’anno 2023 il LUG di Vicenza sta organizzando una fitta serie di serate divulgative, gratuite e aperte a tutti. Il 28 marzo terrò un intervento dedicato a una navigazione maggiormente consapevole, per fruire dei nostri contenuti preferiti ma con un occhio di riguardo alla tutela dei nostri dati personali, riducendo la profilazione eContinua a leggere “Tutelare la propria privacy senza sforzo con i frontend alternativi”
Il codice sorgente di YouTube-dl è stato rimosso da GitHub, ma gli utenti del web non l’hanno presa benissimo

Chi di voi si interessa al salvataggio dei contenuti audio/video dai siti web avrà sicuramente già sentito parlare di YouTube-dl. Si tratta di un software completamente open source, rilasciato addirittura nel pubblico dominio, che nel sito ufficiale è presentato in modo molto semplice: YouTube-dl è un programma a riga di comando per scaricare video daContinua a leggere “Il codice sorgente di YouTube-dl è stato rimosso da GitHub, ma gli utenti del web non l’hanno presa benissimo”
La tua prima app Android e iOS con Ionic Framework
Chi mi segue abitualmente già lo sa, da tempo partecipo come relatore a ESC, un incontro non-profit di persone interessate al Software e Hardware Libero, all’Hacking e al DIY che si svolge a fine estate presso Forte Bazzera, vicino a Venezia. Nel 2016 ho parlato di ricostruzione forense di NTFS, nel 2017 di Gimp eContinua a leggere “La tua prima app Android e iOS con Ionic Framework”
Introduzione all’intelligenza artificiale — Video del talk

Il 26 ottobre ho partecipato come relatore al Linux Day 2019 organizzato dal Gruppo Utenti GNU/Linux di Vicenza. Il filo conduttore di quest’anno era l’intelligenza artificiale e i video dei vari interventi sono stati poi pubblicati anche su YouTube. Il mio intervento aveva un carattere piuttosto introduttivo, con lo scopo di presentare una panoramica dellaContinua a leggere “Introduzione all’intelligenza artificiale — Video del talk”
Scaricare i video da Rai Play — L’ultimissimo script

Chi segue questo blog da un po’ di tempo sa che nel 2010 avevo pubblicato il mio primo script per salvare i video dal portale Rai, proseguendo poi nel 2012 con un secondo script rinnovato. Erano tempi bui, in cui gli utenti Linux non potevano neppure vedere facilmente i programmi per via di Silverlight. LoContinua a leggere “Scaricare i video da Rai Play — L’ultimissimo script”
Abel, il sistema di build della nuova CAINE — Video e slide

Il team di ESC ha fatto come sempre uno straordinario lavoro con i video dei talk, che trovate nel canale YouTube ufficiale (alcuni sono ancora in fase di montaggio). Il mio intervento verteva sul lavoro svolto per una delle principali distribuzioni Linux in ambito di informatica forense: Abel, il sistema di build della nuova CAINEContinua a leggere “Abel, il sistema di build della nuova CAINE — Video e slide”
