L’Optical Character Recognition è il famoso processo per cui un software analizza una immagine di un testo (solitamente stampato) e tenta di effettuarne la conversione in un documento modificabile. Questo può essere sia un semplice file di testo che una pagina formattata, dipende dal software. Sotto piattaforma Linux esistono diversi strumenti molto validi per questo “lavoro”, a cui si aggiungono alcuni siti web che svolgono questo compito. Tuttavia, io desideravo in particolare effettuare una operazione che sta diventando sempre più popolare, ovvero il cosiddetto PDF sandwich. Ci possono essere due situazioni in cui potete trovarvi ad avere questa necessità:
- Possedete un PDF di pagine scansionate, magari a partire da immagini belle pulite e ottimizzate con ScanTailor.
- Avete un PDF di un articolo scientifico compilato con LaTeX, quindi sembra che ci sia il “testo vero” ma in realtà se provate a fare copia incolla (o una ricerca) tutto quello che viene fuori sono caratteri apparentemente privi di senso. Un esempio è questo paper, tra quelli che devo leggere per la mia tesi.
In entrambi i casi, il vostro scopo è ottenere un documento il cui aspetto esteriore sia lo stesso (quindi mantenendo le immagini) ma che sia ricercabile. Ciò viene realizzato da software appositi che creano un livello trasparente con del “vero testo” usando le tecniche OCR. Il risultato non sempre è perfetto, ma sicuramente è molto meglio di avere documenti totalmente non ricercabili. Ci sono alcune guide e script in merito, nonché un live CD nato per fare solo questo.
Tuttavia sono tutte tecniche basate sullo stesso principio: usano Tesseract oppure Cuneiform per creare un file hocr e poi hocr2pdf per creare il risultato finale. Io ho provato personalmente numerosi tutorial e programmi ma il problema è sempre lo stesso: il testo sovraimposto è spesso di dimensioni sbagliate, un po’ a casaccio, e a volte è completamente spostato rispetto alle parole visualizzate. Insomma, il risultato è indegno.
La soluzione funzionante
Alla fine mi sono arreso e ho optato per un software per Windows tramite Wine, in particolare PDF-Xchange Viewer. È un programma che nella versione a pagamento fa un sacco di cose che a me non servono, ma la versione gratuita ha un motore OCR niente male che allinea il testo precisamente e riconosce le colonne abbastanza bene.
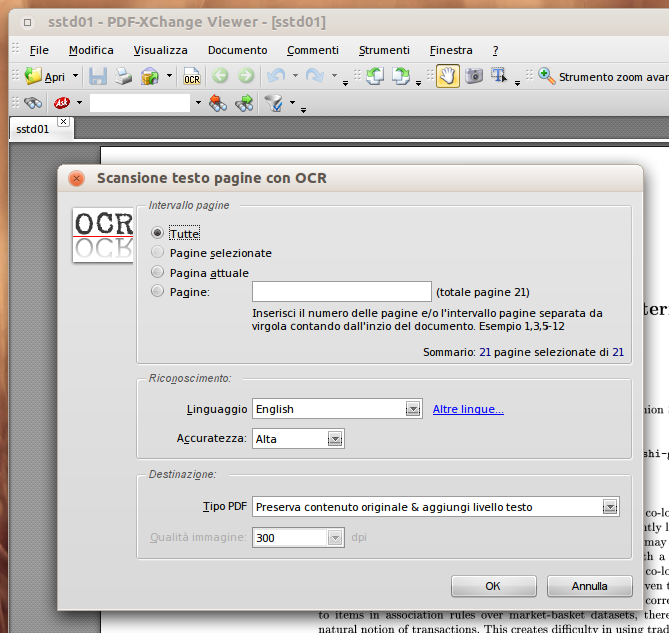
La finestra di riconoscimento è molto semplice da usare e consente di scegliere la lingua e il tipo di PDF. Se il vostro PDF contiene già immagini scegliete la prima voce, ovvero Preserva contenuto originale & aggiungi livello testo. Se invece è un PDF con “falso testo” l’altra opzione vi consente di convertirlo in immagini e poi effettuare il riconoscimento. Se lo fate, vi consiglio una risoluzione di 200, che va bene anche per la stampa. A mio avviso 300 è esagerato, e crea file molto grandi. Alla fine vi basta salvare il documento PDF.
Note di installazione
Il programma si installa molto facilmente con Wine e nelle preferenze è possibile impostarlo in italiano e disattivare le voci PRO dal menu. Per effettuare l’OCR in italiano vi servirà il pacchetto di lingua addizionale, che trovate in questa pagina. L’unico problema è che a volte, con alcune versioni di Wine e (pare) di più nei sistemi a 64bit, il programma crasha quando si salva (seppure di solito il file viene salvato lo stesso). Per questo io vi consiglio di provare a installarlo con PlayOnLinux, nel quale potete testare diverse versioni di Wine e trovare un setup che per voi sia perfetto, anche se comunque non è obbligatorio farlo.
Se il vostro sistema operativo è a 64bit, potete anche risparmiare tempo e scaricare questo file .polApp [62 MB] che ho creato esportandolo da PlayOnLinux. Potete importarlo dal menu del programma, alla voce Plugins » PlayOnLinux Vault » Avanti » Restore an application. Contiene il programma impostato in italiano, i dizionari europei per l’OCR e il tema wooden per un aspetto migliore. A me funziona senza crashare, avendo impostato una versione vecchia di Wine (1.5.28).
Se invece usate Linux a 32bit e sperimentate i crash, provate anche la versione portable, alcuni asseriscono che funzioni meglio. Fatemi sapere se vi funziona e che ne pensate del programma!

Ti segnalo questo software (ma sicuramente lo conoscerai già): si chiama gImageReader è funziona egregiamente senza wine
lo trovi qui:
http://sourceforge.net/projects/gimagereader/
Sembra molto simile a gScan2PDF! 🙂 Però da quel che ho capito non fa il “PDF sandwich”, giusto?
sì giusto; il “PDF sandwitch” non sapevo nemmeno cosa fosse l’ho appreso in questo tuo post (io non sono bravo come te, non ho formazione specifica, cerco solo di imparare ciò che mi serve e il tuo blog è una delle mie fonti anche se spesso leggo cose troppo difficili per il mio livello).
Quanto a gImageReader è un software molto semplice, si basa su tesseract di cui è una mera interfaccia graica (scarna ed essenziale), però, se devi semplicemente trasformare l’immagine di un docuemnto in testo funziona piuttosto bene: hai a disposizione una specie di taglierina con cui selezioni la porzione di testo che ti interessa (magari ti interessa tutta la pagina o magari solo un trafiletto, mi spiego?) e lui te la converte.
È un programma leggero, lo uso da qualche anno con soddisfazione; risponde alle mie esigenze (e non mi costringe a installare wine che ho sempre visto con timore, non so perché, non ho un motivo razionale).
No ma infatti sono d’accordo, se ti basta una GUI a Tesseract molto meglio usare un software open source e nativo, anch’io faccio così. 🙂 Il mio post nasceva appunto solo per il discorso di fare un OCR sopra al PDF.
Ecco, ‘sta cosa mi preoccupa un po’. 😀 Cerco sempre di scrivere in modo comprensibile, se trovi dei passaggi poco chiari lasciami pure un commento e io ti risponderò. 😛
No, guarda, tu sei molto chiaro quando scrivi; in realtà mi sono espresso male io: ti faccio un esempio: ho letto il post relativo alla creazione di una fotografia con immagini multiple dello stesso soggetto: è interessantissimo e scritto bene, ma non credo che riuscirei a rifarlo e non mi ci metto nemmeno (per mancanza di tempo e forse anche per pigrizia); il risultato è che il tuo post è un po’ troppo “oltre” il mio livello.
Spero di essermi spiegato meglio
Aggiungo che ho timore di impantanare il pc: in passato mi sono accorto che più roba ci installo, più impostazioni ci cambio e più iniziano a emergere problemi che poi io, non avendo la tua compentenza, non so risolvere e allora sono costretto a reinstallare tutto…
Come dicevo, mi limito a usare il pc per quello che mi serve, sopprimendo la tentazione di smanettare, scavare, impostare, cambiare, provare…
Mi accontento, ed è già una gran goduria, che col passare del tempo il pc non rallenta, non si pianta, non prende virus, su Internet vola
All’inizio (era il 2009), quando, per disperazione, provai Linux (Karmic Koala), non potevo crederci: ogni giorno accendevo la macchina aspettando il rallentamento a cui Windows mi aveva assuefatto, e invece…
Be’ in effetti richiede implicitamente che uno abbia già usato Gimp qualche volta. Però insomma dai, se ti interessa provalo! Non è detto che non venga. 😉 Concordo anche io che a volte sia meglio non smanettare troppo, specialmente quando le cose già funzionano, eh eh. 🙂
«meglio non smanettare troppo»
proprio così
e per smentire immediatamente il principio su cui abbiamo or ora concordato entrambi, ti dico che ho appena installato Scantailor (non ho resistito eh eh), programma che ho conosciuto grazie al tuo post e che potrà certamente servirmi
adesso sto cercando di apprenderne un po’ il funzionamento (non è il massimo della intuitività)
come vedi, quel che posso, lo prendo 🙂
grazie di tutto
Eh già, la schermata iniziale è un po’ incasinata. Però se imposti i DPI delle immagini scansionate, le schermate successive sono molto pratiche (passo passo, numerate) e hanno il pulsantino che fa le cose automatiche per ciascuno step. Se qualcosa non va, correggi a mano. Alla fine, ti trovi le scansioni ottimizzate in una cartella che avevi specificato, e puoi farne un PDF o quel che vuoi con qualsiasi altro programma. 🙂
Ecco, vedi, mi sei già stato utilissimo: ‘sta cosa che il file lo salva nella directory di destinazione non l’avevo mica ancora capita e mi domandavo appunto come caspita si facesse a salvare i cambiamenti apportati ai file originali.
Il confronto cogli altri è una cosa straordinaria, è sempre un arricchimento, specie poi se avviene con chi è più bravo di noi.
funziona benissimo sembra essere proprio quello che cercavo, grazie !!!
Ciao, visto che è passato un po’ di tempo, sai se ci sono novità in questo campo, oppure la soluzione che hai descritto nel tuo post per ora è la sola strada percorribile in modo degno in ambiente linux?
Grazie per gli ottimi suggerimenti che trovo nel tuo blog.
Se ti interessa un PDF sandwich in cui il testo riconosciuto sia allineato bene con la rispettiva immagine sì, è il modo gratuito più pratico e preciso. Anzi, ti dirò di più, aggiornando sia Wine che PDF XChange Viewer a una versione recente è molto più facile installare il programma senza crash (rispetto a quanto scritto quattro anni fa nel post).
Meglio usare un wineprefix a 32-bit comunque. 🙂
Se invece vuoi solo il testo e non ti interessa che sia posizionato bene sul documento finale, si può fare su Linux senza problemi.