Le emoji sono le famose faccine nate originariamente in Giappone parecchi anni fa, e portate più recentemente al successo da applicazioni mobili come Whatsapp, Facebook Messenger e Google Hangouts.
Praticamente chiunque possieda uno smartphone avrà usato almeno una volta la faccina sorridente ☺, il pollice in su 👍 o, perché no, anche la “cacchetta” 💩. 😛 Tutto ciò è reso possibile dal fatto che questi simboli fanno parte di un vero e proprio standard, ovvero sono contenute nella versione 6.0 dello standard Unicode.
Ciò ha una conseguenza positiva: è stato stabilito un linguaggio universale, esattamente come con le normali lettere dell’alfabeto, e ciò permette a tutti i software e sistemi operativi di poter riconoscere tali simboli.
Ovviamente Linux non è da meno, tuttavia nell’installazione predefinita di Ubuntu e altre distribuzioni non è presente un metodo semplice per scrivere questi simboli. Inoltre, a volte manca anche il font per visualizzarle. Vediamo come porre rimedio a tutto ciò. 🙂
Partiamo dalla visualizzazione. Esiste un carattere chiamato Symbola che contiene tutte le icone. Su Ubuntu si può installare tramite il pacchetto ttf-ancient-fonts, se usate altre distribuzioni verificate voi il nome del pacchetto. 🙂
Fatto ciò, dovreste essere in grado di visualizzare le emoji sulla pagina di Wikipedia (potrebbe richiedere un riavvio del browser). Ora è il momento di abilitare l’inserimento semplificato delle icone, vale a dire la possibilità di digitarle senza copiarle dalla tabella caratteri. Ciò che otterrete alla fine sarà un menu di questo tipo:
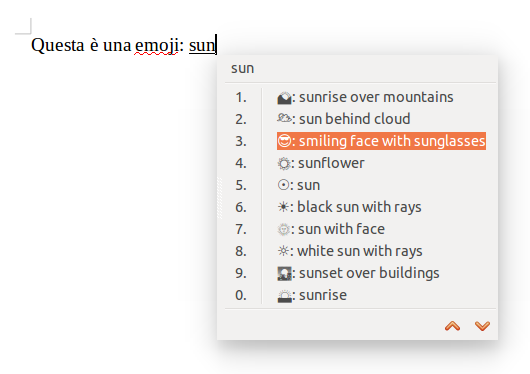
Come vedete nella figura, digitando un pezzettino della descrizione dell’emoji desiderata (in questo caso l’inizio della parola sunglasses), appare un menu che consente di scegliere la faccina voluta: 😎
In molte distribuzioni, avrete notato che sulla taskbar avete un menu a tendina che consente di cambiare la tastiera (per esempio da Italiana a Americana), questo è reso possibile grazie al software IBus. Di seguito vi spiegherò come aggiungere un’altra “lingua” tra quelle disponibili, ovvero UniEmoji.
Innanzitutto bisogna scaricare il codice, magari in una cartella temporanea, e poi scompattarlo. I comandi da dare nel terminale sono i seguenti:
cd /tmp wget https://github.com/lalomartins/ibus-uniemoji/archive/master.zip unzip master.zip cd ibus-uniemoji-master
L’ultimo comando vi fa spostare nella directory corretta.
A questo punto dovete installare il pacchetto checkinstall, che vi consiglio perché permette una eventuale disinstallazione in modo assai pulito. Su Ubuntu basta fare:
sudo apt-get install checkinstall
Ora potete procedere alla compilazione del pacchetto:
sudo checkinstall
Appariranno delle domande. La prima recita Should I create a default set of package docs? [y] e voi dovrete premere semplicemente Invio. La seconda vi invita a inserire una descrizione al cursore >>, premete sempre Invio. La terza vi mostrerà un riepilogo dei dati del pacchetto, tra cui:
[...] 2 - Name: [ ibus-uniemoji ] 3 - Version: [ master ] 4 - Release: [ 1 ] 5 - License: [ GPL ] [...]
Voi dovete premere 3 per modificare la versione. Quando vi chiede di inserirne una nuova, scrivete semplicemente 1 e premete Invio. Premete nuovamente Invio al successivo riepilogo, e attendete. Presto vedrete un messaggio che inizia per:
Done. The new package has been installed and saved to [...]
Ora è quasi fatta! 🙂 L’icona predefinita di UniEmoji è bruttina, pertanto vi consiglio di rimpiazzarla con un bello smile sorridente. Per fare questo, andremo a modificare un file del programma, col seguente comando:
sudo sed -si "s/\/usr.*svg/\/usr\/share\/icons\/Humanity\/emblems\/48\/emblem-cool.svg/g" /usr/share/ibus/component/uniemoji.xml
A questo punto dovete terminare la sessione, e poi entrare di nuovo col vostro account utente. Cliccate sull’icona della taskbar dove normalmente scegliete la lingua della tastiera e andate su Impostazioni inserimento testo. Quest’ultima è la voce che si trova su Ubuntu, ma immagino che altre distribuzioni abbiano nomi simili, eventualmente guardate nelle preferenze di sistema. 😉
Premete il tastino + per aggiungere un nuovo metodo, e cercate UniEmoji. Cliccate su Aggiungi e verrà inserito nella lista. Vi consiglio di metterlo appena sotto al metodo che usate di solito, poi spiego perché.
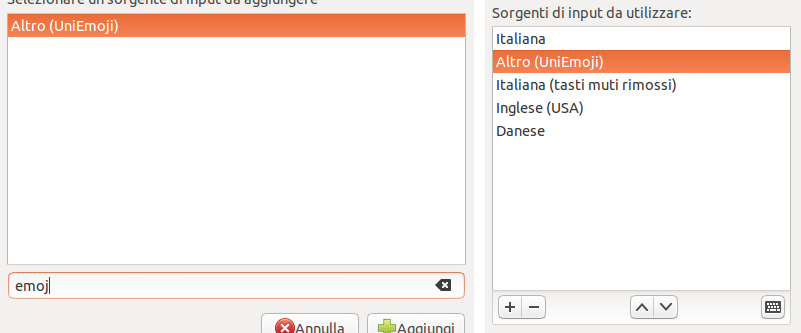
A questo punto avete terminato i passi necessari! 😉
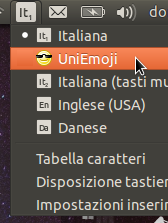
Quando volete inserire una emoji, vi basta cliccare sul menu a tendina e selezionare UniEmoji. Dopidiché, iniziate a digitare una parola chiave che descrive l’emoji (in inglese) e il menu suggerirà quelle corrispondenti. Potete trovare le descrizioni di tutte le faccine su Emojipedia.
Poche righe sopra vi ho consigliato di inserire UniEmoji al secondo posto. Il motivo è presto detto: IBus permette di cambiare metodo di inserimento tramite la combinazione Windows + Spazio, passando alla successiva. Shift + Windows + Spazio invece permette di tornare alla precedente.
Ciò significa che quando volete inserire una emoji, potete digitare la prima combinazione ed attivare subito UniEmoji. Alla fine, potete premere la seconda combinazione e tornare alla lingua che usate di solito. 🙂