
Questo post è una traduzione del mio articolo Extracting data from damaged NTFS drives pubblicato originariamente il 9 marzo 2017 sul blog di eForensics Magazine. Il testo descrive in modo dettagliato il mio lavoro di tesi magistrale sulla ricostruzione forense di file system NTFS con metadati danneggiati e il funzionamento di RecuperaBit.
L’articolo è fruibile liberamente e il software è open source, nonché estendibile tramite plug-in (c’è un esempio nell’ultima parte del post). Se avete bisogno di consulenza sul recupero dati o l’analisi forense di file system potete contattarmi tramite il modulo di richiesta per i miei servizi professionali.
Introduzione
L’analisi dei file system è una parte molto importante dell’attività di digital forensics. Molte indagini riguardano dischi rigidi il cui contenuto deve essere analizzato. In alcuni casi, anche i file eliminati potrebbero dover essere recuperati. Ci sono diversi tipi di file system e NTFS è attualmente uno dei più popolari.
La corruzione del file system può verificarsi per diversi motivi e può compromettere la possibilità di aprire e recuperare i file. Perciò, gli i tool forensi devono comprendere la struttura di un file system e devono essere in grado di estrarre il maggior numero possibile di dati, anche in condizioni difficili. Il file carving è una tecnica popolare per estrarre i file dai media danneggiati, tuttavia i file estratti in questo modo generalmente perdono i metadati e la struttura delle directory della partizione non può essere recuperata. È necessario un approccio migliore perché i nomi, i percorsi e i timestamp dei file sono informazioni molto importanti.
In questo articolo imparerete come la struttura delle directory di un’unità NTFS può essere ricostruita anche se alcune porzioni dei metadati sono parziali, corrotte o completamente assenti. Tutte le fasi del processo verranno spiegate. L’algoritmo presentato porta ad un’interpretazione del file system che consente il recupero di nomi, percorsi, timestamp e contenuto dei file (inclusi quelli frammentati). Infine, imparerete come utilizzare e personalizzare uno strumento open source che implementa queste tecniche.
Come funziona la ricostruzione di NTFS?
Prima di approfondire le tecniche che possono essere utilizzate per ricostruire una partizione NTFS, è necessario introdurre alcuni concetti. NTFS è un file system proprietario sviluppato da Microsoft e utilizzato per impostazione predefinita in Windows a partire da Windows 2000. È anche presente nei dischi rigidi esterni ad alta capacità, in quanto pure Linux e macOS lo supportano.
Funzionamento interno di NTFS
Il concetto principale di NTFS è che tutto è un file, vale a dire che anche i metadati necessari per funzionare sono memorizzati in diversi file. Il più importante è la MFT (Master File Table) che include almeno un file record (chiamato MFT entry) per ogni file o directory allocato/a. Ogni entry contiene diversi attributi. Per questo motivo, un file potrebbe avere più di una entry se i suoi attributi non possono essere inseriti tutti in una.
Questi sono gli attributi più importanti:
$STANDARD_INFORMATION(id 0x10 = 16) memorizza i MAC time (Modifica, Accesso e Creazione) nel formato più assurdo di sempre: il numero di cento nanosecondi dal 1° gennaio 1601 UTC$ATTRIBUTE_LIST(id 0x20 = 32) include i riferimenti alle non-base MFT entry che contengono altri attributi dello stesso file (se presenti)$FILE_NAME(id 0x30 = 48) memorizza più nomi di file: generalmente il nome del file DOS 8.3 e quello lungo utilizzato dalle versioni recenti di Windows, a meno che i due non siano uguali$DATA(id 0x80 = 128) include l’intero file se è inferiore a circa 700 byte, altrimenti dobbiamo fare riferimento alla runlist (un elenco che indica la posizione e la dimensione di ciascun frammento sul disco)$INDEX_ROOT(id 0x90 = 144, solo per le directory) contiene gli attributi$FILE_NAMEdi (alcuni) elementi figli$INDEX_ALLOCATION(id 0xA0 = 160, solo per le directory) si riferisce agli index record esterni memorizzati sul disco che registrano i riferimenti ai restanti elementi figli
I file record sono di dimensioni pari a 1 KB e possono essere riconosciuti perché iniziano con la firma FILE, o BAAD se il record è contrassegnato come danneggiato dal sistema operativo. Gli index record sono di 4 KB e la loro firma è INDX.
Infine, i primi e gli ultimi settori di una partizione NTFS sono due copie del boot record, che contiene questi parametri importanti:
- Settori per cluster (SPC), necessario perché gli indirizzi in NTFS sono espressi in cluster (gruppi di settori) e devono essere tradotti durante il ripristino di file o metadati
- Indirizzo di partenza della MFT, relativo al primo settore della partizione (a cui ci riferiamo con la dicitura Cluster Base o CB)
- Dimensione del file system, espressa in settori e cluster
Per una discussione dettagliata su come funziona NTFS, fate riferimento alla documentazione del progetto Linux-NTFS. Raccomando vivamente di leggere anche l’eccellente libro File System Forensic Analysis di Brian Carrier.
Fare il carving dei metadati
Normalmente, un sistema operativo inizia dal boot record, quindi salta alla MFT e inizia a leggere i file record e gli index record quando esplora l’intera struttura delle directory. Tuttavia, per eseguire una ricostruzione NTFS efficace, dobbiamo tenere presente che i metadati potrebbero essere parzialmente danneggiati:
- La tabella delle partizioni potrebbe essere sbagliata
- Potremmo non avere il boot record né il suo backup
- Alcune MFT entry e/o index record potrebbero non essere leggibili
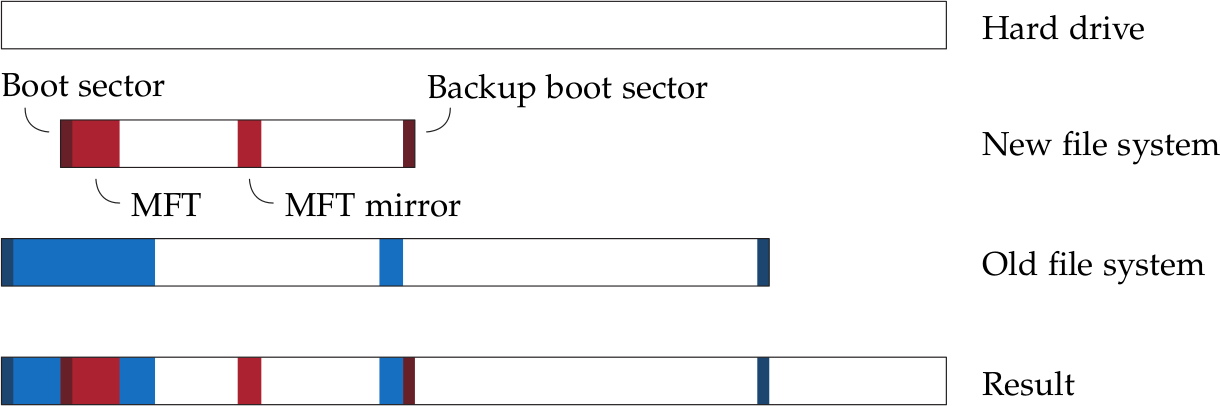
Per questi motivi, un approccio più sicuro a questo problema è supporre lo scenario peggiore. Invece di affidarsi alla tabella delle partizioni o al boot record di una partizione, il processo corretto è quello di scansionare l’intera unità cercando tracce dei boot record, dei file record e degli index record. Ciò consente di trovare anche le MFT entry di file cancellati recentemente.
Fondamentalmente, invece di fare carving dei file, lo effettuiamo sui metadati, raccogliendo i settori interessanti in tre liste.
Ciò fornisce un elenco di settori in cui i ci sono i potenziali file record, ma possono appartenere a partizioni diverse. Quindi, l’ultimo passo di questa fase è farne il clustering. Non possiamo contare sulla loro posizione perché la nostra ipotesi è che non sappiamo ancora dove si trovavano le partizioni (o le loro MFT), inoltre una partizione potrebbe essere stata parzialmente sovrascritta da un’altra.
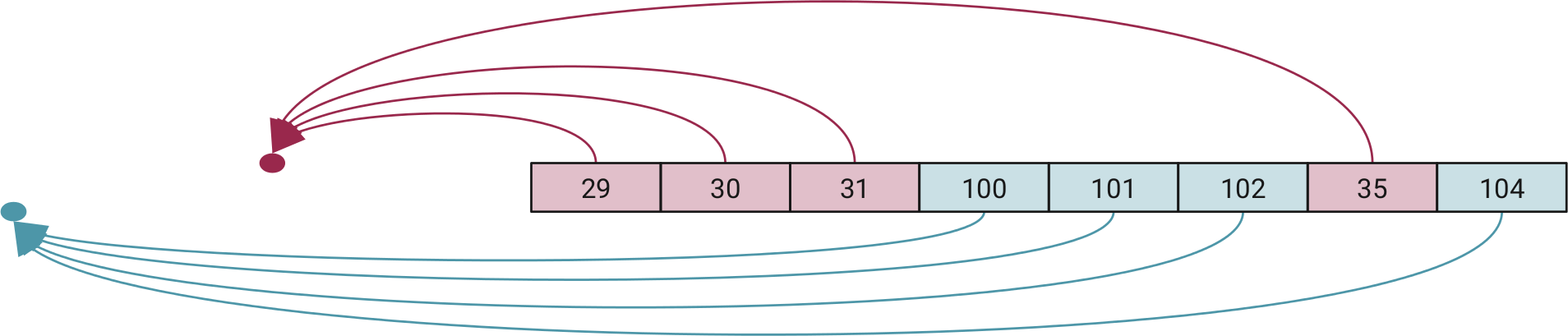
Possiamo tuttavia sfruttare il fatto che ogni file record contiene il proprio identificatore e che la MFT è generalmente contigua. Attraverso una semplice formula lineare, possiamo calcolare la posizione del corrispondente file record #0 per ogni file record che stiamo considerando:
p = y – 2x
Dove y è la posizione del record sul disco (in settori) e x è il record number. Possiamo quindi dividere i file record in base al loro valore p.
Ricostruzione bottom-up dell’albero
A questo punto abbiamo alcune “partizioni” che sono solo liste di file record. Non c’è ancora una struttura ad albero delle directory. Non possiamo leggere la struttura del file system dall’alto verso il basso, perché se mancasse un directory record, tutti i file sotto di esso sarebbero inaccessibili.
Al contrario, possiamo sfruttare il fatto che le MFT entry contengono anche l’identificatore della directory genitore. Inoltre, sappiamo che la directory principale in NTFS è sempre la #5. Possiamo procedere a ricostruire l’albero delle directory in modo bottom-up utilizzando un processo semplice.
Per ogni file:
- Se abbiamo trovato il record del suo genitore, colleghiamo il file al genitore
- Se conosciamo l’id del genitore ma non c’era un file record, creiamo un file record finto chiamato
Dir_[number]e colleghiamo ad esso il file - Se non conosciamo il genitore, colleghiamo il file a una directory
LostFiles - Se il file record è 5, consideriamo questa la radice del file system
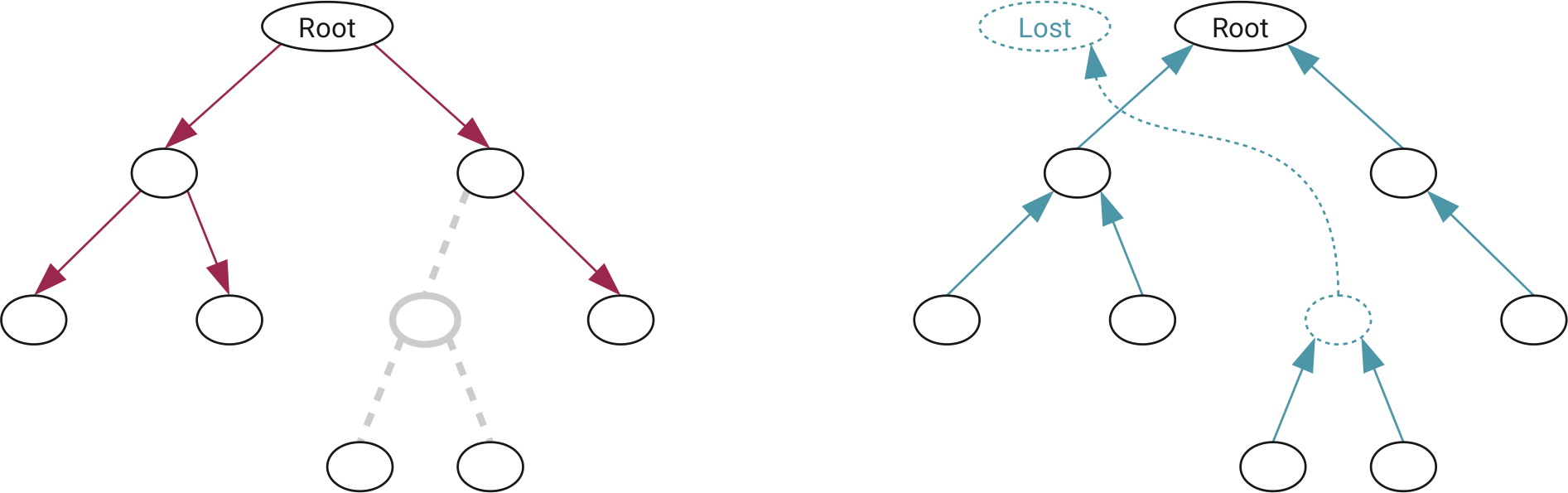
Come si può vedere, questo semplice processo non dipende dal tipo di file system e potrebbe essere applicato facilmente ad altri file system fintantoché i file record hanno un id e un puntatore al record genitore. Se manca il record di una directory, non è un grosso problema perché gliene creiamo uno che includa tutti i suoi figli. La directory mancante viene quindi inserita tra i file persi.
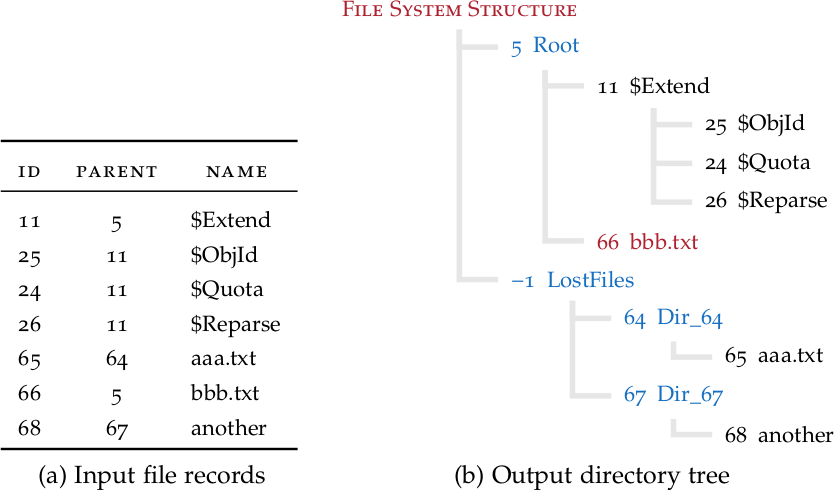
Fino ad ora non abbiamo considerato alcun index record. Ciò significa che l’approccio funzionerebbe anche se tutti gli index record non fossero disponibili. Tuttavia, l’albero risultante può essere completato con ulteriori informazioni su quelli che possiamo chiamare “file fantasma”. Questi sono file i cui record non sono stati trovati, ma la loro esistenza potrebbe essere determinata indirettamente da entry trovate negli index record.
I file fantasma non possono essere recuperati, ma il fatto che esistessero in passato potrebbe essere rilevante in un’indagine.
Individuare la geometria delle partizioni
Abbiamo visto come l’albero delle directory (o parti di esso) può essere ricostruito utilizzando i file record e gli index record. Ciò fornisce una rappresentazione accurata del file system, inclusi i nomi dei file, i timestamp e altri metadati rilevanti.
Questo è un ottimo risultato, tuttavia manca ancora un minuscolo dettaglio: il contenuto dei file.
I metadati sono sicuramente importanti, ma altrettanto lo sono i dati. Tutti i puntatori ei riferimenti in NTFS sono espressi in cluster e si riferiscono all’inizio della partizione. Dobbiamo trovare questi due parametri se vogliamo accedere ai file:
- Settori per cluster (SPC)
- Cluster base (CB)
Se abbiamo trovato un boot record che può essere collegato alle MFT entry che abbiamo, allora fila tutto liscio. Il parametro SPC viene scritto nel boot sector e il valore CB si ricava dalla sua posizione, o quella meno la dimensione della partizione se stavamo leggendo il boot record di backup.
Purtroppo, non possiamo fare affidamento sulla presenza del boot sector quando si tratta di hard disk danneggiati. Abbiamo bisogno di un modo per recuperare entrambi i parametri anche quando abbiamo solo file record e index record.
Possiamo sfruttare le informazioni contenute all’interno dei index record. Come abbiamo visto prima, gli index record contengono un elenco di attributi $FILE_NAME. Tra gli altri dati, questi contengono anche un riferimento alla directory genitore. Pertanto, per ogni index record possiamo stimare la directory a appartiene solo guardando le sue entry.
Ripetendo questo processo per tutti i record, possiamo trasformare il disco rigido in un “testo” in cui ogni lettera corrisponde ad un settore. Ogni settore ha uno spazio vuoto, ad eccezione di quelli che contengono un index record. In tal caso, lo spazio è riempito con l’id del suo proprietario.
Successivamente, consideriamo tutte le MFT entry delle directory che hanno almeno un attributo $INDEX_ALLOCATION. Dagli attributi, possiamo vedere in quale posizione (in cluster) dovrebbe essere un corrispondente index record. Se lo facciamo per tutte le MFT entry, abbiamo una “parola” le cui lettere corrispondono a cluster e contengono uno spazio vuoto o l’identificatore di una directory.
Quello che ancora non sappiamo è quanti ci settori sono in un cluster (SPC), ma possiamo tentare di indovinarlo. I valori validi sono piccole potenze di due, come 1, 2, 4, 8, 16, 32, 64 e 128. I più comuni in realtà sono 1 e 8.
Il nostro obiettivo è trovare il valore corretto di SPC, enumerando CB. Per ogni possibile valore di CB il processo consiste in:
- Convertire la “parola” da cluster a settori usando l’attuale valore di CB. Ad esempio,
[_, 6, 9, _, 2, 11]con SPC = 2 diventa[_, _, 6, _, 9, _, _, _, 2, _, 11, _]. - Fare matching della “parola” sul “testo” dato dagli index record trovati sul drive. Possiamo utilizzare una versione ottimizzata dell’algoritmo Baeza-Yates–Perleberg per lo string matching approssimato al fine di calcolare la posizione che fornisce la corrispondenza più accurata.
Questo fornisce un valore di CB per ogni possibile SPC. Il valore con la massima precisione calcolata durante il processo di matching vince. Se recuperiamo la geometria della partizione, possiamo estrarre tutti i file leggendo le loro MFT entry.
Inoltre, a questo punto possiamo verificare se alcune partizioni sono in realtà due parti della stessa partizione (che può succedere se la MFT è stata frammentata). In tal caso, le due parti possono essere fuse.
Gli algoritmi descritti qui sono discussi in dettaglio nel Capitolo 6 della mia tesi RecuperaBit: Forensic File System Reconstruction Given Partially Corrupted Metadata. Sono stati implementati con successo in uno strumento open source.
Ecco a voi RecuperaBit
RecuperaBit è un programma a riga di comando che ho sviluppato utilizzando tutte le tecniche descritte in precedenza. È un software libero e open source scritto in Python, pertanto è possibile studiarne il codice, estenderlo e personalizzarlo a seconda delle necessità.
Attualmente supporta solo NTFS, ma la sua architettura consente di aggiungere nuovi plug-in in futuro. Il programma tenta di ricostruire l’albero delle directory indipendentemente da:
- tabella delle partizioni mancante
- confini delle partizioni sconosciuti
- metadati parzialmente sovrascritti
- formattazione veloce
Installare il software
RecuperaBit può essere eseguito su Linux, Windows e macOS a condizione che Python 2.7 sia disponibile sul sistema. Durante l’ultimo hack camp ESC2016 a Venezia, è stato anche mostrato in esecuzione su un tablet Android rootato. L’installazione è molto semplice perché lo strumento è autonomo. Dovete solo scaricare l’archivio da GitHub e decomprimerlo, quindi invocare il file main.py.
Per ottenere la comodità di richiamare recuperabit dalla linea di comando è necessario un semplice collegamento simbolico. Su un sistema Linux, l’installazione può essere tanto facile quanto eseguire i seguenti comandi come root:
cd /opt git clone https://github.com/Lazza/RecuperaBit.git ln -s /opt/RecuperaBit/main.py /usr/local/bin/recuperabit
Ora è possibile visualizzare le istruzioni di utilizzo con:
recuperabit -h
Questo partirà con l’implementazione cPython predefinita. Per ottenere prestazioni più veloci, potete installare PyPy e modificare la shebang di main.py (che è la prima riga del file) in modo che faccia riferimento a /usr/bin/pypy.
Se state utilizzando il fantastico sistema Linux per l’informatica forense CAINE 8, sappiate che RecuperaBit è già incluso tra gli strumenti forniti nell’installazione predefinita, tuttavia non è facilmente disponibile dalla riga di comando a causa di un piccolo bug. Anche se su CAINE non è necessario scaricare RecuperaBit, potreste volerne creare un collegamento simbolico con il seguente comando:
ln -s /usr/share/caine/pacchetti/RecuperaBit/main.py /usr/local/bin/recuperabit
Tuttavia, tenere presente che alcune correzioni di bug per RecuperaBit sono state rilasciate dopo l’uscita di CAINE 8. Per questo motivo, suggerisco di installare l’ultima versione come descritto in precedenza, per evitare crash su file system particolarmente danneggiati.
Un esempio concreto
È possibile testare lo strumento su qualsiasi immagine di un disco rigido che contenga una partizione NTFS o alcune tracce di essa. Potreste perfino eseguirlo sul dump di una singola MFT entry e avreste comunque alcune informazioni di base, come il nome del file o l’id del file record.
Per questo articolo, useremo un esempio appositamente predisposto che è possibile scaricare qui. L’archivio compresso contiene un’immagine disco da 1 GB con un file system NTFS da qualche parte nel mezzo, utilizzando un insolito valore SPC di 16. Nessuna tabella delle partizioni è disponibile e i boot sector sono stati cancellati. Inoltre, anche le prime quattro voci della MFT e il relativo backup (che costituiscono la cosiddetta “MFT mirror”) sono andati perduti.
La directory principale conteneva i seguenti elementi:
- Una directory chiamata
othercon due sottodirectory:librarieseexecutablescontenenti un gruppo di file estratti da un’installazione di Ubuntu - Una directory chiamata
pictures, con inclusi dei file JPG e PNG - Una directory denominata
textscon più file di testo
Complessivamente, c’erano circa 500 file.
Supponendo che stiate lavorando nella directory in cui è stato salvato il file di immagine, è possibile passare il nome del file a RecuperaBit come argomento. È inoltre necessario specificare una directory di output e un nome di file per memorizzare l’elenco dei settori interessanti:
recuperabit borderless_1GB_v6.img -o recovered -s borderless.save
Il programma stamperà un breve riepilogo di cosa andrà a fare e attenderà fino a quando non premerete Enter. Procederà quindi alla scansione dell’unità e stamperà un registro dettagliato delle operazioni in corso. Alla fine, otterrete una primitiva linea di comando che potete utilizzare per analizzare ed estrarre le partizioni che sono state trovate.
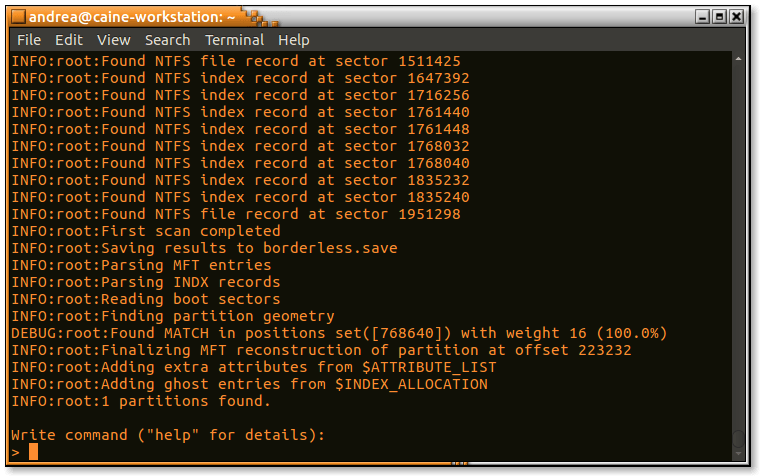
Si può vedere che RecuperaBit ha cercato di determinare la geometria della partizione anche se i boot record non erano disponibili, trovando una corrispondenza:
INFO:root:Finding partition geometry DEBUG:root:Found MATCH in positions set([768640]) with weight 16 (100.0%)
Se digitate recoverable al prompt, vedrete che sono state rilevate le informazioni di base sul file system danneggiato e che i file possono essere recuperati:
Partition #0 -> Partition (NTFS, ??? b, 517 files, Recoverable, Offset: 223232, Offset (b): 114294784, Sec/Clus: 16, MFT offset: 223264, MFT mirror offset: None)
A questo punto, potete estrarre ricorsivamente i file. La directory principale in NTFS ha l’identificatore 5 e la partizione che desiderate è la #0. Di conseguenza, potete eseguire:
restore 0 5
Questo comando estrarrà i file allocati e cancellati. Inoltre, creerà dei segnaposti vuoti per i file fantasma, se presenti. L’output sembra promettente:
INFO:root:Restoring #5 Root INFO:root:Restoring #64 Root/other INFO:root:Restoring #65 Root/other/executables INFO:root:Restoring #166 Root/other/executables/ping6 INFO:root:Restoring #167 Root/other/executables/plymouth INFO:root:Restoring #168 Root/other/executables/plymouth-upstart-bridge INFO:root:Restoring #146 Root/other/executables/networkctl INFO:root:Restoring #169 Root/other/executables/ps INFO:root:Restoring #170 Root/other/executables/pwd INFO:root:Restoring #171 Root/other/executables/rbash INFO:root:Restoring #172 Root/other/executables/readlink [... snip ...]
In alcuni casi, i file finiranno nella directory dei file persi, alla quale viene dato un id convenzionale pari a -1. In questo caso, potete eseguire anche restore 0 -1. Ora è il momento di guardare dentro la cartella recovered e verificare che cosa ha estratto RecuperaBit!
Con RecuperaBit potete ottenere anche:
- Una rappresentazione ad albero dei file (non fatelo su dischi grandi!), ad esempio:
tree 0 - Un elenco CSV dei file, ad esempio:
csv 0 contents.csv - Un body file che elenca tutti i file, ad esempio:
bodyfile 0 contents.body
Aggiungere un plug-in per un altro file system
Al momento, solo le partizioni NTFS possono essere scansionate utilizzando RecuperaBit. Tuttavia, è possibile scrivere nuovi plug-in per altri file system. Discutere il funzionamento interno di un file system come FAT o HFS+ sarebbe un compito molto difficile e non rientra nell’ambito di questo articolo. Tuttavia, descriverò brevemente ciò di cui avete bisogno per iniziare a scrivere un plug-in per RecuperaBit.
Il programma funziona dando in pasto ogni settore del disco a un insieme di scanner (ognuno dei quali è per un diverso tipo di file system). Uno scanner deve ereditare la classe DiskScanner e implementare due metodi: feed (che prende un settore e la sua posizione come input) e get_partitions (che fornisce un array associativo di partizioni rilevate).
RecuperaBit utilizza un semplice file system astratto con due classi: File e Partition. Possono essere utilizzati direttamente, ma nella maggior parte dei casi questo non è sufficiente. Dovrebbero essere estesi per aggiungere attributi specifici del file system. Dovreste prestare particolare attenzione al metodo get_content, che può restituire i byte grezzi oppure un iteratore. Se il file è grande, è raccomandato un iteratore.
Il seguente file è una bozza di implementazione completa di uno scanner che rileva i settori con la parola chiave Ubuntu, suddividendoli in due “partizioni” (pari e dispari):
"""Ubuntu plug-in.
Un plug-in piuttosto inutile che rileva i settori con la parola 'Ubuntu'."""
from core_types import File, Partition, DiskScanner
from ..utils import sectors
class UbuntuFile(File):
"""Ubuntu File."""
def __init__(self, offset):
name = "Sector " + str(offset)
size = 0
is_dir = False
is_del = False
is_ghost = False
File.__init__(self, offset, name, size, is_dir, is_del, is_ghost)
self.set_parent("fakeID")
self.set_offset(offset)
def get_content(self, partition):
"""Estrai solo il settore, a scopo dimostrativo."""
image = DiskScanner.get_image(partition.scanner)
dump = sectors(image, File.get_offset(self), 1)
return str(dump)
class UbuntuPartition(Partition):
"""Partizione per tutti i fan di Ubuntu."""
def __init__(self, scanner, position=None):
Partition.__init__(self, 'Ubuntu', 10, scanner)
self.set_recoverable(True)
def additional_repr(self):
"""Restituisci valori addizionali da mostrare nella rappresentazione in stringa."""
return [
('Ubuntu version', '16.04')
]
class UbuntuScanner(DiskScanner):
"""Ubuntu Scanner."""
def __init__(self, pointer):
DiskScanner.__init__(self, pointer)
self.found_ubuntu = set()
def feed(self, index, sector):
"""Leggi un nuovo settore."""
# controlla il settore
if 'Ubuntu' in sector:
self.found_ubuntu.add(index)
return 'Ubuntu sector'
def get_partitions(self):
"""Ottieni una lista di partizioni trovate."""
partitioned_files = {
'pari': UbuntuPartition(self),
'dispari': UbuntuPartition(self)
}
for offset in self.found_ubuntu:
if offset % 2 == 0:
partitioned_files['pari'].add_file(UbuntuFile(offset))
else:
partitioned_files['dispari'].add_file(UbuntuFile(offset))
return partitioned_files
Salvate il file come ubuntu.py nella directory recuperabit/fs/. Aprite quindi il file main.py e aggiungete questa istruzione all’inizio:
from recuperabit.fs.ubuntu import UbuntuScanner
Infine, aggiornate l’elenco degli scanner:
plugins = (
NTFSScanner,
UbuntuScanner
)
Eseguite nuovamente il programma e questa volta dovreste vedere tre partizioni:
> recoverable Partition #0 -> Partition (NTFS, ??? b, 517 files, Recoverable, Offset: 223232, Offset (b): 114294784, Sec/Clus: 16, MFT offset: 223264, MFT mirror offset: None) Partition #1 -> Partition (Ubuntu, ??? b, 10 files, Recoverable, Offset: None, Offset (b): None, Ubuntu version: 16.04) Partition #2 -> Partition (Ubuntu, ??? b, 14 files, Recoverable, Offset: None, Offset (b): None, Ubuntu version: 16.04)
Ora potete digitare tree 1 e controllare la struttura delle directory:
> tree 1
Rebuilding partition...
Done
----------
Root/ (Id: 10, Offset: None, Offset bytes: None) [GHOST]
LostFiles/ (Id: -1, Offset: None, Offset bytes: None) [GHOST]
Dir_fakeID/ (Id: fakeID, Offset: None, Offset bytes: None) [GHOST]
Sector 1251888 (Id: 1251888, Offset: 1251888, Offset bytes: 640966656, Size: 0.00 B)
Sector 834514 (Id: 834514, Offset: 834514, Offset bytes: 427271168, Size: 0.00 B)
Sector 978102 (Id: 978102, Offset: 978102, Offset bytes: 500788224, Size: 0.00 B)
Sector 224418 (Id: 224418, Offset: 224418, Offset bytes: 114902016, Size: 0.00 B)
Sector 224420 (Id: 224420, Offset: 224420, Offset bytes: 114903040, Size: 0.00 B)
Sector 1433746 (Id: 1433746, Offset: 1433746, Offset bytes: 734077952, Size: 0.00 B)
Sector 1631030 (Id: 1631030, Offset: 1631030, Offset bytes: 835087360, Size: 0.00 B)
Sector 1697158 (Id: 1697158, Offset: 1697158, Offset bytes: 868944896, Size: 0.00 B)
Sector 510918 (Id: 510918, Offset: 510918, Offset bytes: 261590016, Size: 0.00 B)
Sector 1492998 (Id: 1492998, Offset: 1492998, Offset bytes: 764414976, Size: 0.00 B)
----------
Notate come RecuperaBit ha ricostruito la struttura delle directory da solo, rilevando le tracce di una directory identificata da fakeID. I plug-in non hanno bisogno di implementare la ricostruzione dell’albero delle directory, in quanto è incorporata.
L’esempio fornito simula il contenuto dei file estraendo singoli settori, quindi potete testare anche il comando restore.
In futuro
L’analisi di NTFS è un’applicazione utile, tuttavia esistono anche altri tipi di file system molto comuni. Sarebbe interessante estendere il programma al fine di farlo funzionare anche per quelli.
Inoltre, la versione a riga di comando funziona bene per lo scripting e il testing, ma non tanto bene per opzioni avanzate (come scegliere quali file ripristinare). Ho in mente di lavorare a una GUI che renderà l’uso di RecuperaBit molto più facile. In futuro, potrebbe essere interessante considerare di pacchettizzare il programma per i sistemi operativi più comuni.
Fortunatamente, la natura open source di RecuperaBit consente a chiunque sia interessato di contribuire allo sviluppo o suggerire patch. Se state lavorando ad un’indagine e dovete cercare uno specifico tipo di dati, potete semplicemente modificare uno scanner o scriverne uno vostro!

Ottimo lavoro Lazza
Ti ringrazio! 🙂
Ciao, sto provando a usare il tuo ottimo RecuperaBit (ho anche seguito il tuo talk su youtube… molto interessante e vale le due ore di tempo necessarie a seguirlo!). Ad ogni modo sto cercando di recuperare tutti i dati presenti su un HD sata da 500GB partendo dalla sua immagine
ddrescue.Il problema è che l’output di recuperabit, nel mio caso, mostra moltissime partizioni con pochi file (oltre 40000 partizioni) e per recuperare tutto dovrei specificare per ciascuna partizione
restore xxx 5erestore xxx -1(dove xxx è il numero della partizione… oltre quarantamila, ribadisco…).La domanda è la seguente: come posso recuperare tutti i file da questa situazione? Inoltre come mai vedo tutte queste partizioni? anche solo scegliendo di visualizzare le recoverable sono tantissime…Posso forzare un recupero a tappeto o eventualmente mergiare facilmente con qualche wildcard nei comandi ?
Ti ringrazio per l’ottimo lavoro.
Lore.
Un breve cut & paste (MOLTO troncato…) di seguito, giusto per mostrarti la situazione:
No, in realtà ho già spiegato su GitHub perché questa è una pessima idea e perché non verrà inserita una funzionalità del genere. Si spreca un sacco di spazio e di tempo nel recuperare un numero abnorme di residui inutili, distogliendo l’attezione dall’obiettivo che rimane il recupero delle partizioni effettivamente in uso o magari cancellate da poco per sbaglio.
Perché l’algoritmo che fa il clustering funziona bene… e probabilmente hai tanti residui di vecchie deframmentazioni o cose del genere. Se poi avevi salvato qualche immagine di dischi NTFS o macchine virtuali non compresse anche quelle contribuiscono. 😉
Tornando al problema di partenza, concentrati solo sulle partizioni
recoverableche soddisfino una delle due seguenti condizioni:Per il secondo caso, solo le ultime tre che mi hai mostrato soddisfano il requisito:
Ma magari ce n’erano altre prima. Ho anche consigliato un filtro a un utente che si è trovato con 127000 partizioni. Credevi di avere il record? E invece no… 😛
L’interfaccia andrà rifatta un po’ meglio con qualche filtro in più, ma per ora questi suggerimenti dovrebbero permetterti di estrarre quello che effettivamente ti serve.
Ciao, grazie per la risposta.
In realta’ in attesa di un tuo feedback ho estratto tutto con photorec (con i limiti di questo programma) ed identificato alcuni file facendo dei grep a tappeto su tutto quanto estratto.Nel frattempo, mi e’ venuto in mente che se potessi lanciare recuperaBit in modalita’ batch ruescirei
ad avere l’output del programma rediretto in un file di testo e quindi ad identificare piu’ facilmente
le partizioni.
Attualmente l’output e’ talmente prolisso da essere troncato.
Nel caso non riuscissi ad ottenere un file di testo con tutte le info sulle partizioni
provero’ a cambiare terminale (magari usando terminator) in modo da settare come unlimited le linee memorizzate.
Ciao grazie
Lore
Vabbè ma quello è un carver, è una cosa completamente diversa.
Qualcosa tipo così dovrebbe andare:
Certo, puoi anche usare Byobu assicurandoti di impostare un limite di buffer adeguato, così puoi pure scorrere facilmente su e giù, nonché cercare l’output con pattern specifici. 🙂
Ciao, una info. Poichè non ho spazio sul pc per creare un’immagine di un disco da 1 TB purtroppo danneggiato 🙁 , è possibile scansionare direttamente il disco invece di indicare il file immagine? Quale dovrebbe essere la riga di comando?
Grazie anticipatamente
Sì, a livello teorico puoi passare direttamente il device sotto a
/dev/...(ovviamente devi essereroot). Comunque forse ti conviene fare un’immagine in EWF e dopo montarla conewfmount.Ciao Andrea ti ringrazio per la risposta. Poichè non sto utilizzando Linux, ma Windows 7 (ho già installato Python 2.7), ho provato ad inserire il percorso del disco con la seguente riga di comando dos:
ma ottengo errore. E’ come se non riconosce il disco D da scansionare. In cosa sbaglio?
Grazie
No be’, non può funzionare. Innanzitutto Windows non assegna le lettere ai dischi, ma le assegna a singole partizioni. In secondo luogo Windows non è un sistema Unix-like perciò non puoi trattare i dispositivi a blocchi come file.