Mi è stato proposto di partecipare all’ESC 2016 e di tenere un talk attinente al mio lavoro di tesi sul file system NTFS. ESC è un incontro di persone interessate al Software e Hardware Libero, all’Hacking, al DIY. Si tratta di un evento con contenuti in continua evoluzione, che vengono creati dai suoi partecipanti.
In particolare, ESC utilizza la formula del campeggio per riunire gli appassionati i quali poi possono assistere a talk e seminari, oltre a partecipare a laboratori vari e LAN party. I talk, caps e labs ufficiali saranno programmati da giovedì 1 a sabato 3 settembre, ma chi lo desidera può arrivare già mercoledì 31 e restare fino a domenica 4.
Il mio talk si svolgerà giovedì 1 settembre, di pomeriggio:
Giovedì 01/09/2016 — 15:00:00 Ricostruzione forense di NTFS con metadati parzialmente danneggiati
Andrea Lazzarotto (Lazza) Forte Bazzera (VE)
A seguito terrò anche un laboratorio dove mostrerò l’utilizzo pratico di RecuperaBit, il mio software per la ricostruzione di NTFS.
L’ingresso è gratuito, e da quest’anno anche il campeggio. Tuttavia, c’è un limite al numero di partecipanti. È quindi necessario pre-registrarsi obbligatoriamente in maniera da rispettare il criterio “primo arrivato, primo servito”.
Potete trovare tutti i dettagli riguardo all’evento, compresa la lunga lista di interessantissimi talk e laboratori sul sito di ESC 2016. 🙂
Vi siete mai trovati a condividere un link su Facebook e voler cambiare un po’ la card di anteprima che viene mostrata assieme al post? Magari l’immagine potrebbe essere sostituita con una migliore, oppure Facebook non è riuscito a individuare correttamente il titolo della pagina e il risultato è venuto proprio male.
A me è successo parecchie volte e fino a ieri non sapevo come risolvere il problema. Finché si tratta di condividere un link su una pagina, Facebook consente di correggere titolo, descrizione e immagine. Ma se si prova a condividere un link sul proprio profilo allora non c’è un metodo del tutto esplicito per ritoccarne i dettagli.
Il link di condivisione e i parametri personalizzati
Leggendo un po’ in rete, si trovano informazioni sul cosiddetto sharer, ovvero un link che si può inserire nel proprio sito web creando un pulsante Condividi su Facebook. L’utilizzo base è molto semplice, va solo inserito l’URL:
L’articolo che ho linkato poco più su è stato pubblicato a luglio 2014 e il titolo La finestra di condivisione di Facebook non accetta più parametri personalizzati non prometteva nulla di buono.
Ho deciso di provare lo stesso a trovare una soluzione, tirando a indovinare i termini più probabili. Alla fine ho trovato dei nuovi parametri per sostituire quelli precedenti:
Per dirla in modo garbato, costruirsi a mano i link in questo modo è un po’ uno stress, anche perché i parametri vanno codificati appropriatamente con il percent-encoding in quanto i caratteri speciali potrebbero causare problemi.
Ho creato un modulo facile facile che automatizza il tutto. Lo potete usare cliccando questo collegamento (potete anche trascinarlo nella barra dei segnalibri del vostro browser):
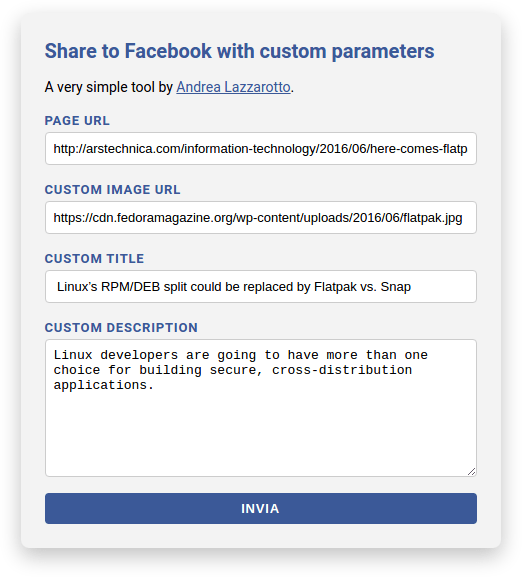
Per esempio, mettiamo il caso di voler condividere questo articolo di Ars Technica che parla della tecnologia Flatpak di Fedora e di come potrebbe diventare “concorrente” del formato Snap di Ubuntu. Il link condiviso normalmente su Facebook verrebbe così:
Link condiviso senza modificare i dati
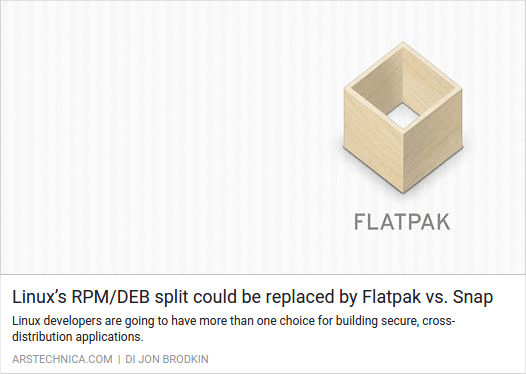
Per quanto io adori XKCD, non credo che quell’immagine sia proprio il massimo, e la vorrei rimpiazzare con questo bel logo di Flatpak trovato su Fedora Magazine. Già che ci sono, potrei volere correggere alcune maiuscole nel titolo e infine usare la prima frase dell’articolo come descrizione.
Devo solo inserire le informazioni nel modulo:
Utilizzo del modulo per creare un link personalizzato
Il risultato finale sarà esattamente come desiderato:
Link condiviso dopo aver modificato i dati
Ovviamente il modulo si può usare anche per fare qualche piccolo scherzo innocente, per esempio condividere un articolo dal sito ufficiale di Microsoft e cambiare il titolo in Linux è mille volte meglio di Windows, tanto lo sappiamo pure noi. Provare per credere. 😛
Il Veneto è una regione particolarmente fortunata: siamo la seconda in tutta Italia per numero di LUG (Gruppi di Utenti Linux), dopo la Lombardia. Questo è possibile grazie all’incessante lavoro dei membri di tante associazioni. Tuttavia, potete trovare dei LUG in tutta Italia: non lasciatevi sfuggire queste opportunità e seguite i siti web dei LUG più vicini a voi per essere informati sugli eventi e le attività che organizzano. Io personalmente partecipo alle attività del GrappaLUG di Bassano del Grappa (VI).
Il mio talk sulla ricostruzione di NTFS
Come vi avevo scritto qualche tempo fa, il 7 giugno sono stato ospite del LUG Vicenza per un talk relativo alla mia tesi di laurea magistrale e il mio software RecuperaBit. Ovviamente, se siete di queste parti andate a visitare il loro sito web perché fanno un sacco di ottime attività di grande interesse e utili per tutta la comunità.
Devo dire che fare un talk da loro è stata un’esperienza davvero piacevole. L’organizzazione è stata perfetta, incluso il modo in cui è stato registrato il video. Mi ha piacevolmente sorpreso avere la partecipazione di una delegazione del LugBS, con tre persone venute addirittura da Brescia. Ciò mi ha onorato particolarmente.
Quello che ho cercato di fare è stato spiegare l’argomento in modo non eccessivamente tecnico ma allo stesso tempo accurato. È sempre difficile essere precisi senza essere noiosi, ma almeno ci ho provato. 😀
Ecco un estratto di alcuni commenti ricevuti dai partecipanti:
La serata di ieri è stata interessantissima. La tua esposizione è stata chiara, precisa, professionale ed illuminante.
Alla fine hai mostrato in maniera pratica il funzionamento del tuo software che è risultato disarmantemente semplice da usare, ma potentissimo!
— Marco
Bellissimo assistere a:
una persona preparata che ha scritto un programma
per giunta ti spiega come ha ragionato e come lavora: te ne vai a casa con un maggior grado di consapevolezza invece che un utente “passivo” che adopera un programma ma che fa un atto di fede e si affida ad esso senza sapere come lavora
e poi la parte pratica! Non finirò mai di insistere su questo punto 😀 Grande valore aggiunto!
— Luigi
L’argomento era effettivamente molto tecnico ma è stato spiegato con molta scioltezza da una persona che conosceva l’argomento in modo approfondito. Io ed i miei colleghi sistemisti abbiamo più che apprezzato.
— Vincenzo
La difficoltà non era tra le più basse, ma è stato tutto spiegato bene e tutto sommato in maniera leggera e con slide divertenti. Personalmente non sapevo nemmeno cosa significasse la parola forense, adesso ho tante cose in più nel bagaglio.
— Alessandro
È chiaro che l’argomento trattato da Andrea non fosse di vastissimo interesse, anch’io non avrei mai pensato di aver necessità di recuperare dati da un HD, ma vi assicuro che quando ti capita, riuscire a trovare un software adatto e (soprattutto) una persona che ti dia le dritte giuste è oro colato!
— Stefano
Il video e il materiale
Per chi non può esserci fisicamente, il LUG Vicenza registra puntualmente i video dei talk e li pubblica online. La qualità del video è molto buona, specialmente perché l’audio è stato registrato con un microfono esterno e quindi non ci sono interferenze. 🙂
Questo è il video disponibile su YouTube:
Clicca qui per mostrare contenuto da YouTube. (leggi la privacy policy del servizio)
Di seguito invece trovate le slide pubblicate su SlideShare (cliccate qui per il PDF):
Clicca qui per mostrare contenuto da SlideShare. (leggi la privacy policy del servizio)
Per quanto riguarda il materiale che potete usare per i test, ne ho già parlato nel post precedente quindi potete leggere quello per maggiori dettagli.
Le prossime tappe
Ieri sera, come tutti i venerdì 17 che si rispettino, c’è stata la cena dei LUG veneti. Mi è stata fatta la proposta di riproporre un talk analogo a Schio (VI) presso l’AVi LUG e a Montebelluna (TV) presso il MontelLUG. Insomma, l’argomento sta diventando richiesto!
Naturalmente sono ancora idee e proposte non confermate, ma tenete d’occhio i loro siti… prima o poi potrei davvero fare un talk anche lì. 😉
Il 14 maggio io, Carlo e Claudio di GrappaLUG siamo stati invitati al Liceo G.B. Brocchi di Bassano del Grappa (VI) per tenere un talk a due classi prime. Il titolo del nostro intervento è anche quello di questo post: Come funziona Internet e perché il software libero è fondamentale.
Lo scopo, come si può intuire, era duplice. Innanzitutto volevamo cogliere l’occasione — fornitaci da un docente che ci ha invitato — e introdurre il concetto di software libero (che non vuol dire freeware!) ai ragazzi. L’altro aspetto che abbiamo voluto affrontare era una infarinatura su come funziona la rete Internet e perché senza Linux non potrebbe esistere il web come lo conosciamo oggi.
L’obiettivo dell’associazione è compiere una doverosa sensibilizzazione al software libero, a Linux, alla tutela della propria privacy e anche all’uso consapevole della tecnologia. Parlare di tutto questo in un’ora scarsa sembrava un’impresa ardua, ma le due classi si sono dimostrate molto interessate e ci hanno persino aiutati facendo delle domande davvero molto pertinenti e per nulla banali.
La parte che ho trattato io riguardava come il software libero aiuta a tutelare la propria privacy, favorire il mondo del lavoro e far funzionare il web. Parlare ai ragazzi e alle ragazze è stato interessante e a tratti divertente. Per esempio, ne ho stupito la maggior parte quando ho spiegato che “web” e “Internet” sono due cose diverse, e che il web è nato dopo. Per molti di noi questo è scontato, ma per altri può non esserlo.
Quando alla fine ho spiegato che tutto ciò è attivo di default in Windows 10, ci sono rimasti un po’ male. 😉
La slide che ha spaventato maggiormente gli studenti
Quando è stato il momento di parlare di prospettive occupazionali e di cosa significa “costruire” il web, non mi sono lasciato scappare il fatto che una classe era composta totalmente da ragazze e l’altra lo era in maggioranza.
Chi segue la mia pagina Facebook ormai sa che certi pregiudizi tardo-medievali sul fatto che l’informatica sia “un lavoro da uomini” mi fanno innervosire abbastanza. Il fatto è che, purtroppo, sono molto diffusi. Quindi ho pensato di approfittarne per chiarire (implicitamente) un po’ di cose con gli studenti che avevo di fronte.
Per esempio, sapevate che la persona che ha scritto il primo programma della storia era una donna? Be’, neanche loro. 🙂 Però adesso lo sanno.
Una citazione di Ada Lovelace che sintetizza brillantemente il senso di un buon algoritmo
Ho chiuso la presentazione mostrando un estratto di questa video intervista a Emily Gasca, ingegnere che lavora per Facebook. Se devo dirvi la verità, la cosa più simpatica di quella mattina è stata l’esclamazione scherzosa di un’alunna:
E chi me l’ha fatto fare di scegliere un percorso umanistico?
Impagabile. 😀
Ad ogni modo, quelli che ho menzionato sopra sono soltanto un paio dei punti che ho ritenuto più interessanti della mia parte. Potete vedere la presentazione intera, con tutte e tre le sezioni, su SlideShare e nel player qui sotto.
Se desiderate usare questa presentazione in qualche altra scuola e vi serve il file sorgente o lo spezzone del video, potete contattarmi senza problemi.
Clicca qui per mostrare contenuto da SlideShare. (leggi la privacy policy del servizio)
I più attenti tra voi avranno notato che ho aggiornato la mia pagina about, visto che circa due mesi fa ho conseguito la laurea magistrale. La mia tesi si intitola RecuperaBit: Forensic File System Reconstruction Given Partially Corrupted Metadata e tratta in particolare della ricostruzione della struttura delle partizioni NTFS, con la conseguenza di poter anche recuperare i dati.
Nella trattazione ho affrontato tutti gli aspetti essenziali di NTFS e ho proposto degli algoritmi di ricostruzione adatti anche a danni considerevoli. Oltre a ciò, ho anche pubblicato RecuperaBit, un software libero e open source che applica queste tecniche e si può usare davvero quando qualcosa va storto con un disco NTFS.
Per questo motivo, sono stato contattato dagli amici del Gruppo Utenti GNU/Linux di Vicenza che mi hanno chiesto di tenere un talk su questo argomento:
Recuperare dati da partizioni NTFS danneggiate
Martedì 7 giugno 2016, ore 21.00
NTFS è uno dei file system più diffusi, essendo quello usato di default dai sistemi Windows e anche negli hard disk esterni ad alta capacità. Quando accade un danno hardware o software, può verificarsi la corruzione di una o più partizioni, che diventano illeggibili.
In questo talk verrà presentato l’uso di RecuperaBit, software sviluppato dal relatore per la ricostruzione forense di NTFS e il recupero dei dati, anche con metadati parzialmente danneggiati.
La serata sarà composta anche da una parte pratica, in modo da permettere a tutti di poter provare i concetti che verranno spiegati. Vi riporto le note che abbiamo messo anche sul sito del LUG:
È inoltre necessario scaricare alcune immagini disco di esempio da questo link.
Il talk non è adatto a persone affette da intolleranza alla riga di comando. 😉
L’ingresso alla serata è libero e gratuito e non è prevista nessuna forma di registrazione. Chiaramente, sarei molto lieto di vedervi partecipare. Può darsi che in futuro io scriva un articolo più dettagliato sul software, ma questa è una serata pratica dove si potrà provare con mano e chiedere chiarimenti. Non perdetevi questa occasione! 🙂
Se c’è una cosa che mi fa venire i nervi sono i siti web che discriminano artificiosamente gli utenti Linux. Per qualche motivo, sembra che il fatto di usare un sistema operativo più veloce, più sicuro e più stabile ci debba rendere vittime di dispetti bizzarri.
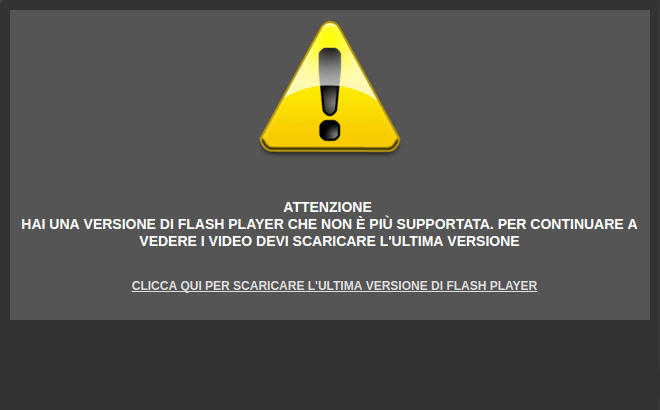
Poco tempo fa avevo parlato di MyMovies Live, ma recentemente mi sono imbattuto per caso sul portare Repubblica TV. Quello che ho visto è a dir poco incredibile: se proviamo a vedere un filmato, il portale ci risponde con un messaggio di errore.
Il discutibile messaggio di Repubblica TV
A prima vista potrebbe sembrare un avvertimento che ci ricorda di avere una versione vecchia di Flash Player, per qualche motivo. Peccato che questo messaggio compaia anche con la versione 21.0.0.213… che è l’ultima su tutte le piattaforme.
Guardando un attimo la struttura della pagina ho visto che, in realtà, ogni video di Repubblica TV è soltanto un semplicissimo file MP4. Oltre al danno, anche la beffa: infatti non servirebbe nessun plug-in per vedere i filmati.
Ho trovato questa cosa abbastanza snervante, per di più considerando il fatto che è possibile risolverla con pochissime righe di codice.
Infatti, è la prima volta che ho scritto uno script per un sito web digitando solamente 4 righe di Javascript, che sono andate al primo colpo senza nemmeno testarle. Questo mi rende davvero sbigottito e mi chiedo come mai Repubblica non possa fare una modifica così ovvia al portale per renderlo fruibile a tutti, senza dover usare un plug-in obsoleto e poco sicuro come Flash Player.
Ad ogni modo, col mio script si ottiene questo risultato:
Video riprodotto direttamente in MP4 su Repubblica TV
Analogamente a quanto fatto per Rai, Mediaset, La7, RSI e BBC, ho pubblicato online lo script. In questo modo potete attivare la visione dei video anche nel vostro browser. 🙂 Vi ricordo che per installare gli script bisogna avere un’estensione per il browser:
un paio di esempi di locandine finite (quella dell’evento e quella abbozzata durante la serata stessa)
del materiale integrativo che riassume i passi fondamentali compiuti per raggiungere il nostro scopo
In particolare, ho cercato di semplificare fino all’osso una correzione base delle fotografie limitata a colori e luminosità, che già coprono la maggior parte del necessario. Per Inkscape, invece, la cosa fondamentale è impostare inizialmente la pagina, inserendo una griglia, qualche guida e i segni per la stampa.
Questi semplici accorgimenti consentono anche ai principianti di ottenere un flusso di lavoro completo, dallo scatto al volantino, appunto. Per un riassunto veloce, vi invito a vedere le slide scaricabili dal sito di AViLUG.
Tuttavia, ho ritenuto opportuno scrivere anche una descrizione dei passaggi fondamentali sotto forma di istruzioni, per maggiore chiarezza. Questo mi ha consentito anche di inserire parecchi link e spunti per approfondimenti personali. Ci tenevo particolarmente perché sono delle risorse ottime e aiutano a capire bene i concetti che ho concentrato in due ore di spiegazione.
Pertanto, riporto qui di seguito il riassunto della serata inserito anche nei materiali linkati sopra. In questo modo sarà più raggiungibile da chi cerca informazioni su questo argomento, rispetto a un documento chiuso dentro a un file ZIP.
Prima di leggere l’approfondimento, però, guardate le slide:
Clicca qui per mostrare contenuto da SlideShare. (leggi la privacy policy del servizio)
Dallo scatto al volantino (Materiale integrativo)
Prima di tutto vorrei ringraziare AViLUG per l’opportunità di presentare il talk e il pubblico per la partecipazione e i commenti utili. Sono contento di aver ricevuto dei feedback positivi relativi alla serata.
Tra i suggerimenti più popolari c’è stato quello di fare un talk più corto rispetto alle 2 ore utilizzate. È vero, la serata è stata abbastanza dettagliata, però l’obiettivo era fornirvi un flusso di lavoro completo e delle istruzioni che fossero realmente applicabili. Avrei potuto probabilmente saltare delle spiegazioni e alcuni passaggi, ma sono convinto che dire “fate così” senza spiegare perché sia meno comprensibile e meno utile.
Un altro suggerimento è stato quello di introdurre delle esercitazioni pratiche in loco. Questa è senza dubbio una bella idea che si potrebbe applicare avendo più tempo, per esempio con una sessione pomeridiana di 3-4 ore. Oltre a questo, l’esperienza di altri corsi con GrappaLUG mi ha insegnato che è utile avere un affiancamento “1 a 1” affinché si ottenga il massimo risultato.
Purtroppo questo non era possibile durante la serata del talk, però invito tutti gli interessati a postare i propri quesiti sul forum di Gimp Italia dove potranno ricevere la giusta attenzione e le risposte dei numerosi appassionati che popolano il forum.
Il seguito di questo documento ha lo scopo di riassumere quello che è stato mostrato nella seconda parte della serata (gli esempi pratici) e includere dei link a delle risorse utili per approfondire. Per la parte più teorica vi rimando alle slide.
Correzione delle foto
Nota: è consigliabile lavorare con la versione beta di GIMP 2.9 perché ha alcune funzioni in più rispetto alla 2.8. In ogni caso, i suggerimenti qui riportati si possono applicare anche con programmi simili, per esempio Krita.
Abbiamo visto essenzialmente due aspetti relativi alle foto:
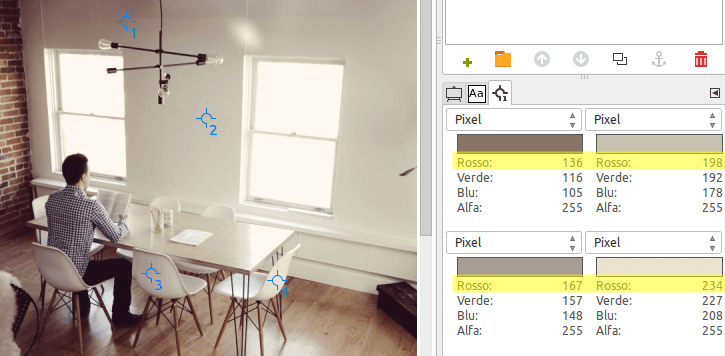
Per quanto riguarda i colori, abbiamo visto che i punti grigi devono avere i 3 valori RGB uguali. Per questo motivo, abbiamo creato un duplicato del livello su cui lavorare. Abbiamo messo dei punti di campionamento sull’immagine e poi abbiamo usato le curve per portare questi punti ad essere realmente grigi.
Verifica della dominante con i punti di campionamento
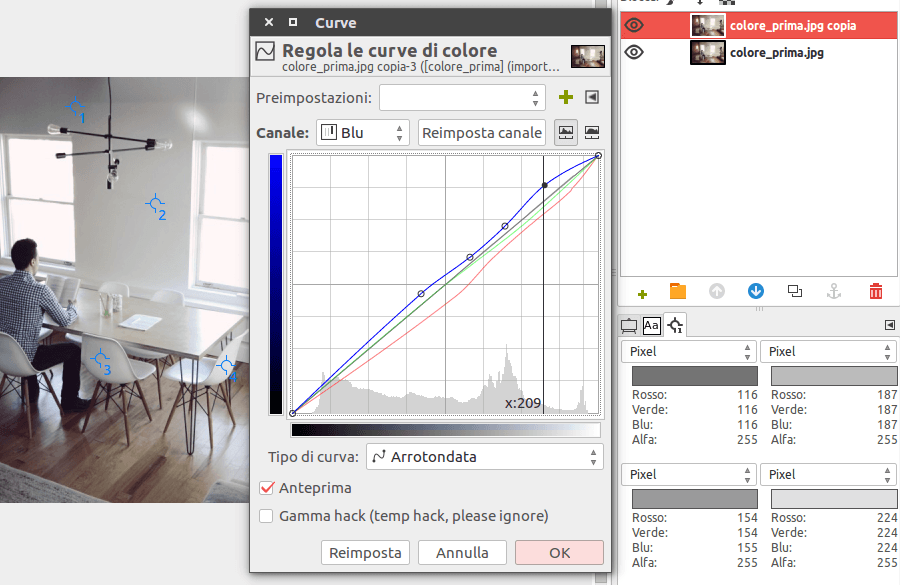
I tre canali sono stati regolati con le curve:
Regolazione dei punti di grigio con le curve
Nota: in genere sarebbe raccomandabile regolare i grigi considerando anche dei punti con dei grigi più scuri (non mostrati in questo esempio).
Infine, il livello soprastante è stato impostato in modalità Colore per evitare di modificare la luminosità. I due livelli sono stati fusi insieme per ottenere il risultato finale.
Foto con i colori corretti
Approfondimento
Questo argomento è trattato in modo eccellente in questo articolo di Andrea Olivotto. L’autore mostra in modo alternato sia GIMP che Photoshop, ma i concetti sono analoghi.
Luminosità
Per la luminosità abbiamo lavorato sempre su una copia del livello di partenza (con i colori già corretti) e abbiamo fatto questi passi:
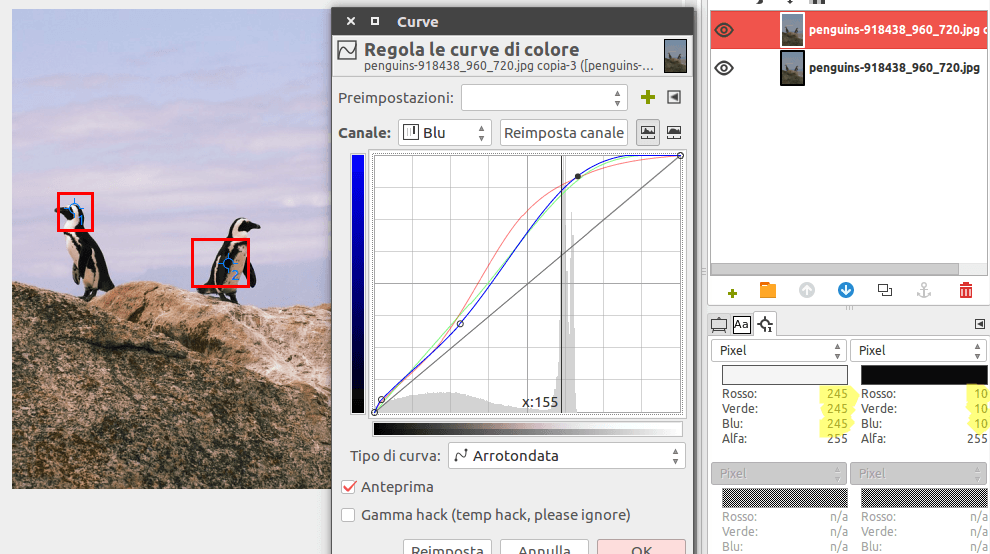
uso dello strumento soglia per trovare il punto più chiaro e quello più scuro
uso delle curve per portare il nero a (10, 10, 10) e il bianco a (245, 245, 245) ignorando eventuali alterazioni del colore
curva a forma di “S” e utilizzo dei canali scomposti per aumentare il contrasto ulteriormente (opzionale)
Il bianco, il nero e il contrasto sono stati regolati con le curve:
Regolazione del punto di bianco, del punto di nero e del contrasto
Infine, il livello superiore è stato messo in modalità Luminosità per ripristinare i colori corretti.
Foto con la luminosità corretta
Approfondimento
Normalmente i due passaggi (colori e luminosità) si applicano in sequenza sulla stessa foto, ma per rendere gli esempi più chiari ho scelto due immagini in cui ci fosse un solo problema da correggere in modo prevalente.
Durante la serata ho anche accennato a come si possa usare lo spazio colore LAB per aumentare la vivacità dei colori. Questo articolo di Helen Bradley riassume i pochi passaggi necessari.
Mentre per i colori è chiaro quando un punto è grigio e quando non lo è, per la luminosità e il contrasto non c’è una unica soluzione “giusta” e probabilmente ogni volta che proverete su una stessa immagine otterrete curve di contrasto diverse. L’importante è utilizzare il proprio giudizio cercando di capire quale risultato si vuole ottenere e quali parti della foto si vogliono esaltare.
Grafica vettoriale
Per quanto riguarda Inkscape, abbiamo visto le funzioni di base. In effetti c’erano meno cose da dire, perché con la grafica vettoriale bastano pochi concetti essenziali per produrre lavori gradevoli.
Innanzitutto abbiamo predisposto la pagina impostando la griglia e le guide e poi i segni di registro (“crocini”) per la stampa. Solitamente si usano 3mm di abbondanza, ma eventualmente domandate a chi dovrà stampare il documento finale.
Un’altra funzione utile per creare le guide è data dal poter convertire un rettangolo in 4 guide usando il menu Oggetto » Da oggetto a guida. Ciò consente di prepararsi facilmente varie “colonne” verticali dove si può allineare il testo.
Le immagini si possono inserire con il semplice drag’n’drop e va scelto se incorporarle (dentro al documento SVG, con più peso ma maggiore portabilità) o collegarle (tenendo il documento leggero ma dovendo dipendere dal file originale che non va spostato né cancellato). Si possono tagliare o mascherare in diversi modi usando le maschere.
In Inkscape tutti gli oggetti sono spostabili indipendentemente, quindi il concetto di “livello” è meno importante. Però si può decidere di mettere gli elementi di sfondo su un livello sottostante e poi bloccarlo così non danno fastidio mentre si lavora sul testo.
Infine, per quanto riguarda il testo ci sono diverse opzioni:
il testo semplice
quello su tracciato (menu Testo » Metti su tracciato)
quello in struttura (menu Testo » Fluisci in struttura)
Il testo semplice si usa per scritte brevi o magari titoli, mentre quello in struttura è utile per far scorrere dei paragrafi in un rettangolo o altre forme geometriche.
Vi consiglio di creare prima il rettangolo con un colore di sfondo visibile (magari semi-trasparente) e poi renderlo invisibile solo dopo averci fatto fluire dentro il testo ed essere sicuri che vada bene.
Il testo semplice si può ritoccare in molti modi per quanto riguarda la posizione delle singole lettere. Consultate l’ultima parte del tutorial avanzato su Inkscape per maggiori dettagli.
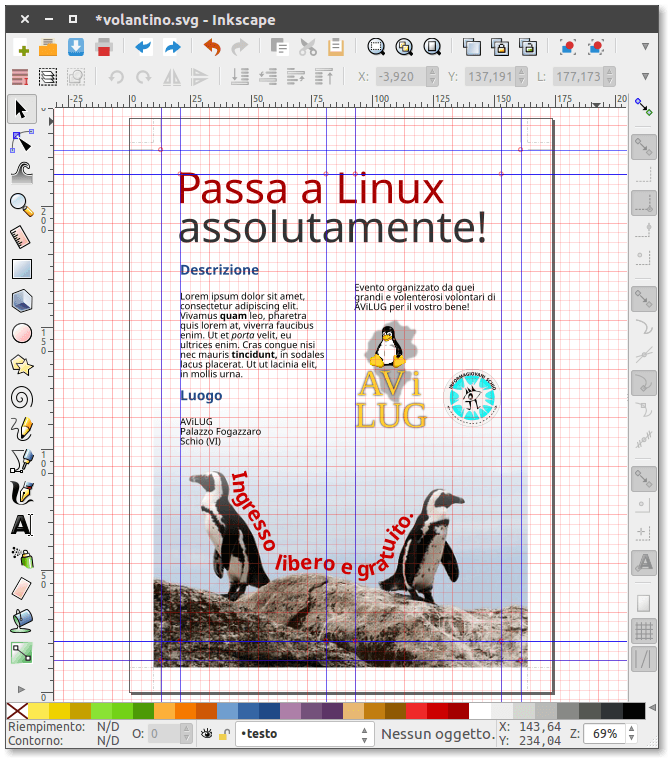
Per vedere in azione questi elementi base (griglia, guide, immagini e testi) la cosa migliore è aprire il file SVG di esempio fornito per questa serata ed esplorare come è fatto:
Volantino prodotto durante la serata
Approfondimenti
Per chi non ha problemi con l’inglese, il metodo più veloce e pratico per imparare Inkscape è seguire i favolosi video tutorial di HeathenX. Ognuno dei 106 episodi contiene il link al video OGV in basso, per guardarlo direttamente online o scaricarlo.
Sono stato invitato dagli amici di un fantastico LUG (Gruppo Utenti Linux) del vicentino per tenere una serata sulla grafica vettoriale e l’uso di Inkscape. Sto parlando di AViLUG, un’associazione che opera a Schio (VI).
Dallo scatto al volantino
Correggere le foto e utilizzare la grafica vettoriale
Il talk verterà principalmente sul vettoriale, ma è innegabile che la creazione di brochure, volantini e altri materiali spesso coinvolga anche le foto. Per questo motivo tratterò un piccolo flusso di lavoro completo. Partiremo dalla correzione dei colori delle fotografie con GIMP, per poi passare all’uso di Inkscape per disporre i testi e gli elementi grafici sulla pagina.
Volantino della serata
Qui a fianco potete vedere il flyer in formato A5. In particolare, vi cito la parte che descrive gli argomenti trattati.
Durante la serata si parlerà di:
correzione di luminosità e colori delle foto
strutturazione della pagina
organizzazione del testo
predisposizione del documento per la stampa
Chiaramente l’ho disegnato con Inkscape, quindi potete avere un’anteprima di cosa potrete realizzare con le spiegazioni che fornirò. 🙂
La serata si svolgerà in un’aula dalla capienza limitata. Ci sono solamente 25 posti a disposizione. L’ingresso è gratuito ma è obbligatoria la registrazione su Eventbrite. Eccovi i link per maggiori informazioni e per la prenotazione:
Durante il periodo natalizio ho ricevuto questa domanda da parte di un lettore:
Come vedere i filmati da MyMovies Live su Ubuntu? Si può fare?
Dopo una breve verifica, ho scoperto che questo servizio mostra i filmati usando la tecnologia Flash. Quindi in teoria dovrebbe funzionare senza problemi su tutti i sistemi operativi. In realtà, i requisiti tecnici riportati sono:
Flash Player è sostanzialmente identico su tutte le piattaforme, quindi non ci sono scuse. Senza giri di parole, MyMovies non ha cura di chi sceglie soluzioni di qualità come Linux. Siti web come Rai Replay, Video Mediaset, La7, Hulu e BBC iPlayer funzionano con Linux senza troppi problemi.
Se si tenta di visualizzare un film (ad esempio questo documentario), si ottiene il seguente errore:
Errore di riproduzione su MyMovies Live
La soluzione è quella di installare una copia di Firefox e Flash Player per Windows, però sempre all’interno del vostro sistema Linux. 😀
Wine e PlayOnLinux
Wine è un progetto imponente che da anni consente di utilizzare moltissimi software per Windows su piattaforma Linux. La compatibilità è ottima per numerosi programmi, tra cui Firefox e Flash (che interessano a noi).
PlayOnLinux è un’applicazione che fornisce una comoda interfaccia a Wine, permettendo di gestire diversi programmi installati in più “unità virtuali”, cioè finti hard disk con finte installazioni di Windows. Il bello è che contiene già una lista di programmi “preconfigurati”, cioè con degli script che automatizzano l’installazione e la configurazione senza farla manualmente.
Perciò, vi consiglio di installare PlayOnLinux dal vostro gestore software (per esempio Ubuntu Software Center) e usarlo come interfaccia “facile” a Wine, in modo da ottenere il massimo risultato con il minimo sforzo. 😉
Fatto ciò, passiamo all’installazione vera e propria di Firefox.
Installare Firefox per Windows
Aprite PlayOnLinux e cliccate sul bottone + Installa. Apparirà una lista di applicazioni, voi scegliete la sezione Internet e quindi Mozilla Firefox, infine Installa. La procedura di installazione guidata somiglia all’installazione dei programmi per Windows, quindi dovrete premere Avanti alcune volte. 😉
La cosa importante è fare attenzione alle domande:
Metodo di installazione: scegliete Scaricando il programma
Lingua: presumibilmente vorrete l’italiano
Componenti addizionali: spuntate la casella Flash Player
Dovete quindi armarvi di un po’ di pazienza mentre il programma scarica automaticamente i componenti necessari e avvia l’installazione di Firefox.
Installazione di Firefox tramite PlayOnLinux
Finita questa prima fase, il browser si avvierà. Ora attendete senza fare nulla! PlayOnLinux infatti scaricherà il programma di installazione di Flash Player in pochi secondi e lo farà partire.
Installazione di Flash Player tramite PlayOnLinux
Dopo aver installato Flash Player, non sarà necessario neppure chiudere il browser. Aprite un video di MyMovies Live (per esempio il documentario che ho linkato prima) e potrete guardare il film senza fastidi. 😀
Visione di un film su MyMovies Live
Dall’immagine che ho messo non si può vedere, ma sia l’audio che la funzione schermo intero funzionano correttamente.
Come ultima cosa, preciso che usare PlayOnLinux con lo script per Firefox installerà anche un’altra copia di Wine. È infatti possibile averne più di una. Se questo vi da fastidio, PlayOnLinux contiene un gestore di versioni di Wine per rimuovere quelle aggiuntive.
Inoltre, potreste voler pulire i file temporanei creati in queste due cartelle nascoste nella vostra home:
.PlayOnLinux/ressources # sì, con 2 "esse"
.PlayOnLinux/tmp
Quest’ultimo passo non è obbligatorio, l’ho messo solo per completezza d’informazione. 😉 Potete anche cancellare l’icona di Firefox che viene creata sul vostro desktop, e avviarlo direttamente dal menu di PlayOnLinux quando vi serve.
MyMovies Live è il primo sito web con Flash che si lamenta opponendosi agli utenti Linux. Tuttavia, non escludo esistano anche altri siti “problematici” e discriminatori che probabilmente si riescono ad usare con lo stesso metodo. Se ne siete a conoscenza, fatemelo sapere. 😀
Il DNS è un servizio alla base di Internet. Si tratta di un server a cui il nostro computer chiede l’indirizzo IP di un sito. Infatti, i siti web sono identificati da un nome di dominio (per esempio www.andrealazzarotto.com) ma questo va tradotto in un indirizzo numerico, affinché il computer si possa collegare.
Funziona così (per semplificare):
Computer: Ciao! C’è qui il mio utilizzatore che vorrebbe visitare Google.com, mi dai l’IP?
Server DNS: Certamente, è 173.194.112.33!
In genere, il nostro router gestisce le richieste DNS verso il server che ci dà il nostro fornitore di accesso a Internet. I nostri computer fanno invece una richiesta DNS al router, quindi collegandosi ad un indirizzo tipo 192.168.0.1 (o comunque l’indirizzo del router) ed è il router che poi si arrangia a trovare la risposta prima di restituirla.
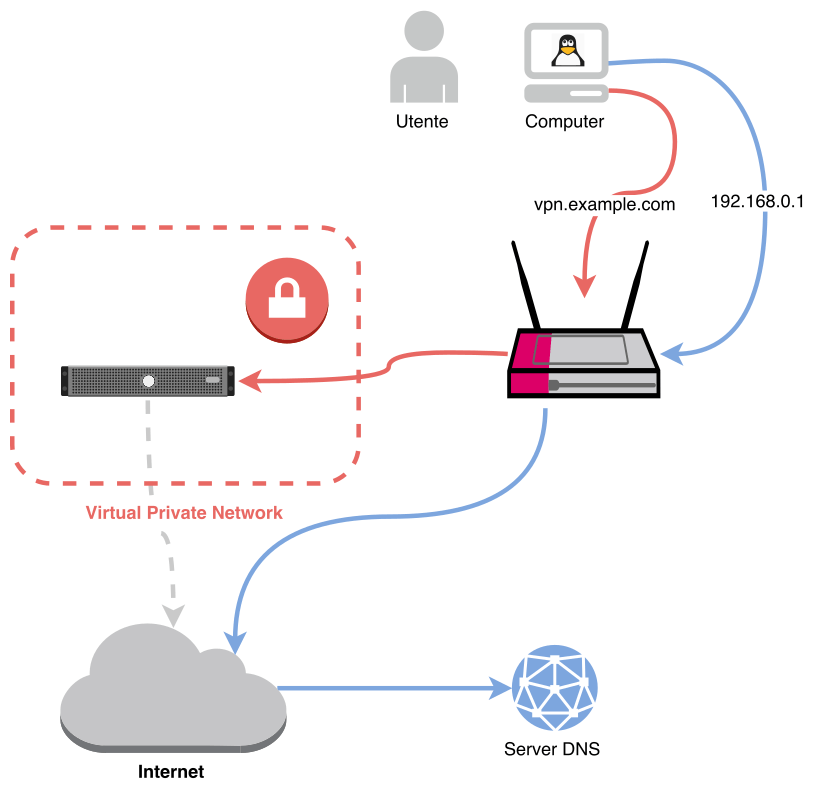
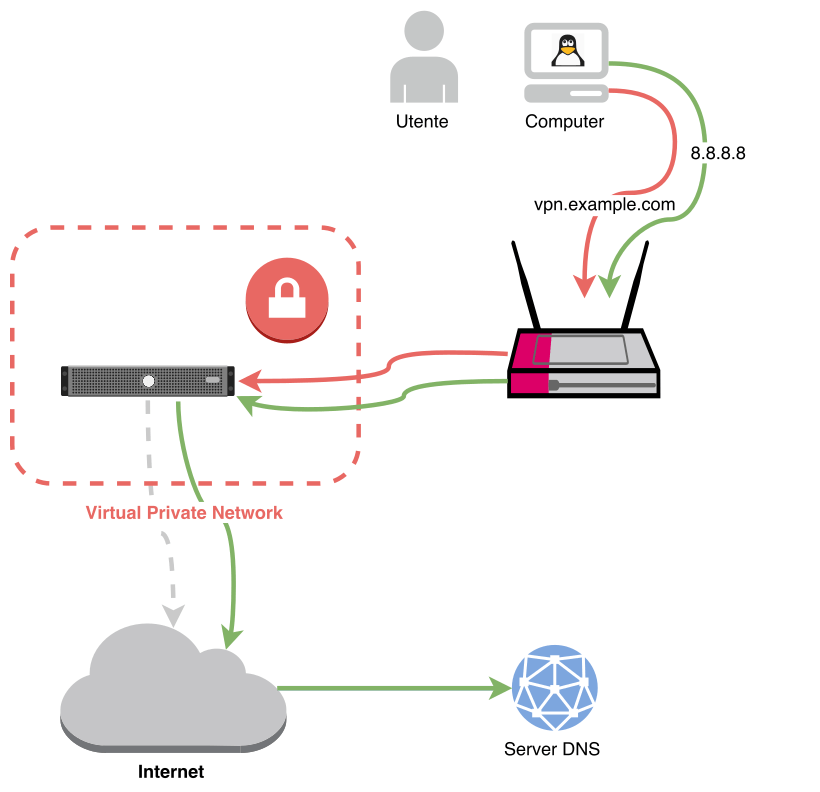
Se usiamo una VPN con Network Manager, si verifica un problema di DNS leak (è stato segnalato come bug), cioè le richieste DNS del nostro computer passano fuori dalla VPN e non sono protette! Questo diagramma spiega la situazione:
Collegamento VPN con DNS leak
Le connessioni a siti esterni (in rosso) sono protette e passano in modo criptato attraverso la VPN, che poi le fa uscire verso Internet. Però le richieste DNS sono (di default) rivolte verso il router, che ha un indirizzo di rete interna e perciò passa fuori dalla VPN.
Il router, di conseguenza, effettua una richiesta DNS al server (in blu) e quindi di fatto permette di lasciare una traccia sui siti che presumibilmente abbiamo visitato (se c’è una richiesta DNS, ci sarà un motivo…). Senza contare che, in alcuni luoghi, i DNS potrebbero essere configurati per impedirci di visualizzare determinati siti (per esempio Facebook o Youtube).
Quello che vorremmo noi, invece, è che le richieste DNS fossero protette (e quindi passassero nella VPN, non tramite il router). In attesa che il bug venga risolto, vi consiglio due metodi: uno è più facile e si può fare per ogni connessione, l’altro è globale ma leggermente più complicato.
Metodo 1: modificare le connessioni singolarmente
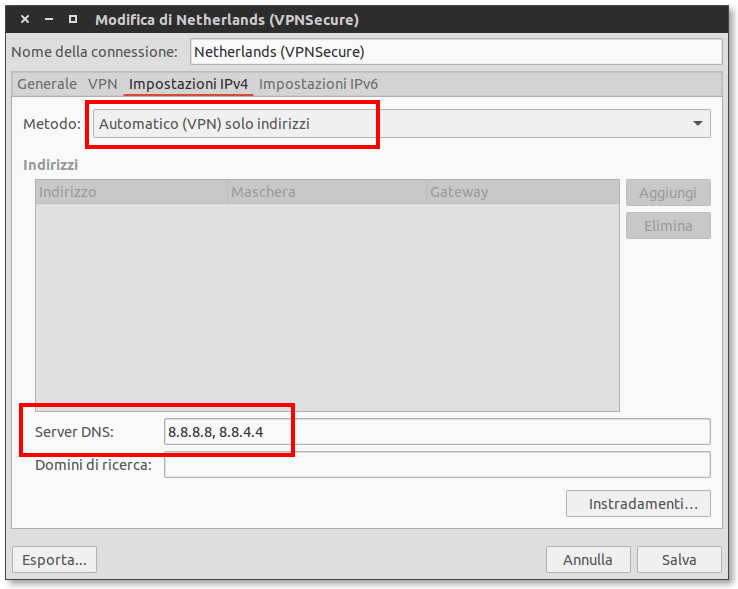
In attesa che il bug venga risolto, un metodo facile che ho trovato per risolvere il problema è impostare i server DNS manualmente nelle impostazioni della connessione VPN (va fatto per ogni server). Per esempio, potremmo impostare i server DNS di Google così:
Configurazione statica dei server DNS su una connessione VPN
Le impostazioni vanno fatte sicuramente per IPv4, che è ancora la versione di IP più utilizzata. Se siete su una rete che utilizza IPv6, dovrete configurare anche dei DNS per questa versione del protocollo.
Metodo 2: forzare i DNS per tutte le VPN
Si può anche fare una modifica globale al sistema che induca tutte le connessioni VPN a usare un certo DNS.
Per ottenere il risultato che vogliamo, dobbiamo modificare un file di sistema relativo alle interfacce di rete. Quando ci colleghiamo in VPN, si attiva un’interfaccia di rete virtuale chiamata tun0. Noi imposteremo i DNS su questa interfaccia.
Dovete innanzitutto aprire il file come amministratori, per esempio su Ubuntu potete usare Gedit con il comando:
sudo gedit /etc/network/interfaces
Procedete quindi ad aggiungere, in fondo al file, le righe:
# Forza i server DNS su ogni connessione VPN
iface tun0 inet manual
dns-nameservers 8.8.8.8 8.8.4.4
Salvate e uscite. Tenete presente che questa è una configurazione solo per IPv4, non per IPv6. A questo punto dovete riavviare il sistema. Non basta chiudere la connessione, bisogna proprio riavviare.
Questa modifica ha il vantaggio che non richiede assolutamente di cambiare le impostazioni delle singole connessioni, ha un effetto globale su tutte le VPN che avvierete sul vostro computer. Inoltre, se volete cambiare i server DNS vi basta modificare un solo file e riavviare.
Attenzione: se usate anche VPN aziendali, badate che potrebbe darvi dei malfunzionamenti. Casomai testate e eventualmente annullate la modifica.
Passo finale: cambiare i DNS della connessione
Dopo alcuni test, ho verificato quanto riportato anche da altri: il semplice cambio DNS sulla VPN non previene il leak al 100%, specialmente se usate la funzione Connessione VPN automatica nelle impostazioni, per accedere automaticamente alla VPN quando si attiva il Wi-Fi o la rete cablata.
Per essere sicuri il più possibile, vi consiglio di modificare la connessione che usate sempre a casa (wireless o cablata) e impostare anche lì i DNS statici, mettendo la rete in modalità Automatico (DHCP) solo indirizzi. I parametri per la connessione saranno molto simili a quelli visti nel Metodo 1 per la VPN.
A questo punto, la combinazione di uno dei due metodi visti prima con quest’ultimo passo vi dovrebbe dare una copertura adeguata in tutte le situazioni. 😉 Quando il bug verrà risolto, tutto ciò non sarà più necessario.
Qualsiasi metodo adottiate, trovate un’ottima lista di server DNS su DuckDuckGo tra cui poter scegliere. Una volta attivata la modifica, la situazione sarà così:
Connessione VPN senza DNS leak
La richiesta DNS (in verde) è sempre contenuta dentro al collegamento criptato della VPN (l’ho disegnata a parte solo per far capire la dinamica) e quindi il router non la riceve né la rimanda al server DNS. La richiesta non viene svelata né può essere dirottata o bloccata dal router.
Con questo, ho praticamente finito. Non mi resta altro da fare che ricordarvi che è buona norma attivare la VPN automaticamente quando si accede a determinate reti (per esempio il Wi-Fi di casa) in modo da essere sempre protetti. 😉
Vi auguro una buona e sicura navigazione!
Aggiornamento 14/01/2016: l’articolo è stato integrato con l’aggiunta dell’impostazione statica dei DNS nella connessione usata abitualmente.
















{kind=link}