
Consulenza informatica forense a privati, avvocati e studi legali per affrontare positivamente i casi che coinvolgono reati informatici e prove digitali.
Ottieni risposte chiare, comprensibili e scientificamente accurate
Trasforma documenti, chat e tracce digitali in elementi solidi per difendere i tuoi interessi
Attività che svolgo

Informatica forense
Consulenza specializzata in digital forensics, in ambito aziendale e giudiziario.

Sviluppo software
Applicazioni per Android e iOS, siti web, portali e-commerce e software personalizzato.

Consulenza informatica
Supporto a privati e aziende, recupero dati e bonifica di siti web compromessi.

Ciao, sono Andrea
Sono un consulente informatico forense e sviluppatore software. Assisto i miei clienti quando sono coinvolte prove informatiche nei procedimenti civili e penali.
Quindi, se hai a che fare con documenti cancellati da recuperare, contenuti pubblicati su Facebook, scambi di email o comunicazioni su WhatsApp da documentare per motivi legali sei nel posto giusto.
Con il mio supporto potrai ottenere degli elementi concreti e validi anche in tribunale. Ho aiutato numerosi clienti a ottenere giustizia e far valere le proprie ragioni.
Ultimi articoli
- Creare eseguibili Windows da Linux con PyInstaller e uv
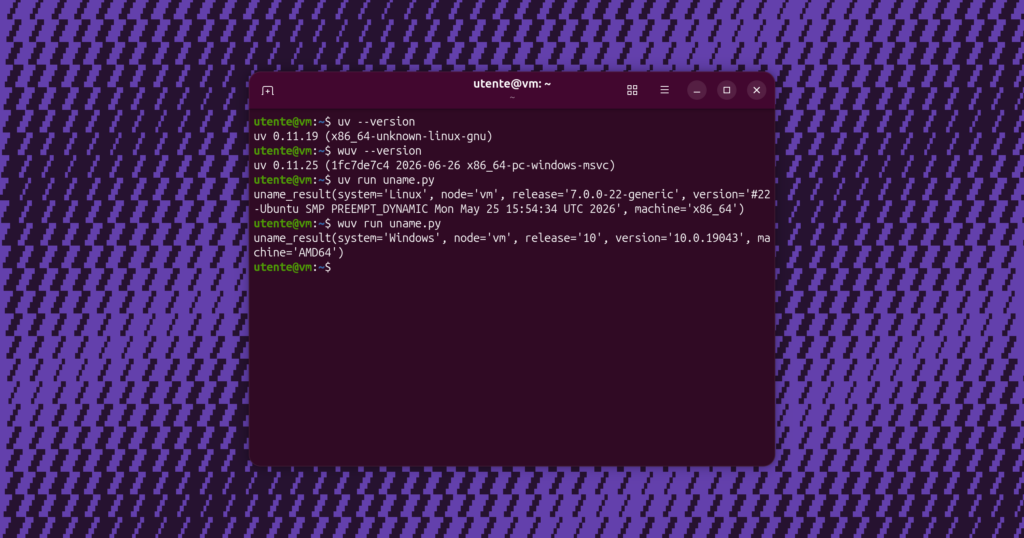 Da alcuni mesi, moltissimi sviluppatori Python si stanno spostando verso l’utilizzo di uv, un gestore di pacchetti estremamente veloce che sostituisce strumenti come pip, pipx, poetry, pyenv, virtualenv e non solo. Oltre al fattore della velocità, i vantaggi di uvContinua a leggere “Creare eseguibili Windows da Linux con PyInstaller e uv”
Da alcuni mesi, moltissimi sviluppatori Python si stanno spostando verso l’utilizzo di uv, un gestore di pacchetti estremamente veloce che sostituisce strumenti come pip, pipx, poetry, pyenv, virtualenv e non solo. Oltre al fattore della velocità, i vantaggi di uvContinua a leggere “Creare eseguibili Windows da Linux con PyInstaller e uv” - Tre webinar sull’informatica forense, organizzati da ONIF
 ONIF (Osservatorio Nazionale Informatica Forense) ha recentemente lanciato il progetto Digital Forensics Talks, una nuova serie di webinar divulgativi interamente dedicati al mondo delle indagini digitali. Attraverso incontri online con professionisti ed esperti del settore, l’iniziativa ha l’obiettivo di creareContinua a leggere “Tre webinar sull’informatica forense, organizzati da ONIF”
ONIF (Osservatorio Nazionale Informatica Forense) ha recentemente lanciato il progetto Digital Forensics Talks, una nuova serie di webinar divulgativi interamente dedicati al mondo delle indagini digitali. Attraverso incontri online con professionisti ed esperti del settore, l’iniziativa ha l’obiettivo di creareContinua a leggere “Tre webinar sull’informatica forense, organizzati da ONIF” - Un webinar gratuito sull’acquisizione forense dei Mac
 Ho il piacere di informarvi che sono stato invitato dal gruppo Digital Forensics IT Community a tenere un webinar sul progetto Fuji e l’acquisizione forense dei Mac. La serata è programmata per il 24 marzo 2026 alle ore 19:00, eContinua a leggere “Un webinar gratuito sull’acquisizione forense dei Mac”
Ho il piacere di informarvi che sono stato invitato dal gruppo Digital Forensics IT Community a tenere un webinar sul progetto Fuji e l’acquisizione forense dei Mac. La serata è programmata per il 24 marzo 2026 alle ore 19:00, eContinua a leggere “Un webinar gratuito sull’acquisizione forense dei Mac”
Dicono di me
Complimenti. Dopo tante esperienze con i consulenti, finalmente leggo una relazione comprensibile ai “non tecnici”.
Avvocato, Treviso
Ti ringrazio per l’ottimo lavoro svolto. Il documento è conciso, chiaro, e risponde esattamente ai nostri dubbi.
Investigatore privato, Vicenza
Mi piacerebbe approfondire il tuo caso o il progetto che vuoi sviluppare.
