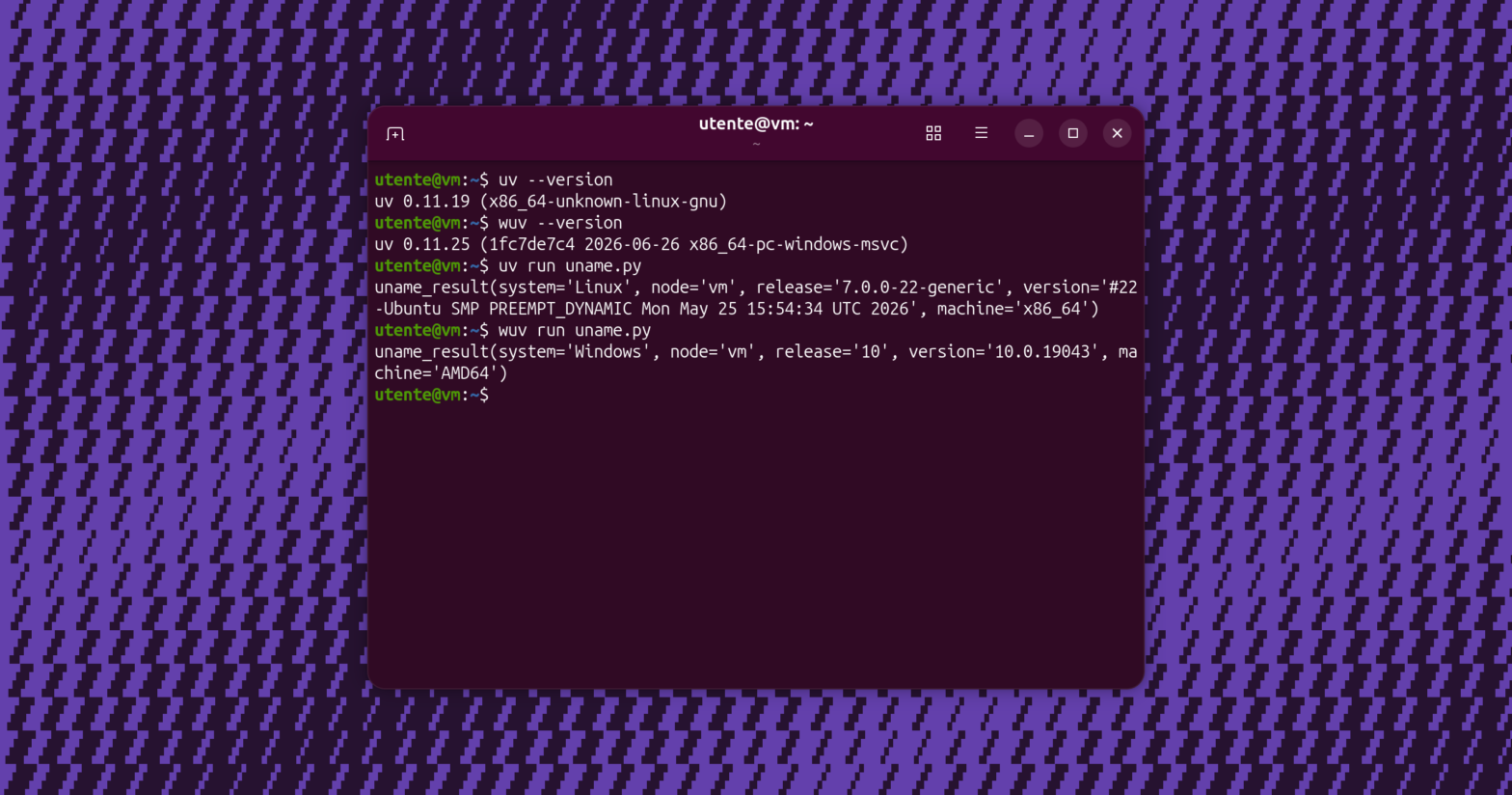
Da alcuni mesi, moltissimi sviluppatori Python si stanno spostando verso l’utilizzo di uv, un gestore di pacchetti estremamente veloce che sostituisce strumenti come pip, pipx, poetry, pyenv, virtualenv e non solo. Oltre al fattore della velocità, i vantaggi di uv si vedono nel lavoro quotidiano. Questo programma rende semplicissimo gestire più versioni di Python, ilContinua a leggere “Creare eseguibili Windows da Linux con PyInstaller e uv”
Archivi dell'autore:Lazza
Tre webinar sull’informatica forense, organizzati da ONIF

ONIF (Osservatorio Nazionale Informatica Forense) ha recentemente lanciato il progetto Digital Forensics Talks, una nuova serie di webinar divulgativi interamente dedicati al mondo delle indagini digitali. Attraverso incontri online con professionisti ed esperti del settore, l’iniziativa ha l’obiettivo di creare uno spazio di confronto e aggiornamento accessibile gratuitamente a professionisti, studenti e appassionati. Il programmaContinua a leggere “Tre webinar sull’informatica forense, organizzati da ONIF”
Un webinar gratuito sull’acquisizione forense dei Mac

Ho il piacere di informarvi che sono stato invitato dal gruppo Digital Forensics IT Community a tenere un webinar sul progetto Fuji e l’acquisizione forense dei Mac. La serata è programmata per il 24 marzo 2026 alle ore 19:00, e si intitola “Dalla copia live alla Fuji Cartridge: la nuova frontiera dell’acquisizione forense dei Mac”.Continua a leggere “Un webinar gratuito sull’acquisizione forense dei Mac”
“Open-Source Tools for Digital Forensics” presso MSAB Digital Summit 2026

Il 10 marzo inizierà l’evento MSAB Mobile Forensics Digital Summit, dedicato all’analisi forense dei dispositivi mobili e non solo. L’iniziativa si svolgerà interamente online e durerà ben tre giorni. Il programma è davvero ricco, con interessanti contenuti proposti da esperti internazionali sia del settore pubblico che di quello privato. Inoltre, sono felice di comunicare che sono statoContinua a leggere ““Open-Source Tools for Digital Forensics” presso MSAB Digital Summit 2026″
Fuji 1.2.0 permette l’acquisizione forense dei Mac anche in recovery mode

L’inizio del 2026 è stato un periodo di forte sviluppo per Fuji, il mio programma open-source per l’acquisizione forense di macOS. Dopo alcuni mesi di poca attività, ho ricominciato un intenso lavoro per includere nuove funzioni, correzioni di bug e miglioramenti generali. Sono davvero soddisfatto del risultato ottenuto e i vari commenti ricevuti, anche daContinua a leggere “Fuji 1.2.0 permette l’acquisizione forense dei Mac anche in recovery mode”
Come estrarre i dati da una copia forense XRY per elaborarli con altri software di analisi

XRY è un formato di file utilizzato per le copie forensi dall’omonimo software di acquisizione di dati da smartphone, nonché dalla suite di analisi XAMN. Entrambi i programmi sono sviluppati da MSAB, una multinazionale svedese che opera nel settore dell’informatica forense, per la quale sono stato relatore in alcuni workshop. Il formato XRY presenta alcuniContinua a leggere “Come estrarre i dati da una copia forense XRY per elaborarli con altri software di analisi”
Fuji: la soluzione open-source per la copia forense dei Mac con processori Intel e Apple Silicon

Il 15 novembre 2025 si svolgerà HackInBo® Classic Edition Winter 2025, cioè la venticinquesima edizione della più attesa conferenza italiana su sicurezza informatica e hacking, che ogni anno attira migliaia di partecipanti da tutta la penisola. Il programma è ricco di temi interessanti e io sarò impegnato con la realizzazione di un intervento interamente dedicatoContinua a leggere “Fuji: la soluzione open-source per la copia forense dei Mac con processori Intel e Apple Silicon”
Strumenti open-source per l’informatica forense al Linux Day 2025 di Vicenza

Anche quest’anno a ottobre si svolgerà il Linux Day, la principale iniziativa italiana per conoscere e approfondire Linux e il software libero. Dal 2001 in tutta Italia si possono trovare vari eventi locali con talk, workshop, spazi per l’assistenza tecnica e dimostrazioni pratiche di software e hardware libero. Quest’anno la giornata sarà dedicata alla privacy,Continua a leggere “Strumenti open-source per l’informatica forense al Linux Day 2025 di Vicenza”
“Home Automation and IoT as a Source of Evidence” presso il SANS DFIR Europe Summit Prague 2025

Il 28 settembre 2025 a Praga (Repubblica Ceca) si svolgerà l’annuale edizione del SANS DFIR Europe Summit, uno dei più importanti eventi a livello europeo nel settore dell’informatica forense. Il programma è davvero folto e ben cinque delle tredici presentazioni saranno tenute da professionisti italiani! Sono lieto di comunicare che, per il secondo anno di fila, sono stato selezionatoContinua a leggere ““Home Automation and IoT as a Source of Evidence” presso il SANS DFIR Europe Summit Prague 2025″
Una possibilità per aggirare la modalità “antifurto” di ESET Mobile Security per Android

In veste di consulente informatico forense, spesso mi confronto con i colleghi su come affrontare inconvenienti tecnici nelle attività lavorative. Questo articolo è il risultato di uno di questi scambi. Un amico mi ha contattato perché, in un’indagine, si trovava a dover acquisire uno smartphone Android che risultava bloccato dalla funzione antifurto di ESET MobileContinua a leggere “Una possibilità per aggirare la modalità “antifurto” di ESET Mobile Security per Android”
