Chi segue il blog da qualche tempo ormai lo sa, i miei post più seguiti sono quasi tutti dedicati al download di video delle principali emittenti italiane, e non solo, disponibili liberamente sui siti web.
Da diversi anni ho reso disponibili gratuitamente degli script (con annesso server di supporto, per Rai e Mediaset) dedicati ciascuno a un singolo sito web. Qui sotto trovate i link ai vari post, dai quali potete scaricare e installare ciò che vi interessa. 🙂
In passato ho sempre consigliato a tutti Greasemonkey su Firefox, perché è un componente aggiuntivo libero e open source che si può considerare anche la prima delle estensioni per usare gli user script. Poi è nata Tampermonkey per Chrome, Opera e altri browser e adesso ne esistono pure di ulteriori.
Nel lavoro di ammodernamento precedente all’uscita di Firefox 57 (Quantum), gli autori di Greasemonkey si sono trovati nella condizione di dover aggiornare l’estensione e ne hanno approfittato per fare alcune modifiche non retrocompatibili.
Ne è risultato che i miei script funzionavano bene su Greasemonkey 3, ma erano inefficaci su Greasemonkey 4. Quindi ho suggerito a tutti di passare a Tampermonkey. 😉
Come sempre accade, ho continuato a ricevere lo stesso qualche richiesta in merito a presunti “problemi” da sistemare sullo script, da persone che usavano Greasemonkey nonostante i ripetuti avvisi. Però per il resto è andato tutto abbastanza liscio.
Ad ogni modo ora non è più necessario preoccuparsi, infatti ho aggiornato tutti gli script per renderli funzionanti col nuovo Greasemonkey! 😀
Gli aggiornamenti
Non ho effettuato solo una modifica (per fortuna non troppo impegnativa) in termini di compatibilità garantita con Greasemonkey e Tampermonkey, ma in alcuni casi ci sono state delle modifiche ulteriori. Eccovi un riepilogo:
Rai Play: ora il link compare regolarmente, inoltre ho nascosto il fastidioso avviso che chiede all’utente di disattivare il blocco pubblicitario. Bloccare le pubblicità è fondamentale (leggete qui perché).
Video Mediaset: ora tutti i link compaiono regolarmente. Ho rimosso il pop-up che compare a chi accede a Mediaset dall’estero. Nella quasi totalità dei casi, chi usa il mio script può vedere i video geoprotetti di Mediaset anche in altri paesi.
La7: nella stragrande maggioranza dei casi funzionava già con Greasemonkey 4, ma ho fatto una piccola modifica per sistemare il resto.
Infine ho applicato la stessa correzione agli script per RSI e BBC.
Altre informazioni utili
Una cosa che ha confuso alcune persone è che da un po’ di tempo sia Rai che Mediaset richiedono di essere registrati, per vedere molti dei loro video. È così da diversi mesi, eppure pochi se ne sono accorti e ogni tanto qualcuno me lo “segnala”.
Il motivo è semplice: chi usa i miei script non deve registrarsi perché ci pensano loro a mostrare subito il video. Un risparmio di tempo e di privacy, saltando il login e la pubblicità iniziale. 🙂 Nei rari casi in cui un link non sia disponibile o riconoscibile dallo script, può comparire una finestra di login… ma non allarmatevi, è fatto così il sito.
Altra cosa utile da tenere a mente, lo accennavo prima, è che usando il mio script per Video Mediaset potete visualizzare tranquillamente quasi tutti i loro filmati anche dall’estero senza strumenti particolari. 😉 Questo perché i loro video “geo-protetti” sono protetti tanto quanto lo sarebbe un caveau pieno di diamanti, aperto e con un cartello che dice “non entrare”.
Per quanto riguarda invece i video della Rai (se non siete in Italia) o della BBC (se non siete nel Regno Unito) avrete bisogno di un servizio VPN serio. Ne ho parlato approfonditamente nell’articolo Cos’è una VPN e perché è fondamentale usarla per proteggersi. Il post ha dei link per acquistare degli account lifetime scontati… Sennò fate voi e scegliete quella che preferite. 🙂
Infine, vorrei precisare che questi aggiornamenti non riguardano i problemi di qualche giorno fa (sorti attorno al 15 gennaio) per i link che non comparivano sotto ad alcuni video su Rai Play. Quello era un malfunzionamento sul server (già risolto) causato dall’hosting provider. Ne ho parlato nei commenti sotto al post.
Licenza e nuova policy
Volevo infine chiarire una cosa importante sull’uso degli script ed eventuali richieste di assistenza in merito. Dal primo giorno (di oltre 6 anni fa!) gli script sono rilasciati sotto licenza GPL, una licenza libera. Ciò vi garantisce che potete usarli gratis e liberamente per qualsiasi scopo, installarli dove vi pare, condividerli e modificarli a condizione di riportare chi è l’autore e mantenere le modifiche sotto la stessa licenza.
Gli script (e relativo server di supporto) sono e restano a vostra disposizione.
Però è opportuno tenere a mente anche quanto è indicato nella licenza, in merito a eventuali garanzie di funzionamento. Userò la traduzione non ufficiale della GPLv3 per maggiore chiarezza:
Eccetto quando altrimenti stabilito per iscritto, i detentori del copyright e/o le altre parti forniscono il programma “così com’è” senza garanzia di alcun tipo, né espressa né implicita, incluse, ma non limitate a, le garanzie di commerciabilità o di utilizzabilità per un particolare scopo.
Ciò significa, in altri termini, che non devo fornire garanzie di funzionamento costante al 100%, stando sempre al passo con le modifiche ai siti delle varie TV. Né in realtà ho il tempo di farlo… aggiorno quando riesco, essendo tutte ore extra che devo spendere per gli script. 🙂
Non posso altresì dedicare molto tempo a rispondere ai quesiti che arrivano via email o messaggi privati, sennò diventa un impegno gravoso che va ad intaccare il tempo dedicato alla mia professione. Per questo motivo da oggi ho deciso di disattivare la chat della mia pagina Facebook.
Se ci sono dubbi, domande o commenti sugli script ho sempre chiesto agli utenti di usare l’area commenti dei relativi articoli. Per comodità vostra li trovate linkati all’inizio di questo post, quindi commentate pure!
Se 10 persone mi scrivono in privato, devo dare 10 risposte. Se 10 persone usano l’area commenti, la prima riceve la risposta e le altre 9 si trovano già la soluzione pronta senza far fatica. È un vantaggio per tutti! 😉
Come policy generale comunque ho intenzione di dare una mano con gli script a chi ha effettuato una donazione, naturalmente se ho tempo e se riesco. Contando la globalità degli script citati sopra, sono state superate le 60000 (sessantamila) copie installate. Vi lascio trarre qualche conclusione su quanto più tempo libero avrei se per ogni installazione mi fosse stato donato un euro. 😀
Chi usa gli script e non ha intenzione di donare sappia che può continuare a farlo gratuitamente tutte le volte che lo desidera. Semplicemente porti un po’ di pazienza se ogni tanto qualcosa non va. Chi invece ha la necessità di avere consulenze dedicate o script realizzati su misura (tutte attività che richiedono tempo) può chiedermi un preventivo in merito a tutti i servizi che offro.
Come vi avevo precedentemente notificato, lo scorso 28 ottobre ho partecipato al Linux Day 2017 organizzato dal LUG Vicenza. In realtà i video sono stati pubblicati quasi subito, ma è stato un periodo un po’ pieno e riesco ad informarvi solo ora. Qui di seguito trovate i video e le slide di ciascun intervento. 🙂
Pubblicità invasiva e spiona: come proteggersi su Android
Il video è disponibile su YouTube:
Clicca qui per mostrare contenuto da YouTube. (leggi la privacy policy del servizio)
Le slide sono su SlideShare (cliccate qui per il PDF):
Clicca qui per mostrare contenuto da SlideShare. (leggi la privacy policy del servizio)
Su questo argomento avevo anche scritto il post Bloccare le pubblicità sui dispositivi Android che potete usare come riferimento per seguire più facilmente le istruzioni date nel video.
Come sviluppo le applicazioni web
Il video è disponibile su YouTube:
Clicca qui per mostrare contenuto da YouTube. (leggi la privacy policy del servizio)
Le slide sono su SlideShare (cliccate qui per il PDF):
Clicca qui per mostrare contenuto da SlideShare. (leggi la privacy policy del servizio)
Quest’anno al GrappaLUG abbiamo deciso di aggregarci agli amici del Gruppo Utenti GNU/Linux di Vicenza per l’organizzazione del Linux Day. Andremo lì come delegazione e lavoreremo tutti assieme per realizzare un evento bello, gratuito e utile presso il Centro Giovanile di Torri di Quartesolo, al confine con Vicenza.
Per chi non lo sapesse, ricordo che:
Dal 2001 il Linux Day è una iniziativa distribuita per conoscere ed approfondire Linux ed il software libero. Si compone di numerosi eventi locali, organizzati autonomamente da gruppi di appassionati nelle rispettive città, tutti nello stesso giorno. In tale contesto puoi trovare talks, workshops, spazi per l’assistenza tecnica, gadgets, dibattiti e dimostrazioni pratiche.
L’argomento di quest’anno è Privacy e riservatezza individuale. Io proporrò due talk, il primo dei quali è piuttosto in linea con il tema:
Ore 12.00–12.30 — Pubblicità invasiva e spiona: come proteggersi su Android
Le pubblicità sul web sono per natura fastidiose, ma quelle dedicate agli smartphone sono particolarmente problematiche. Esse ci profilano costantemente, tracciando le pagine che visitiamo e i nostri interessi. Il tutto mentre ci consumano una larga parte dei dati mobili consentiti dal piano tariffario. Vedremo nei dettagli i rischi causati dalle pubblicità e alcuni metodi semplici ma efficaci per proteggere i nostri smartphone Android.
Ore 15.00–15.45 — Come sviluppo le applicazioni web
Oggi possiamo finalmente lasciarci alle spalle l’idea di dover utilizzare PHP per lo sviluppo web. Durante la presentazione verrà spiegato un semplice workflow che utilizzo per lavorare con Python, Flask, SQLite, Apache e Git per ridurre i bug, semplificare il codice e ottimizzare i tempi di deployment.
L’ho intitolato così perché scrivere “PHP fa schifo” sul volantino pareva brutto. 😀 Sto scherzando ovviamente, ho usato PHP e ogni tanto lo uso ancora, però le dichiarazioni dell’autore stesso Rasmus Lerdorf fanno riflettere. Inoltre Flask mi sta veramente cambiando il modo di lavorare in positivo e parlare di Python è sempre un’ottima cosa. 🙂
Oltre a questo, il titolo è volutamente neutro: parlerò di come io sviluppo le applicazioni web, ma non significa che sia l’unico modo possibile.
Per tutti i dettagli vi rimando alla pagina del Linux Day 2017 sul sito del LUG Vicenza. Come sempre l’ingresso è libero e gratuito, perciò non mancate!
Oggi 9 ottobre 2017, alle 13:30 ora italiana (11:30 UTC), migliaia di numeri cellulari in Italia hanno ricevuto un SMS molto sospetto da un mittente mascherato dalla stringa “BitcoinCode”.
Ho effettuato una rapida analisi del messaggio e del relativo link, potendo stimare il numero minimo di utenti colpiti e verificare che il sito linkato è piuttosto infido e decisamente inaffidabile (come era prevedibile). Lo scopo di questo post è duplice: da una parte vorrei descrivere la metodologia di analisi utilizzata e dall’altra mettere in guardia chiunque si imbatta nel metodo “Bitcoin Code”.
Lo strano SMS
Il contenuto dell’SMS è già piuttosto sospetto (il link non è cliccabile, volutamente):
Hai (1) Bitcoin nel tuo account. Conferma l’account qui: http://bit.ly/2y9WNXB Valore di mercato corrente 3895.83 Euro
Ma guarda… a pranzo stavo giusto pensando “buono questo panino, è da un po’ che qualcuno non mi regala 4000 euro”. Come no! 😀
Ora, dirò una cosa (spero) ovvia, però… chiaramente non ho aperto il link. In questi casi non si deve mai cliccare collegamenti ignoti che potrebbero potenzialmente portare a pagine contenenti malware, o anche semplicemente tracciare il fatto che il proprio numero telefonico ha ricevuto e letto l’SMS.
Analisi dell’URL
Bit.ly è un famosissimo servizio per accorciare (e in un certo senso mascherare) degli URL. Non c’entra nulla con questi messaggi promozionali, serve solo a rendere un URL più corto, una cosa utile per inviarlo via SMS. La cosa interessante è che ha anche delle funzionalità statistiche: chiunque conosca un URL generato da questo sito può semplicemente aggiungere un + alla fine e ottenere maggiori informazioni.
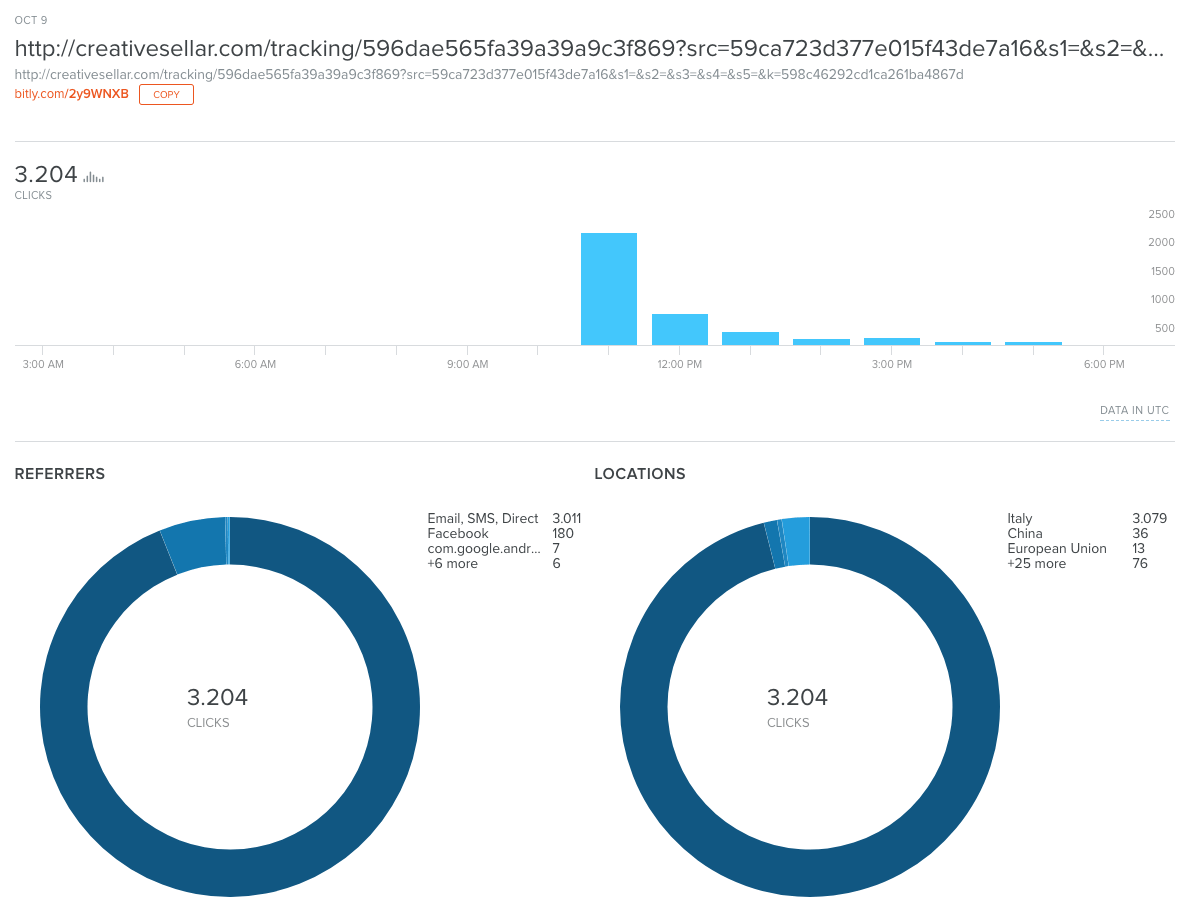
Andando a visitare http://bit.ly/2y9WNXB+ ho potuto capire che l’URL non avrebbe tracciato il mio numero di cellulare, perché è stato aperto oltre 3200 volte:
Le visite che ha ricevuto il link contenuto nell’SMS
È interessante vedere come il link sia stato condiviso anche su Facebook e in misura molto ridotta anche in altre nazioni. Il picco di visite nella fascia 11:00-11:59 UTC (cioè 13:00-13:59 in Italia) coincide con l’orario in cui ho ricevuto l’SMS.
Escluso il tracciamento, restava comunque il rischio di malware. Prima di puntare un browser a quell’indirizzo, è stato opportuno provare a vedere dove andasse a finire quell’URL. Ho usato HTTPie che è molto comodo:
http --follow --all get 'http://creativesellar.com/tracking/596dae565fa39a39a9c3f869?src=59ca723d377e015f43de7a16&s1=&s2=&s3=&s4=&s5=&k=598c46292cd1ca261ba4867d'
La pagina delle statistiche di Bit.ly consente di vedere la versione originale dell’URL, di conseguenza si può visitare senza incrementare le statistiche. In altri termini, nessuno di quei 3200 click è mio. 🙂
L’output di HTTPie è decisamente prolisso perché mostra tutti gli header HTTP (piuttosto utili per fare debugging e analizzare pagine sospette) ma mi limito a dire che i redirect sono stati i seguenti:
Clicca qui per mostrare contenuto da YouTube. (leggi la privacy policy del servizio)
Alla fine sono capitato su bitcoinmillions.co, in particolare nella versione svedese per via dell’IP della VPN che sto usando oggi. Ho aperto l’URL in una macchina virtuale da analisi e poi ho verificato che il sito è disponibile anche in italiano, tedesco, inglese e qualche altro idioma (basta cambiare il codice della lingua nell’URL).
Stranezze e assurdità
La pagina ha lo scopo di presentare all’ignaro utente il metodo “Bitcoin Code” che consentirebbe, tramite investimenti sulle opzioni binarie, di guadagnare… udite udite… 13000 euro al giorno senza fare un bel niente. Di nuovo: come no! 😀
Il finto inventore di Bitcoin Code
Secondo il sito, il “genio” dietro a questo metodo (talmente geniale da rivelarlo a tutti gratis) sarebbe Stefano Savarese. Mi correggo: secondo la versione italiana del sito. Infatti per la versione inglese sarebbe Steve McKay, per quella tedesca Sven Hegel e per quella svedese Stefan Holmquist.
La foto del presunto inventore è uguale, ma i nomi sono diversi. Ah, se l’immagine vi piace è possibile acquistarla su questo sito di immagini stock, ma penso che l’aveste già immaginato. Questo fatto è stato scoperto facilmente con TinEye, un motore di ricerca per immagini.
Un altro elemento che non dà alcuna fiducia è il modulo di registrazione senza HTTPS, ma quello purtroppo si trova anche su siti meno “sospetti”. L’ennesimo campanello d’allarme dovrebbe suonare notando che questo metodo “gratuito” richiede un versamento minimo di 250€ che presumibilmente non rivedrete mai più e di certo non diventeranno 13000.
Chi c’è dietro a tutto questo?
Metto subito le mani avanti: l’attribuzione di siti, messaggi e “operazioni di business” varie è una cosa molto complicata e non bisogna fidarsi troppo delle informazioni trovate. D’altro canto però non fidarsi è un atteggiamento buono e prudente.
Detto ciò, la cosa più naturale è controllare il Whois dei vari domini coinvolti, sperando di trovare qualcosa. Così ho fatto:
whois creativesellar.com
… e via dicendo per gli altri. Come temevo, tutti quanti i domini sono protetti da qualche servizio di whois privacy o comunque riportano dati inaccurati. Questo non indica per forza un problema, ma quando si parla di investimenti sarebbe consigliabile sapere con chi si ha veramente a che fare.
Volendo arrivare al dunque, mi sono registrato con un indirizzo di Mailinator e ho cercato di trovare la pagina in cui Bitcoin Code mi avrebbe chiesto dei soldi. Avendo usato la versione inglese del sito, ho ricevuto un’email di conferma inviata da un tale Alfie Hughes usando SendLane, un servizio per l’invio di email.
SendLane aggiunge il nome e l’indirizzo del mittente in fondo al messaggio, o meglio i dati che costui ha usato per crearsi un account. Nell’email che ho ricevuto era riportato:
BTC ltd
7 More London Riverside
London
United Kingdom, SE1 2RT
Peccato che questo sia l’indirizzo della sede londinese di PwC, una rispettabile multinazionale che non ha nulla a che vedere con questa truffa. Ecco l’ennesimo segno dell’inaffidabilità di Bitcoin Code (come se ce ne fosse bisogno).
Per usare l’account e depositare i soldi sono stato rimandato verso un sito esterno, cioè https://www.toroption.com. Dai, almeno questo ha l’HTTPS così ti puoi far spillare del denaro ma in sicurezza. 😉
Anche il Whois di questo dominio è occultato.
La pagina di contatto del sito racchiude un altro aspetto bizzarro: cambia le informazioni e i numeri di telefono a seconda della lingua scelta. Inoltre i dati non sono rappresentati come testo (anche se sembra che sia così) ma sono un’immagine!
La versione inglese è l’unica che riporta due indirizzi:
Main Office
Royal Capital Ltd.,
Off. 13, 97 Andranik
Zoravar St. Yerevan
Smart Choice Zone LP,
272 Bath Street Glasgow.
G2 4JR. Scotland
+44-2035192667
+37-460462823
Scopriamo quindi che l’ufficio principale sarebbe a Yerevan, in Armenia, cosa che sembra plausibile. Il secondo indirizzo è di un servizio che noleggia uffici virtuali a Glasgow, in Scozia. Anche attività rispettabili usano questi servizi, a volte.
Dei due numeri di telefono riportati, il secondo mostra come prefisso +37 (che era in uso alla Germania dell’Est un po’ di anni fa) ma in realtà è +374, che corrisponde all’Armenia.
The Financial Services and Markets Authority (FSMA) warns the public against the activities of TorOption, a company that offers binary options without complying with Belgian financial legislation.
TorOption is not allowed to provide banking and/or investment services in or from Belgium.
Furthermore, the FSMA reminds the public that since 18 August 2016, no investment firm (authorized or not) is permitted actively to distribute, within the territory of Belgium, binary options or any other derivative instruments whose maturity is less than one hour and/or that directly or indirectly use leverage (including forex derivatives and CFDs).
The FSMA thus strongly advises against responding to any offer of financial service made by TorOption and against transferring money to any account number it might mention.
L’avvertimento completo, che vi consiglio di leggere, segnala anche un comunicato analogo della Commissione Nazionale del Mercato dei Valori (CNMV) spagnola.
In conclusione
Abbiamo visto come in data odierna migliaia di italiani abbiano ricevuto un messaggio truffaldino, che tentava di convincere le persone ad investire dei soldi con la promessa di guadagni allettanti e assolutamente irreali.
L’analisi delle informazioni disponibili con tecniche OSINT (ma soprattutto la valutazione di cosa non è disponibile) ha confermato ciò che l’intuito faceva presagire: pur non trattandosi di malware, è comunque meglio stare alla larga da Bitcoin Code, TorOption e qualsiasi altra operazione legata a tali entità.
Io non sono un esperto di investimenti, quindi di certo non vi dirò che uso fare dei vostri soldi, né voglio pubblicizzare altre alternative “più affidabili” (come invece ho visto fare ad altri siti che hanno accennato a Bitcoin Code). 🙂
Però una cosa ve la voglio dire: se volete fare investimenti, valutate attentamente l’affidabilità dei soggetti coinvolti. Non lasciatevi allettare dal miraggio di guadagni talmente facili da essere impossibili!
Esattamente a un anno dalla mia prima partecipazione a ESC, sono stato nuovamente invitato per portare un contributo a questo interessante evento. Dal sito ufficiale:
ESC è un incontro non-profit di persone interessate al Software e Hardware Libero, all’Hacking e al DIY. Il contenuto dell’evento è in continua evoluzione e viene creato dai suoi partecipanti.
In particolare, quest’anno ho deciso di partecipare anche perché ci sono state delle novità organizzative. Sono convinto che ciò porterà una ventata di freschezza e di continuo miglioramento all’evento, cosa che non fa mai male. 🙂 L’edizione 2017 sarà coordinata da Sebastiano Mestre (fondatore dell’evento) con l’aiuto dell’Associazione Radioamatori Italiani – Sezione di Mestre – “Enrico De Rossi I3DRE”.
Ma non preoccupatevi, la consueta formula amichevole, gratuita e informale (con tanto di campeggio) rimarrà invariata! 😉 Io sarò presente il 1° settembre con due talk, il primo dei quali in rappresentanza di Gimp Italia:
Ore 15:00 — Correzioni fotografiche con GIMP
GIMP possiede tutti gli strumenti necessari per operare le correzioni più diffuse alle foto. Alcuni accorgimenti, infatti, consentono di osservare subito un miglioramento delle immagini. Il talk verterà su un approccio semplice per la correzione di luminosità e colori.
Il secondo invece sarà una riproposizione di un talk che avevo tenuto alla DUCC-IT a Vicenza:
Ore 16:00 — Ask Ubuntu: aiutare anche senza saper programmare
Ask Ubuntu è un sito Q&A (domanda e risposta) che raccoglie gli utenti di questa popolare distribuzione. Tramite un sistema collaborativo ed autogestito, tutti i partecipanti donano il proprio contributo per aiutarsi a vicenda e risolvere problemi o dubbi relativi all’uso di Ubuntu, portando beneficio a tutta la comunità.
Come nelle scorse edizioni, l’evento si terrà a Forte Bazzera e naturalmente questi due talk sono solo la punta dell’iceberg. Ci sono tantissimi talk in programma perciò non lasciateveli sfuggire!
Vi ricordo che per partecipare è necessario registrarsi qui.
Ci vediamo all’ESC! 😀
Aggiornamento — Video dei talk
Clicca qui per mostrare contenuto da YouTube. (leggi la privacy policy del servizio)
Clicca qui per mostrare contenuto da YouTube. (leggi la privacy policy del servizio)
Questo post è una traduzione del mio articolo Extracting data from damaged NTFS drives pubblicato originariamente il 9 marzo 2017 sul blog di eForensics Magazine. Il testo descrive in modo dettagliato il mio lavoro di tesi magistrale sulla ricostruzione forense di file system NTFS con metadati danneggiati e il funzionamento di RecuperaBit.
L’articolo è fruibile liberamente e il software è open source, nonché estendibile tramite plug-in (c’è un esempio nell’ultima parte del post). Se avete bisogno di consulenza sul recupero dati o l’analisi forense di file system potete contattarmi tramite il modulo di richiesta per i miei servizi professionali.
Introduzione
L’analisi dei file system è una parte molto importante dell’attività di digital forensics. Molte indagini riguardano dischi rigidi il cui contenuto deve essere analizzato. In alcuni casi, anche i file eliminati potrebbero dover essere recuperati. Ci sono diversi tipi di file system e NTFS è attualmente uno dei più popolari.
La corruzione del file system può verificarsi per diversi motivi e può compromettere la possibilità di aprire e recuperare i file. Perciò, gli i tool forensi devono comprendere la struttura di un file system e devono essere in grado di estrarre il maggior numero possibile di dati, anche in condizioni difficili. Il file carving è una tecnica popolare per estrarre i file dai media danneggiati, tuttavia i file estratti in questo modo generalmente perdono i metadati e la struttura delle directory della partizione non può essere recuperata. È necessario un approccio migliore perché i nomi, i percorsi e i timestamp dei file sono informazioni molto importanti.
In questo articolo imparerete come la struttura delle directory di un’unità NTFS può essere ricostruita anche se alcune porzioni dei metadati sono parziali, corrotte o completamente assenti. Tutte le fasi del processo verranno spiegate. L’algoritmo presentato porta ad un’interpretazione del file system che consente il recupero di nomi, percorsi, timestamp e contenuto dei file (inclusi quelli frammentati). Infine, imparerete come utilizzare e personalizzare uno strumento open source che implementa queste tecniche.
Come funziona la ricostruzione di NTFS?
Prima di approfondire le tecniche che possono essere utilizzate per ricostruire una partizione NTFS, è necessario introdurre alcuni concetti. NTFS è un file system proprietario sviluppato da Microsoft e utilizzato per impostazione predefinita in Windows a partire da Windows 2000. È anche presente nei dischi rigidi esterni ad alta capacità, in quanto pure Linux e macOS lo supportano.
Funzionamento interno di NTFS
Il concetto principale di NTFS è che tutto è un file, vale a dire che anche i metadati necessari per funzionare sono memorizzati in diversi file. Il più importante è la MFT (Master File Table) che include almeno un file record (chiamato MFT entry) per ogni file o directory allocato/a. Ogni entry contiene diversi attributi. Per questo motivo, un file potrebbe avere più di una entry se i suoi attributi non possono essere inseriti tutti in una.
Questi sono gli attributi più importanti:
$STANDARD_INFORMATION (id 0x10 = 16) memorizza i MAC time (Modifica, Accesso e Creazione) nel formato più assurdo di sempre: il numero di cento nanosecondi dal 1° gennaio 1601 UTC
$ATTRIBUTE_LIST (id 0x20 = 32) include i riferimenti alle non-base MFT entry che contengono altri attributi dello stesso file (se presenti)
$FILE_NAME (id 0x30 = 48) memorizza più nomi di file: generalmente il nome del file DOS 8.3 e quello lungo utilizzato dalle versioni recenti di Windows, a meno che i due non siano uguali
$DATA (id 0x80 = 128) include l’intero file se è inferiore a circa 700 byte, altrimenti dobbiamo fare riferimento alla runlist (un elenco che indica la posizione e la dimensione di ciascun frammento sul disco)
$INDEX_ROOT (id 0x90 = 144, solo per le directory) contiene gli attributi $FILE_NAME di (alcuni) elementi figli
$INDEX_ALLOCATION (id 0xA0 = 160, solo per le directory) si riferisce agli index record esterni memorizzati sul disco che registrano i riferimenti ai restanti elementi figli
I file record sono di dimensioni pari a 1 KB e possono essere riconosciuti perché iniziano con la firma FILE, o BAAD se il record è contrassegnato come danneggiato dal sistema operativo. Gli index record sono di 4 KB e la loro firma è INDX.
Infine, i primi e gli ultimi settori di una partizione NTFS sono due copie del boot record, che contiene questi parametri importanti:
Settori per cluster (SPC), necessario perché gli indirizzi in NTFS sono espressi in cluster (gruppi di settori) e devono essere tradotti durante il ripristino di file o metadati
Indirizzo di partenza della MFT, relativo al primo settore della partizione (a cui ci riferiamo con la dicitura Cluster Base o CB)
Dimensione del file system, espressa in settori e cluster
Normalmente, un sistema operativo inizia dal boot record, quindi salta alla MFT e inizia a leggere i file record e gli index record quando esplora l’intera struttura delle directory. Tuttavia, per eseguire una ricostruzione NTFS efficace, dobbiamo tenere presente che i metadati potrebbero essere parzialmente danneggiati:
La tabella delle partizioni potrebbe essere sbagliata
Potremmo non avere il boot record né il suo backup
Alcune MFT entry e/o index record potrebbero non essere leggibili
Alcune MFT entry potrebbero essere perse a causa di un nuovo file system che ne copre parzialmente uno cancellato
Per questi motivi, un approccio più sicuro a questo problema è supporre lo scenario peggiore. Invece di affidarsi alla tabella delle partizioni o al boot record di una partizione, il processo corretto è quello di scansionare l’intera unità cercando tracce dei boot record, dei file record e degli index record. Ciò consente di trovare anche le MFT entry di file cancellati recentemente.
Fondamentalmente, invece di fare carving dei file, lo effettuiamo sui metadati, raccogliendo i settori interessanti in tre liste.
Ciò fornisce un elenco di settori in cui i ci sono i potenziali file record, ma possono appartenere a partizioni diverse. Quindi, l’ultimo passo di questa fase è farne il clustering. Non possiamo contare sulla loro posizione perché la nostra ipotesi è che non sappiamo ancora dove si trovavano le partizioni (o le loro MFT), inoltre una partizione potrebbe essere stata parzialmente sovrascritta da un’altra.
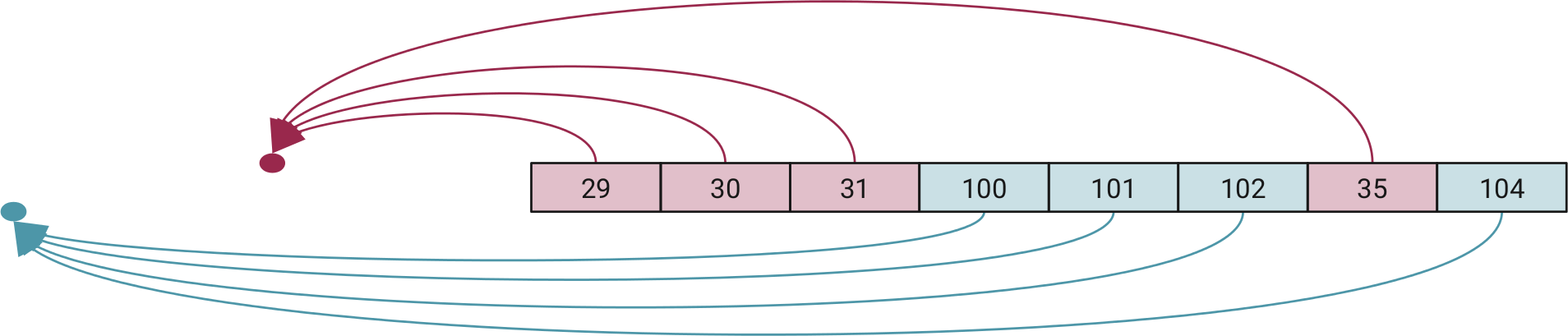
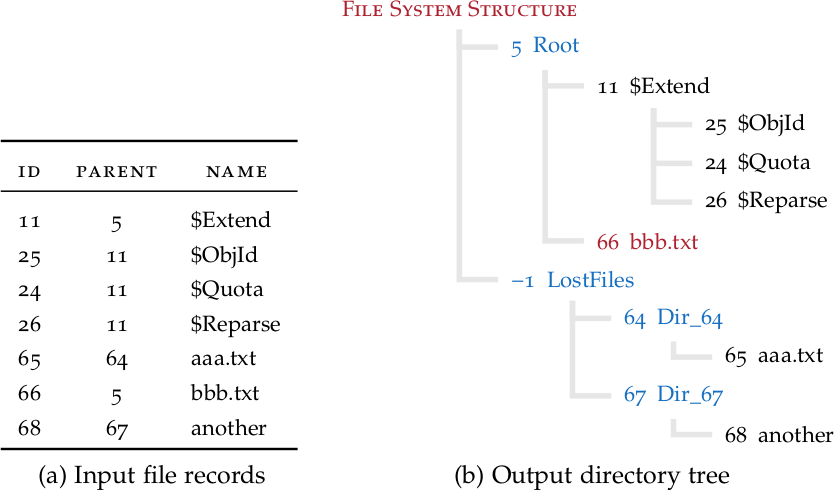
Possiamo tuttavia sfruttare il fatto che ogni file record contiene il proprio identificatore e che la MFT è generalmente contigua. Attraverso una semplice formula lineare, possiamo calcolare la posizione del corrispondente file record #0 per ogni file record che stiamo considerando:
p = y – 2x
Dove y è la posizione del record sul disco (in settori) e x è il record number. Possiamo quindi dividere i file record in base al loro valore p.
Una rappresentazione visiva del processo di clustering dei file record
Ricostruzione bottom-up dell’albero
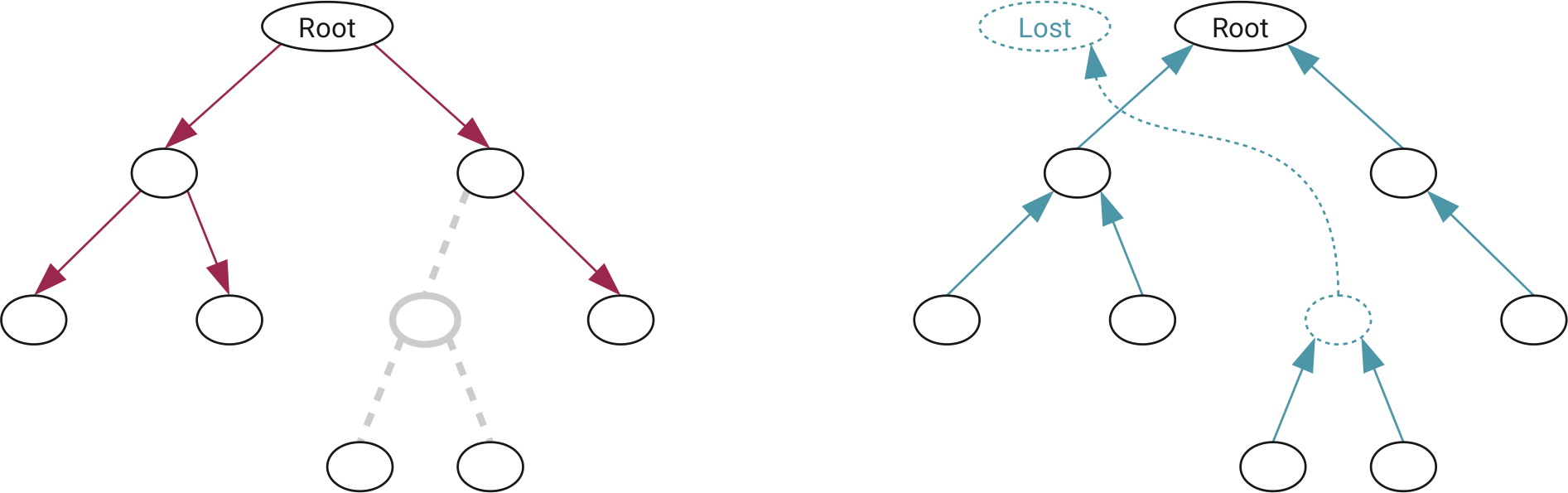
A questo punto abbiamo alcune “partizioni” che sono solo liste di file record. Non c’è ancora una struttura ad albero delle directory. Non possiamo leggere la struttura del file system dall’alto verso il basso, perché se mancasse un directory record, tutti i file sotto di esso sarebbero inaccessibili.
Al contrario, possiamo sfruttare il fatto che le MFT entry contengono anche l’identificatore della directory genitore. Inoltre, sappiamo che la directory principale in NTFS è sempre la #5. Possiamo procedere a ricostruire l’albero delle directory in modo bottom-up utilizzando un processo semplice.
Per ogni file:
Se abbiamo trovato il record del suo genitore, colleghiamo il file al genitore
Se conosciamo l’id del genitore ma non c’era un file record, creiamo un file record finto chiamato Dir_[number] e colleghiamo ad esso il file
Se non conosciamo il genitore, colleghiamo il file a una directory LostFiles
Se il file record è 5, consideriamo questa la radice del file system
Accesso al file system dall’alto verso il basso (a sinistra) rispetto alla ricostruzione dell’albero dal basso verso l’alto (a destra)
Come si può vedere, questo semplice processo non dipende dal tipo di file system e potrebbe essere applicato facilmente ad altri file system fintantoché i file record hanno un id e un puntatore al record genitore. Se manca il record di una directory, non è un grosso problema perché gliene creiamo uno che includa tutti i suoi figli. La directory mancante viene quindi inserita tra i file persi.
Esempio di ricostruzione bottom-up
Fino ad ora non abbiamo considerato alcun index record. Ciò significa che l’approccio funzionerebbe anche se tutti gli index record non fossero disponibili. Tuttavia, l’albero risultante può essere completato con ulteriori informazioni su quelli che possiamo chiamare “file fantasma”. Questi sono file i cui record non sono stati trovati, ma la loro esistenza potrebbe essere determinata indirettamente da entry trovate negli index record.
I file fantasma non possono essere recuperati, ma il fatto che esistessero in passato potrebbe essere rilevante in un’indagine.
Individuare la geometria delle partizioni
Abbiamo visto come l’albero delle directory (o parti di esso) può essere ricostruito utilizzando i file record e gli index record. Ciò fornisce una rappresentazione accurata del file system, inclusi i nomi dei file, i timestamp e altri metadati rilevanti.
Questo è un ottimo risultato, tuttavia manca ancora un minuscolo dettaglio: il contenuto dei file.
I metadati sono sicuramente importanti, ma altrettanto lo sono i dati. Tutti i puntatori ei riferimenti in NTFS sono espressi in cluster e si riferiscono all’inizio della partizione. Dobbiamo trovare questi due parametri se vogliamo accedere ai file:
Settori per cluster (SPC)
Cluster base (CB)
Se abbiamo trovato un boot record che può essere collegato alle MFT entry che abbiamo, allora fila tutto liscio. Il parametro SPC viene scritto nel boot sector e il valore CB si ricava dalla sua posizione, o quella meno la dimensione della partizione se stavamo leggendo il boot record di backup.
Purtroppo, non possiamo fare affidamento sulla presenza del boot sector quando si tratta di hard disk danneggiati. Abbiamo bisogno di un modo per recuperare entrambi i parametri anche quando abbiamo solo file record e index record.
Possiamo sfruttare le informazioni contenute all’interno dei index record. Come abbiamo visto prima, gli index record contengono un elenco di attributi $FILE_NAME. Tra gli altri dati, questi contengono anche un riferimento alla directory genitore. Pertanto, per ogni index record possiamo stimare la directory a appartiene solo guardando le sue entry.
Ripetendo questo processo per tutti i record, possiamo trasformare il disco rigido in un “testo” in cui ogni lettera corrisponde ad un settore. Ogni settore ha uno spazio vuoto, ad eccezione di quelli che contengono un index record. In tal caso, lo spazio è riempito con l’id del suo proprietario.
Successivamente, consideriamo tutte le MFT entry delle directory che hanno almeno un attributo $INDEX_ALLOCATION. Dagli attributi, possiamo vedere in quale posizione (in cluster) dovrebbe essere un corrispondente index record. Se lo facciamo per tutte le MFT entry, abbiamo una “parola” le cui lettere corrispondono a cluster e contengono uno spazio vuoto o l’identificatore di una directory.
Quello che ancora non sappiamo è quanti ci settori sono in un cluster (SPC), ma possiamo tentare di indovinarlo. I valori validi sono piccole potenze di due, come 1, 2, 4, 8, 16, 32, 64 e 128. I più comuni in realtà sono 1 e 8.
Il nostro obiettivo è trovare il valore corretto di SPC, enumerando CB. Per ogni possibile valore di CB il processo consiste in:
Convertire la “parola” da cluster a settori usando l’attuale valore di CB. Ad esempio, [_, 6, 9, _, 2, 11] con SPC = 2 diventa [_, _, 6, _, 9, _, _, _, 2, _, 11, _].
Fare matching della “parola” sul “testo” dato dagli index record trovati sul drive. Possiamo utilizzare una versione ottimizzata dell’algoritmo Baeza-Yates–Perleberg per lo string matching approssimato al fine di calcolare la posizione che fornisce la corrispondenza più accurata.
Questo fornisce un valore di CB per ogni possibile SPC. Il valore con la massima precisione calcolata durante il processo di matching vince. Se recuperiamo la geometria della partizione, possiamo estrarre tutti i file leggendo le loro MFT entry.
Inoltre, a questo punto possiamo verificare se alcune partizioni sono in realtà due parti della stessa partizione (che può succedere se la MFT è stata frammentata). In tal caso, le due parti possono essere fuse.
RecuperaBit è un programma a riga di comando che ho sviluppato utilizzando tutte le tecniche descritte in precedenza. È un software libero e open source scritto in Python, pertanto è possibile studiarne il codice, estenderlo e personalizzarlo a seconda delle necessità.
Attualmente supporta solo NTFS, ma la sua architettura consente di aggiungere nuovi plug-in in futuro. Il programma tenta di ricostruire l’albero delle directory indipendentemente da:
tabella delle partizioni mancante
confini delle partizioni sconosciuti
metadati parzialmente sovrascritti
formattazione veloce
Installare il software
RecuperaBit può essere eseguito su Linux, Windows e macOS a condizione che Python 2.7 sia disponibile sul sistema. Durante l’ultimo hack camp ESC2016 a Venezia, è stato anche mostrato in esecuzione su un tablet Android rootato. L’installazione è molto semplice perché lo strumento è autonomo. Dovete solo scaricare l’archivio da GitHub e decomprimerlo, quindi invocare il file main.py.
Per ottenere la comodità di richiamare recuperabit dalla linea di comando è necessario un semplice collegamento simbolico. Su un sistema Linux, l’installazione può essere tanto facile quanto eseguire i seguenti comandi come root:
cd /opt
git clone https://github.com/Lazza/RecuperaBit.git
ln -s /opt/RecuperaBit/main.py /usr/local/bin/recuperabit
Ora è possibile visualizzare le istruzioni di utilizzo con:
recuperabit -h
Questo partirà con l’implementazione cPython predefinita. Per ottenere prestazioni più veloci, potete installare PyPy e modificare la shebang di main.py (che è la prima riga del file) in modo che faccia riferimento a /usr/bin/pypy.
RecuperaBit nel menu applicazioni di CAINE 8
Se state utilizzando il fantastico sistema Linux per l’informatica forense CAINE 8, sappiate che RecuperaBit è già incluso tra gli strumenti forniti nell’installazione predefinita, tuttavia non è facilmente disponibile dalla riga di comando a causa di un piccolo bug. Anche se su CAINE non è necessario scaricare RecuperaBit, potreste volerne creare un collegamento simbolico con il seguente comando:
Tuttavia, tenere presente che alcune correzioni di bug per RecuperaBit sono state rilasciate dopo l’uscita di CAINE 8. Per questo motivo, suggerisco di installare l’ultima versione come descritto in precedenza, per evitare crash su file system particolarmente danneggiati.
Un esempio concreto
È possibile testare lo strumento su qualsiasi immagine di un disco rigido che contenga una partizione NTFS o alcune tracce di essa. Potreste perfino eseguirlo sul dump di una singola MFT entry e avreste comunque alcune informazioni di base, come il nome del file o l’id del file record.
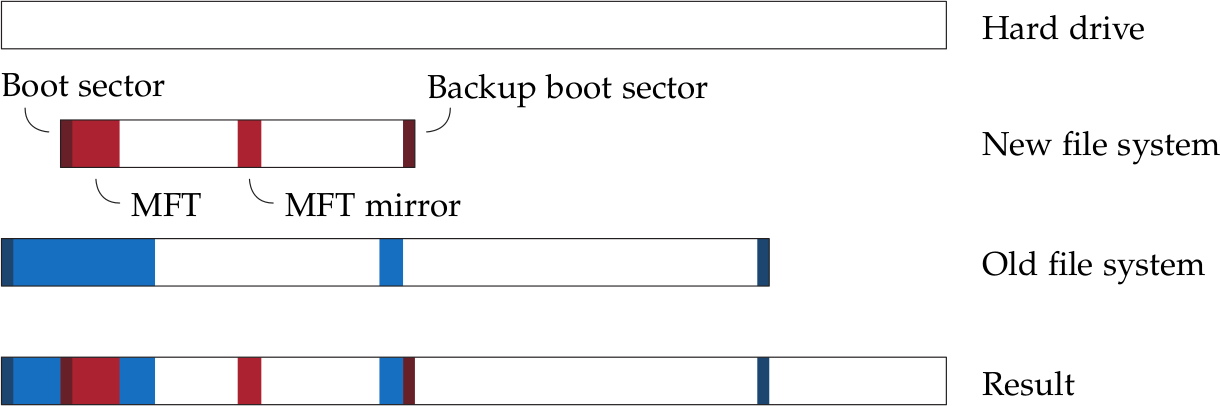
Per questo articolo, useremo un esempio appositamente predisposto che è possibile scaricare qui. L’archivio compresso contiene un’immagine disco da 1 GB con un file system NTFS da qualche parte nel mezzo, utilizzando un insolito valore SPC di 16. Nessuna tabella delle partizioni è disponibile e i boot sector sono stati cancellati. Inoltre, anche le prime quattro voci della MFT e il relativo backup (che costituiscono la cosiddetta “MFT mirror”) sono andati perduti.
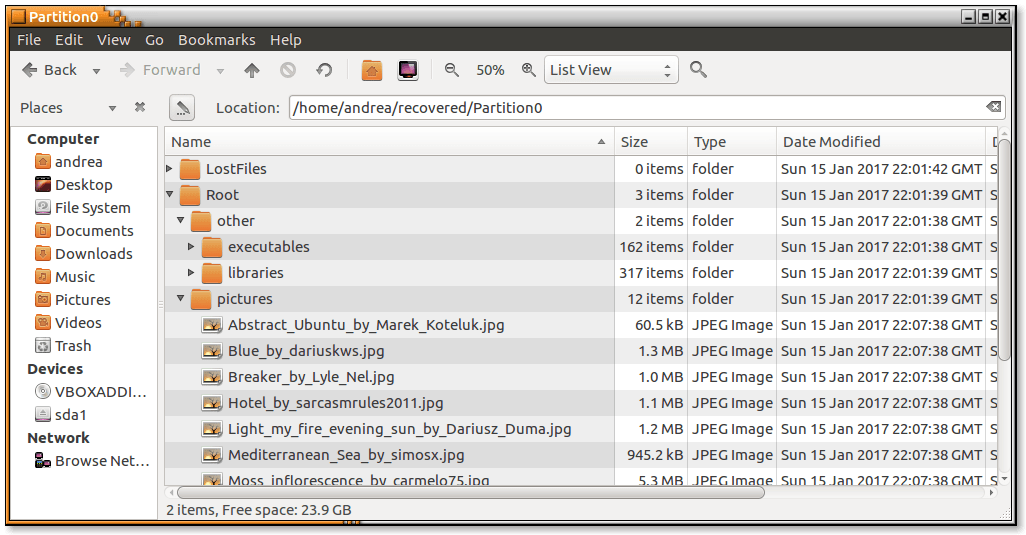
La directory principale conteneva i seguenti elementi:
Una directory chiamata other con due sottodirectory: libraries e executables contenenti un gruppo di file estratti da un’installazione di Ubuntu
Una directory chiamata pictures, con inclusi dei file JPG e PNG
Una directory denominata texts con più file di testo
Complessivamente, c’erano circa 500 file.
Supponendo che stiate lavorando nella directory in cui è stato salvato il file di immagine, è possibile passare il nome del file a RecuperaBit come argomento. È inoltre necessario specificare una directory di output e un nome di file per memorizzare l’elenco dei settori interessanti:
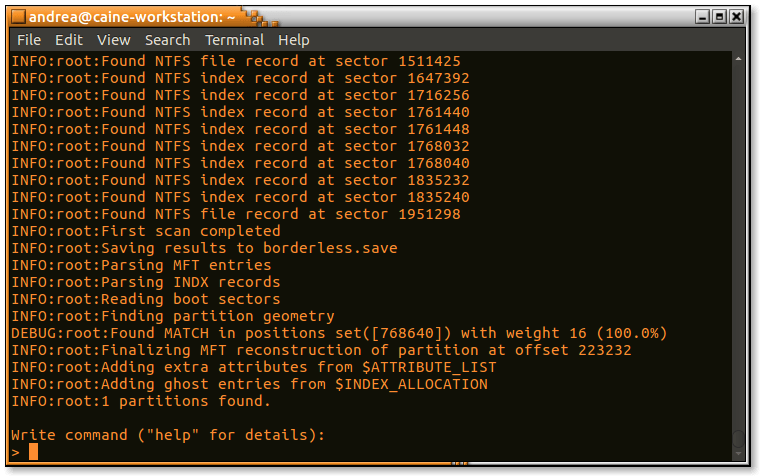
Il programma stamperà un breve riepilogo di cosa andrà a fare e attenderà fino a quando non premerete Enter. Procederà quindi alla scansione dell’unità e stamperà un registro dettagliato delle operazioni in corso. Alla fine, otterrete una primitiva linea di comando che potete utilizzare per analizzare ed estrarre le partizioni che sono state trovate.
RecuperaBit dopo la fase di elaborazione iniziale
Si può vedere che RecuperaBit ha cercato di determinare la geometria della partizione anche se i boot record non erano disponibili, trovando una corrispondenza:
INFO:root:Finding partition geometry
DEBUG:root:Found MATCH in positions set([768640]) with weight 16 (100.0%)
Se digitate recoverable al prompt, vedrete che sono state rilevate le informazioni di base sul file system danneggiato e che i file possono essere recuperati:
A questo punto, potete estrarre ricorsivamente i file. La directory principale in NTFS ha l’identificatore 5 e la partizione che desiderate è la #0. Di conseguenza, potete eseguire:
restore 0 5
Questo comando estrarrà i file allocati e cancellati. Inoltre, creerà dei segnaposti vuoti per i file fantasma, se presenti. L’output sembra promettente:
In alcuni casi, i file finiranno nella directory dei file persi, alla quale viene dato un id convenzionale pari a -1. In questo caso, potete eseguire anche restore 0 -1. Ora è il momento di guardare dentro la cartella recovered e verificare che cosa ha estratto RecuperaBit!
Alcuni dei file recuperati
Con RecuperaBit potete ottenere anche:
Una rappresentazione ad albero dei file (non fatelo su dischi grandi!), ad esempio: tree 0
Un elenco CSV dei file, ad esempio: csv 0 contents.csv
Un body file che elenca tutti i file, ad esempio: bodyfile 0 contents.body
Aggiungere un plug-in per un altro file system
Al momento, solo le partizioni NTFS possono essere scansionate utilizzando RecuperaBit. Tuttavia, è possibile scrivere nuovi plug-in per altri file system. Discutere il funzionamento interno di un file system come FAT o HFS+ sarebbe un compito molto difficile e non rientra nell’ambito di questo articolo. Tuttavia, descriverò brevemente ciò di cui avete bisogno per iniziare a scrivere un plug-in per RecuperaBit.
Il programma funziona dando in pasto ogni settore del disco a un insieme di scanner (ognuno dei quali è per un diverso tipo di file system). Uno scanner deve ereditare la classe DiskScanner e implementare due metodi: feed (che prende un settore e la sua posizione come input) e get_partitions (che fornisce un array associativo di partizioni rilevate).
RecuperaBit utilizza un semplice file system astratto con due classi: File e Partition. Possono essere utilizzati direttamente, ma nella maggior parte dei casi questo non è sufficiente. Dovrebbero essere estesi per aggiungere attributi specifici del file system. Dovreste prestare particolare attenzione al metodo get_content, che può restituire i byte grezzi oppure un iteratore. Se il file è grande, è raccomandato un iteratore.
Il seguente file è una bozza di implementazione completa di uno scanner che rileva i settori con la parola chiave Ubuntu, suddividendoli in due “partizioni” (pari e dispari):
"""Ubuntu plug-in.
Un plug-in piuttosto inutile che rileva i settori con la parola 'Ubuntu'."""
from core_types import File, Partition, DiskScanner
from ..utils import sectors
class UbuntuFile(File):
"""Ubuntu File."""
def __init__(self, offset):
name = "Sector " + str(offset)
size = 0
is_dir = False
is_del = False
is_ghost = False
File.__init__(self, offset, name, size, is_dir, is_del, is_ghost)
self.set_parent("fakeID")
self.set_offset(offset)
def get_content(self, partition):
"""Estrai solo il settore, a scopo dimostrativo."""
image = DiskScanner.get_image(partition.scanner)
dump = sectors(image, File.get_offset(self), 1)
return str(dump)
class UbuntuPartition(Partition):
"""Partizione per tutti i fan di Ubuntu."""
def __init__(self, scanner, position=None):
Partition.__init__(self, 'Ubuntu', 10, scanner)
self.set_recoverable(True)
def additional_repr(self):
"""Restituisci valori addizionali da mostrare nella rappresentazione in stringa."""
return [
('Ubuntu version', '16.04')
]
class UbuntuScanner(DiskScanner):
"""Ubuntu Scanner."""
def __init__(self, pointer):
DiskScanner.__init__(self, pointer)
self.found_ubuntu = set()
def feed(self, index, sector):
"""Leggi un nuovo settore."""
# controlla il settore
if 'Ubuntu' in sector:
self.found_ubuntu.add(index)
return 'Ubuntu sector'
def get_partitions(self):
"""Ottieni una lista di partizioni trovate."""
partitioned_files = {
'pari': UbuntuPartition(self),
'dispari': UbuntuPartition(self)
}
for offset in self.found_ubuntu:
if offset % 2 == 0:
partitioned_files['pari'].add_file(UbuntuFile(offset))
else:
partitioned_files['dispari'].add_file(UbuntuFile(offset))
return partitioned_files
Salvate il file come ubuntu.py nella directory recuperabit/fs/. Aprite quindi il file main.py e aggiungete questa istruzione all’inizio:
from recuperabit.fs.ubuntu import UbuntuScanner
Infine, aggiornate l’elenco degli scanner:
plugins = (
NTFSScanner,
UbuntuScanner
)
Eseguite nuovamente il programma e questa volta dovreste vedere tre partizioni:
Notate come RecuperaBit ha ricostruito la struttura delle directory da solo, rilevando le tracce di una directory identificata da fakeID. I plug-in non hanno bisogno di implementare la ricostruzione dell’albero delle directory, in quanto è incorporata.
L’esempio fornito simula il contenuto dei file estraendo singoli settori, quindi potete testare anche il comando restore.
In futuro
L’analisi di NTFS è un’applicazione utile, tuttavia esistono anche altri tipi di file system molto comuni. Sarebbe interessante estendere il programma al fine di farlo funzionare anche per quelli.
Inoltre, la versione a riga di comando funziona bene per lo scripting e il testing, ma non tanto bene per opzioni avanzate (come scegliere quali file ripristinare). Ho in mente di lavorare a una GUI che renderà l’uso di RecuperaBit molto più facile. In futuro, potrebbe essere interessante considerare di pacchettizzare il programma per i sistemi operativi più comuni.
Fortunatamente, la natura open source di RecuperaBit consente a chiunque sia interessato di contribuire allo sviluppo o suggerire patch. Se state lavorando ad un’indagine e dovete cercare uno specifico tipo di dati, potete semplicemente modificare uno scanner o scriverne uno vostro!
Con l’avvento del web e delle nuove tecnologie i quotidiani hanno avuto la necessità di adattare il proprio format, reinventarsi e competere con altre forme di comunicazione come i video e i post sui social network. Nonostante questo, la carta stampata (vera o digitale) è ancora un mezzo utile per rimanere aggiornati sugli ultimi avvenimenti.
Quando si trovano in giro articoli o guide che parlano di leggere giornali e riviste gratis, purtroppo si va a parare molto spesso su siti di dubbia origine, dove si trovano copie pirata in PDF (o addirittura scansioni) delle varie testate. Se vi aspettate un articolo simile, rimarrete delusi.
In questo post desidero parlarvi di un metodo assolutamente legale, senza scaricare “a sbafo”, per leggere quotidiani e settimanali in modo gratuito e lecito. La soluzione a questo desiderio si trova in una risorsa che praticamente tutti noi abbiamo a disposizione anche se a volte non ci pensiamo: la biblioteca cittadina.
Ottenere una o più tessere
La prima cosa da fare per leggere i giornali in modo gratuito è l’unico passaggio di questa guida che richiede di recarsi fisicamente da qualche parte (solo una volta). Se non possedete già la tessera della biblioteca a voi più vicina, andateci e richiedetela.
Non dimenticate anche di informarvi sull’eventuale rete di biblioteche di cui fa parte la vostra. Il trucco per massimizzare i giornali che si possono leggere gratis è quello di avere accesso a più reti diverse.
Domandate anche come avere accesso alla risorse digitali.
Facendo un esempio pratico, io abito al confine tra la provincia di Vicenza e quella di Treviso. Entrambi i territori usano una rete provinciale, questo significa che bastano le tessere di due comuni per accedere rispettivamente a:
Ho deciso di registrarmi in una biblioteca per ciascuna provincia, perché tutte e due forniscono l’accesso a giornali e riviste differenti. Inoltre consentono di prendere in prestito gli e-book (ma non parlerò di questo).
Voi potete registrarvi alla biblioteca del comune dove vivete o lavorate… e se studiate all’università in una grande città (magari in una provincia diversa) conviene avere una tessera anche lì.
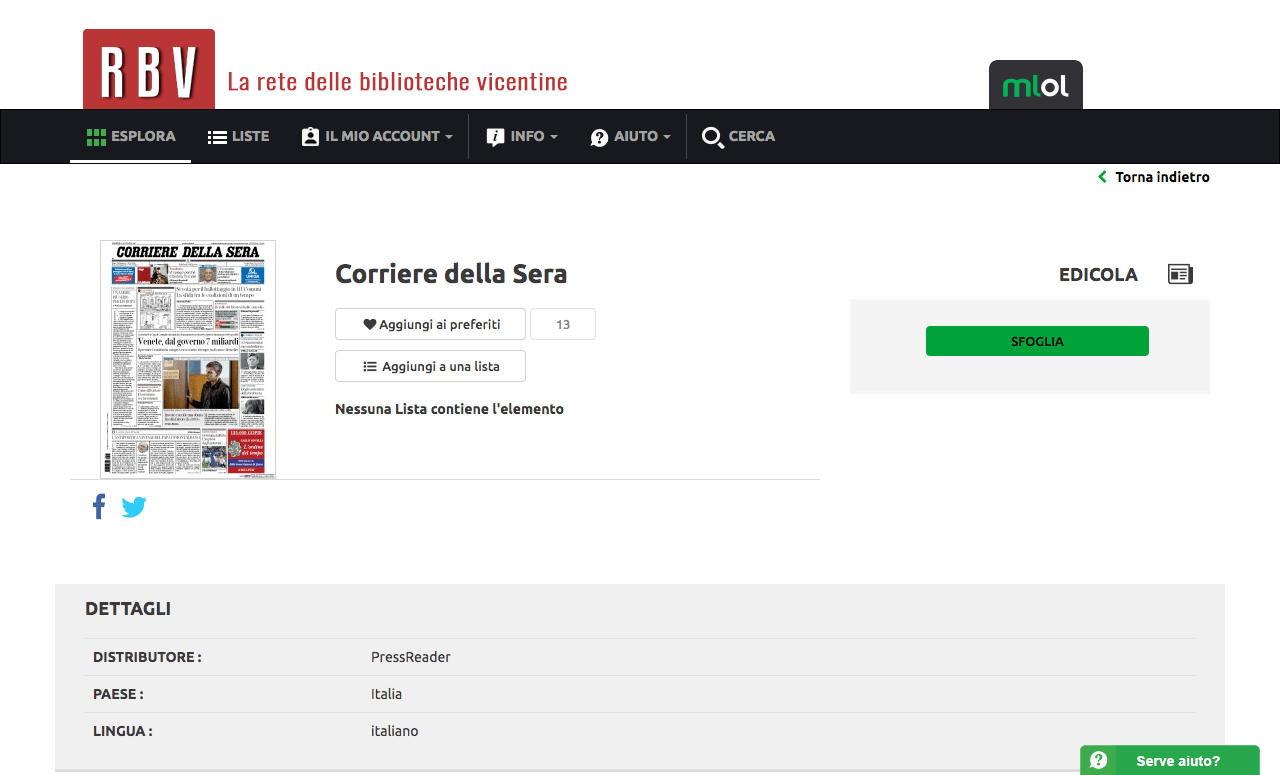
L’accesso alle risorse digitali può variare leggermente a seconda della biblioteca, ma generalmente si tratta solo di visitare il sito web e fare il login con i propri dati d’accesso. Quindi cercate la sezione chiamata “edicola” o quella con un nome simile. 🙂
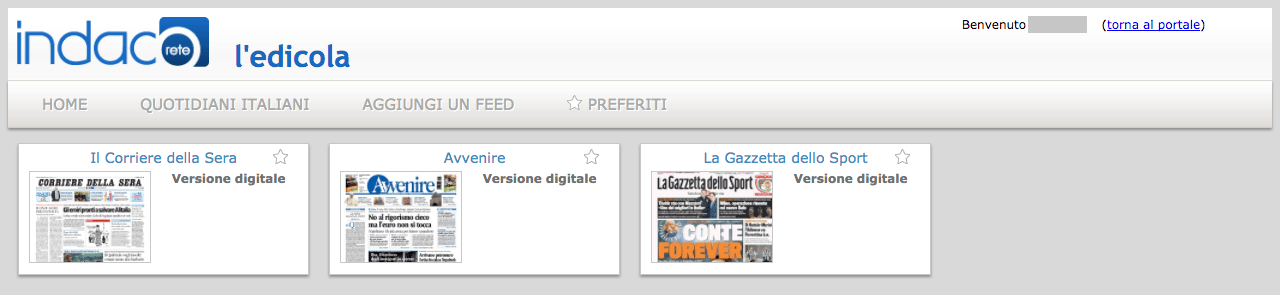
Una volta all’interno, potete vedere che ci sono “solo” tre quotidiani gratis:
Titoli disponibili per la lettura
Non sono tanti, però si tratta pur sempre di un bel risparmio se considerate che un singolo quotidiano può costare facilmente anche 200€ all’anno.
Cliccando sopra a una testata si apre la visualizzazione completa delle pagine e poi è possibile passare anche al testo degli articoli mostrato come se fosse un blog. Nelle figure seguenti trovate un esempio di entrambe le viste.
Bene, già così potete leggere tre quotidiani in modo completamente gratuito. Tuttavia potrete veramente leggere a più non posso utilizzando il portale di un ente che ha una convenzione con MediaLibrary Online, come ad esempio Biblioinrete.
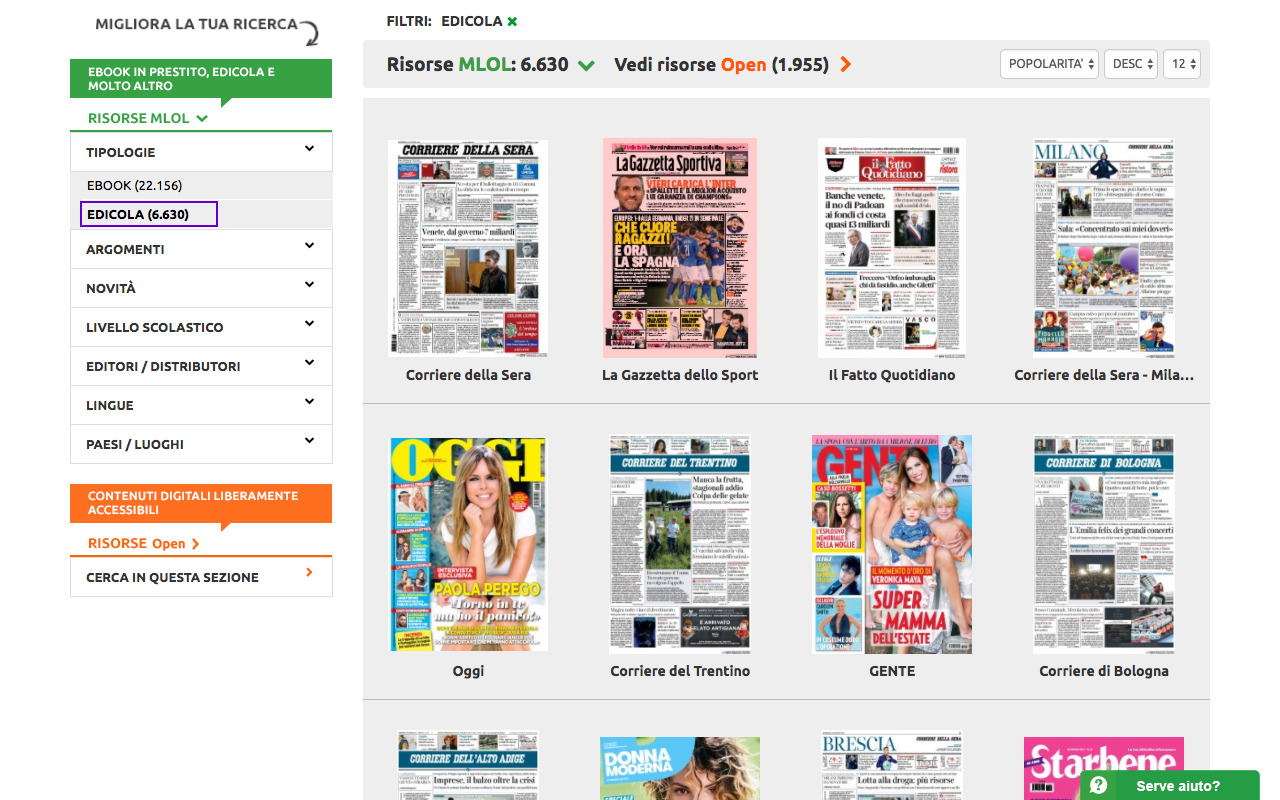
Per farvi un esempio, se utilizzate la convenzione tra le biblioteche vicentine e MediaLibrary Online vi basta effettuare l’accesso da questo portale dedicato. Una volta all’interno, filtrate le risorse per tipologia e vedrete un catalogo molto ricco:
Oltre 6600 risorse da tutto il mondo
Aprendo la scheda di un quotidiano potete notare che questa immensa disponibilità di titoli deriva dal fatto che MLOL è a sua volta arricchito da una partnership con PressReader, portale che fornisce giornali e riviste da moltissimi paesi:
Scheda di un quotidiano su MediaLibrary Online
Vi basta quindi premere il pulsante Sfoglia per accedere alla piattaforma di PressReader. È possibile creare un account ma non è obbligatorio, l’accesso viene già effettuato al vostro posto e potete navigare tranquillamente tra gli oltre 140 titoli (tra giornali e settimanali) del nostro paese. Se preferite potete visionare anche le testate estere. 😀
Potete visualizzare diverse schermate di MLOL nella gallery:
Conclusione
Le biblioteche italiane svolgono un ruolo straordinario nella diffusione e la preservazione della cultura. Con i tempi che corrono è finalmente possibile fruire di numerosissime risorse digitali in modo gratuito e legale.
Se desiderate leggere quotidiani e riviste risparmiando centinaia di euro all’anno sugli abbonamenti, non è assolutamente necessario (e non sarebbe giusto) affidarsi a siti pirata per poi magari trovarsi delle scansioni di scarsa qualità. Risulta molto più pratico fruire delle opportunità offerte dalle biblioteche, che sono lecite e ci consentono di sfruttare questo appropriato uso dei soldi pubblici.
Tra circa due settimane ci sarà un’importante occasione per riunirsi con molte persone appassionate di Linux e software libero, ovvero la DUCC-IT:
La Debian/Ubuntu Community Conference Italia 2017 (in breve DUCC-IT 2017) è la quinta edizione dell’evento annuale che riunisce le comunità italiane di Debian e Ubuntu ma anche e soprattutto tutte le realtà italiane attive nel Software Libero, allo scopo di scambiare conoscenze, discutere della situazione attuale e conoscere altri sviluppatori e membri della comunità.
L’evento si svolgerà il 6 e 7 maggio a Vicenza, precisamente a Villa Lattes. Personalmente mi fa molto piacere che una due giorni così interessante sia dalle mie parti e il programma è davvero ghiotto!
Io terrò un talk che farà da fanalino di coda alla domenica 😛 e tratterà della comunità di Ask Ubuntu, ovvero uno dei migliori luoghi virtuali dove parlare di Ubuntu e aiutarsi tra utilizzatori di questo ottimo sistema operativo:
Aiutare anche senza saper programmare
Ask Ubuntu è un sito Q&A (domanda e risposta) che raccoglie gli utenti di questa popolare distribuzione. Tramite un sistema collaborativo ed autogestito, tutti i partecipanti donano il proprio contributo per aiutarsi a vicenda e risolvere problemi o dubbi relativi all’uso di Ubuntu, portando beneficio a tutta la comunità.
Vi ricordo che l’evento è ad accesso libero e gratuito. Di seguito trovate alcune indicazioni utili, tra cui la pagina per prenotare il posto al ristorante (per chi vuole) entro il 28 aprile:
L’informatica è una scienza che troppo spesso viene fraintesa o male interpretata. Ci sono persone che usano e abusano il termine “informatica” o “informatico” per descrivere attività e professioni che poco hanno a che fare con questa disciplina. Il fatto che le cronache si riempiano di personaggi vari, presunti “esperti” di materie che non padroneggiano in modo approfondito, contribuisce a perpetrare questa scarsa consapevolezza di cosa sia davvero l’informatica.
Il problema più grosso, però, è che pochi parlano di informatica (intendo la scienza, quella vera) in modo divulgativo e dedicato ad un pubblico non esperto. Ci sono meravigliose trasmissioni televisive che parlano di fisica, chimica, biologia, geologia… ma manca sempre l’informatica.
Questo è il motivo che mi ha portato a organizzare, con l’associazione GrappaLUG, un itinerario culturale di dieci serate divulgative sull’informatica. Il mio obiettivo è quello di portare degli spunti, far conoscere al pubblico che cos’è questa scienza e magari scatenare la curiosità di qualcuno che potrebbe trovarla interessante. 🙂
Il percorso si intitola:
Dieci volti dell’Informatica Itinerario culturale di introduzione alla scienza dell’informazione
Questo giovedì (9 marzo) alle 21.15 ci sarà un incontro introduttivo in cui presenterò il programma dettagliato degli incontri. Cito dal sito dell’associazione:
In tale occasione si parlerà dello scopo per cui è stato ideato questo itinerario culturale, gli argomenti che verranno trattati, nonché date e orari delle dieci serate. La sera stessa apriranno le iscrizioni e i presenti potranno prenotare in anteprima il proprio posto.
Questa serie di incontri è dedicata ad un pubblico non esperto e non richiede specifiche conoscenze pregresse.
Se volete iscrivervi gratuitamente in anteprima non mancate, perché sul sito si potrà fare solo in seguito! 😀
Ho appena terminato il restyling della pagina Contatti del blog che ora è divisa in sezioni per renderla (spero) più chiara, esaustiva ed efficace. 🙂 La pagina ora è suddivisa in base alle richieste più frequenti che mi vengono poste:
Inoltre, ho aggiunto la pagina dei Servizi dove descrivo brevemente il lavoro che svolgo.
Perché questo cambiamento
In breve, ho fatto queste modifiche al sito perché alcuni mi scambiano per Google. 😛
Scherzi a parte, ci sono due ragioni fondamentali.
La frequenza dei contatti
Il primo motivo è che tenere un blog per una decina d’anni mi ha consentito di interagire con un sacco di persone che mi hanno scritto per scambiare idee, consigli, suggerimenti o semplici chiacchierate. Mi fa sempre piacere conversare con i miei lettori e vedere che ci sono persone che seguono assiduamente il blog e apprezzano quello che scrivo. 🙂
Negli ultimi mesi però ho notato che l’interazione con i lettori è rimasta più o meno costante, mentre sono aumentati i messaggi da persone che:
capitano sul blog per caso tramite un motore di ricerca
leggono un post o due
qualche volta evitano lo sforzo di capirlo o provare le indicazioni date
aprono la pagina Contatti e mi scrivono un’email
Insomma, sta diventando troppo rapido il passaggio Lettore occasionale → Domande tramite email, questo anche se il quesito è relativa ad un articolo e quindi ovviamente potremmo discuterne nei commenti così tutti i visitatori possono beneficiare.
Ogni tanto capitano anche persone che mi scrivono domandando di qualsiasi cosa possa vagamente riguardare un computer, dai messaggi di errore su Windows fino a tutorial scritti da altri blogger. 😀 Oppure mi chiedono di sviluppare script o software appositamente per loro, o di sistemare dei problemi col PC.
Qui veniamo al punto: sviluppare software è il mio lavoro. Fare consulenza anche.
I problemi nascono quando il numero di sconosciuti che mi scrive per domandarmi favori diventa piuttosto rilevante. Se qualcuno mi scrive per pormi dei problemi che necessitano di ricerche approfondite, questo richiede del tempo. Se una persona vuole farsi il sito in autonomia ma poi chiede a me ogni volta che ha un problema, in pratica mi sta chiedendo di insegnargli il mestiere.
Se vi sembra strano immaginare di telefonare a un falegname per chiedere istruzioni dettagliate quando tentate di costruire una casetta sull’albero, potete comprendere la mia necessità di differenziare le normali conversazioni via email dall’attività di consulenza o sviluppo software.
Certo che posso insegnarvi a realizzare un sito, darvi consigli e chiarimenti o realizzarvi un software su misura. È il mio lavoro. 😉
La visibilità per i potenziali clienti
La seconda ragione per cui ho risistemato le pagine è che prima le informazioni erano poche e frammentate. Pur avendo iniziato l’attività da circa un anno, ho già un buon numero di clienti e progetti in corso. Tuttavia, il sito non dava sostanzialmente nessuna idea sulla mia professione o sui servizi che posso fornire a privati e aziende.
Insomma, era poco evidente che chi lo desidera può contattarmi per lavori di sviluppo software o consulenza né quali sono i servizi in cui sono specializzato. Ora la situazione dovrebbe essere migliorata.
Se avete dei suggerimenti sulle nuove pagine o ritenete che manchi qualche informazione, lasciate pure un commento qui sotto. Per ogni richiesta di tipo professionale usate la nuova pagina Contatti.