Questa triste storia “all’italiana” inizia il 23 aprile 2021: Aruba (uno dei più famosi provider italiani di servizi web, firma digitale e PEC) subisce una violazione informatica — un cosiddetto data breach. Nello stesso periodo, operando senza dare troppo nell’occhio, l’azienda interviene sui propri sistemi per forzare a tutti i clienti un cambio delle password, senza tuttavia indicare il motivo specifico.
Dopo più di 80 giorni, il 14 luglio 2021, il provider informa i propri clienti della circostanza. A dire il vero, alcuni (come me) sono stati informati il giorno successivo, ma poco importa. Fino a quel momento ai clienti era sempre stata negata qualunque informazione in merito a possibili attacchi, nonostante la manovra del cambio password fosse sembrata a molti “quantomeno bislacca” (cit. Orlando Serpentieri).
( Data breach all’italiana ) Cari @Arubait , il 29 aprile vi ho mandato una pec per capire perchè avevate costretto al cambio di credenziali i clienti che hanno servizi da voi. Non mi avete MAI risposto alla pec, ma fatto chiamare da una tizia di boh, PR? dicendo ->
Un professionista aveva chiesto conto ad Aruba riguardo la massiccia operazione di cambio password
L’email inviata da Aruba a metà luglio, oltre che estremamente tardiva, è scritta in modo da minimizzare nel modo più assoluto quanto successo. L’oggetto del messaggio è semplicemente “Comunicazione“, un titolo che passa inosservato, probabilmente ritenuto più innocuo di “Avviso VIOLAZIONE dati” o “Ci hanno sfondato il sistema”.
Il testo del messaggio è davvero peculiare, in quanto sottolinea che non ci sono state alterazioni di dati, né cancellazioni:
desideriamo informarla che il 23 aprile scorso abbiamo rilevato e bloccato un accesso non autorizzato alla rete che ospita alcuni dei nostri sistemi gestionali, ma nessun dato è stato cancellato né alterato
Aruba
Sempre relativamente ai dati, in seguito si ribadisce che la loro “integrità e disponibilità non sono state impattate in alcun modo”. Peccato che in tutto questo si sorvoli sul fattore più importante: la confidenzialità. I dati menzionati sono:
nome e cognome
codice fiscale
indirizzo, città, CAP, provincia
telefono
indirizzo email, indirizzo PEC
login all’area clienti
password (protette da crittografia forte)
Agli occhi di un utente poco esperto di sicurezza informatica il messaggio potrebbe lasciare l’idea che non sia successo niente di grave, ma in verità non si dice nulla riguardo il fatto che questi dati possano essere stati letti o copiati da terze parti non autorizzate. Viene da pensare che la bizzarra scelta di parole non sia casuale, ma strategicamente pensata per minimizzare gli eventi.
Il messaggio termina con alcuni consigli generici relativi ad accortezze per evitare le truffe (stare attenti alle email che sembrano provenire dal provider, non divulgare password, e così via) ma sostanzialmente dichiara all’utente che “non è necessaria alcuna azione”.
Tutto a posto quindi? Naturalmente no.
Innanzitutto, un aspetto assolutamente incredibile è che l’azienda riferisca di aver inviato la comunicazione quasi come se fosse stata una sorta di cortesia verso il cliente:
A conclusione di tutte le nostre analisi, abbiamo ritenuto doveroso informarla dell’accaduto seppur non sia richiesta alcuna azione da parte sua.
Aruba
La realtà è diversa: informare di un data breach è un obbligo di legge, ai sensi del GDPR. Questo oltretutto dovrebbe essere fatto in modo repentino, non tardivo. La lungaggine di Aruba ha raggiunto persino le testate internazionali (es. Aruba waited months to notify customers regarding a recent data breach).
#aruba… la notifica agli utenti non è una mera cortesia: è un obbligo di legge previsto per i casi particolarmente gravi di data breach. Ciò che è arrivato, oltre che tardivo, è anche molto ambiguo.
— Christian Bernieri – DPO (@prevenzione) 15 Luglio 2021
L’opinione di un DPO che conferma l’ambiguità e la tardività della comunicazione
Oltre a questo, permane la mancanza di chiarezza sul fatto che una terza parte abbia avuto accesso ai dati. Sui social si sono scatenate molte reazioni ironiche, con frasi come “i nostri dati vanno Aruba”. Al di là della parentesi goliardica, molti clienti vogliono giustamente avere delle risposte chiare.
Come richiedere chiarimenti ad Aruba
La mancanza di chiarezza in merito alla possibilità che i dati siano stati letti ha portato molte persone a contattare l’azienda, che ha fornito un indirizzo email normale (non PEC) dedicato. Vari clienti hanno ricevuto una risposta a voce, non per iscritto, il che lascia piuttosto perplessi.
Nel caso in cui abbiate ancora dei dubbi su Aruba:
– Ad aprile li bucano e negano il breach – A luglio arriva comunicazione pubblica ma non parlano di accesso abusivo ai dati – Dopo averli punzecchiati per settimane, ammettono che i dati possono essere stati letti
Una parziale conferma fornita da Aruba, dopo ripetute insistenze
Personalmente ho inviato un’istanza ad Aruba tramite PEC il 21 luglio 2021, richiedendo dei chiarimenti ed esercitando il diritto di accesso ai dati personali ai sensi dell’articolo 15 del Regolamento UE 2016/679. Quest’ultimo passaggio è importante perché obbliga l’azienda a rispondere, per non rischiare di incorrere in sanzioni.
Pensavo di attendere qualche giorno per la risposta, prima di scrivere questo post, però non è ancora pervenuta. Ho deciso pertanto di scrivere alcune indicazioni su come chiedere chiarimenti ad Aruba e fornirvi un modello della mia lettera, nel caso vi possa tornare utile.
Vi ricordo che io non sono un avvocato, sono semplicemente un consulente informatico forense, e questo articolo non costituisce una consulenza legale. Detto questo, se volete scaricare il modello in formato modificabile potete cliccare qui sotto:
Qualora l’azienda non dovesse rispondere nel termine di 30 giorni dalla vostra richiesta, potrete procedere all’inoltro di un reclamo al Garante per la Protezione dei Dati Personali. Il modello per il reclamo è consultabile cliccando qui.
Una volta ricevuta una risposta di Aruba provvederò ad aggiornare questo post.
Se lo desiderate, potete condividere le vostre esperienze con la richiesta (ed eventuale risposta) qui sotto nei commenti.
Il 29 maggio 2021 si svolgerà la nuova edizione di HackInBo, la prima e più attesa conferenza gratuita su sicurezza informatica e hacking, che ogni anno attira migliaia di partecipanti da tutta la penisola.
Il programma è ricco di interventi interessanti e io sarò impegnato con la realizzazione di un laboratorio interamente dedicato al processo di preservazione delle prove presenti sul web:
Questo intervento si svolgerà sotto forma di laboratorio per l’acquisizione forense di pagine web. Nello specifico ragioneremo su una metodologia che si possa poi applicare a vari strumenti, a seconda dei casi. Mostrerò alcuni esempi di acquisizioni e ne approfitteremo per una discussione comparativa e il ruolo dei vari tool quali Wireshark, OSIRT Browser, mitmproxy, Archiveweb.page, Carbon14 e i siti di archiviazione come WayBack Machine.
Si tratta di un argomento sempre più rilevante, in quanto cristallizzare il contenuto di pagine web, articoli di giornale, blog e social network è spesso utile nei procedimenti legali per difendersi o tutelare i propri interessi.
Indicazioni operative
L’evento si svolgerà interamente online e sarà trasmesso in streaming. I biglietti per iscriversi e partecipare ai vari laboratori di questa Lab Edition saranno disponibili a partire dal 6 maggio (domani) alle 10:00. Fate riferimento direttamente al sito ufficiale di HackInBo per l’iscrizione.
Riguardo il mio intervento, per seguirlo attivamente vi sarà necessario scaricare un po’ di software: alcuni sono multipiattaforma, altri funzionano solo su Windows. Per questo è caldamente consigliata una VM con Windows 7 o 10 scaricabile da qui.
Nell’ambito del ciclo di seminari che seguono la conclusione della Open Source Digital Forensics Conference 2020, sono stato invitato a tenere un intervento online che si svolgerà il mese prossimo.
L’incontro, organizzato da Basis Technology, verterà sull’analisi forense di partizioni NTFS. In particolare, parlerò di RecuperaBit, il mio software per la ricostruzione di file system NTFS danneggiati. Il webinar è destinato a un pubblico internazionale, perciò sarà interamente in lingua inglese.
La diretta avrà luogo il 3 marzo 2021 a partire dalle 17:00, ora italiana. La registrazione sarà disponibile esclusivamente per chi si sarà registrato (gratuitamente) all’evento.
Questo è l’abstract:
RecuperaBit: Present and Future of NTFS Reconstruction
File system corruption, either accidental or intentional, may compromise the ability to access and recover the contents of files during data recovery and digital forensics activities. Conventional techniques, such as file carving, allow for the recovery of file contents partially, without considering the file system structure. However, the loss of metadata may prevent the attribution of meaning to extracted contents, given by file names or timestamps. RecuperaBit implements a signature recognition process that matches and parses known file records, followed by a bottom-up reconstruction algorithm which is able to recover the structure of the file system by rebuilding the entire tree, or multiple subtrees if the upper nodes are missing. Partition geometry is determined even if the boundaries are unknown by applying an approximate string matching algorithm.
This talk aims to introduce the algorithms used by RecuperaBit and to discuss future plans to make the tool more usable, streamlined and user-friendly by re-thinking its command line user interface.
Per prenotare il vostro posto e seguire il webinar, potete utilizzare il link:
L’associazione ONIF (Osservatorio Nazionale Informatica Forense) organizza un seminario online completamente gratuito, con l’obiettivo di consentire, anche in questo periodo di restrizioni, di poter accedere ad un aggiornamento professionale con i migliori esperti del settore.
Il webinar sulla Digital Forensics è particolarmente indicato per consulenti tecnici, avvocati e professionisti informatici. Nello specifico, il programma propone interventi relativi a multimedia forensics, mobile forensics e attività di OSINT e acquisizione forense di Instagram:
15:00 · Saluti del Presidente C3I Ing. Armando Zambrano
15:05 · Introduzione del Presidente ONIF Paolo Reale, delegato C3I Ordine di Roma
15:15 · Multimedia Forensics nell’era della computational photography Massimo Iuliani
15:40 · Data validation di informazioni derivanti da estrazione mobile con altri elementi Nicola Chemello
16:05 · Uso delle API di Instagram per l’acquisizione forense Andrea Lazzarotto
16:30 · Mac computer data access with MacQuisition Tim Thorne, Senior Solutions Expert at Cellebrite
16:50 · Sponsored talk Cellebrite
17:10 · Q&A e saluti Paolo Reale, delegato C3I Ordine di Roma
L’evento, moderato da Ugo Lopez, è organizzato con il patrocinio del Comitato Italiano Ingegneria dell’Informazione C3I, dell’Ordine degli Ingegneri di Roma e di Bari e la collaborazione di Cellebrite.
Per partecipare è obbligatorio procedere all’iscrizione gratuita sulla piattaforma EventBrite, facendo click sul seguente pulsante. Il numero di posti è limitato.
Chi di voi si interessa al salvataggio dei contenuti audio/video dai siti web avrà sicuramente già sentito parlare di YouTube-dl. Si tratta di un software completamente open source, rilasciato addirittura nel pubblico dominio, che nel sito ufficiale è presentato in modo molto semplice:
YouTube-dl è un programma a riga di comando per scaricare video da YouTube.com e da qualche altro sito.
In realtà, a dispetto del nome “limitante”, il programma contiene oltre 1000 estrattori per le fonti più disparate, riunendo la potenza di strumenti esterni, quali FFmpeg, con codice scritto ad-hoc per moltissimi siti.
Concettualmente, l’idea è simile ai miei script per i siti delle TV italiane: si scrive del codice specifico che si adatta ai portali che si desidera supportare. Finora questo codice era mantenuto sulla piattaforma GitHub, la più grande comunità di sviluppatori software del mondo, di proprietà di Microsoft.
La richiesta di rimozione
Il 23 ottobre 2020, la Recording Industry Association of America (RIAA) ha presentato un’istanza di rimozione ai sensi del Digital Millenium Copyright Act (DMCA), richiedendo la rimozione del repository principale del progetto, nonché svariate versioni clonate o derivate (dette fork).
La vicenda è stata spiegata nel dettaglio su XDA Developers ma, riassumendo, la RIAA sostiene che YouTube-dl sia uno strumento atto a violare i diritti di copyright dei suoi assistiti (artisti e case discografiche). In realtà ci sono diversi aspetti problematici relativi a questa argomentazione.
Youtube-dl is a legitimate tool with a world of a lawful uses. Demanding its removal from Github is a disappointing and counterproductive move by the RIAA. https://t.co/VUbTokd4cP
Il tweet della EFF dove si spiega che YouTube-dl è uno strumento legittimo, con svariate applicazioni perfettamente legali
Come ha spiegato la Electronic Frontier Foundation (EFF), YouTube-dl è uno strumento lecito e può essere utilizzato per molti scopi assolutamente validi. Restando nell’ambito di YouTube, senza quindi citare le centinaia di altri siti web supportati, si possono scaricare video con licenza Creative Commons o nel pubblico dominio, come quelli governativi.
Inoltre, alcuni creatori di contenuti o persone che appaiono nei video usano il programma per scaricare i propri contenuti. Ne so qualcosa anch’io.
Insomma, sostenere che un software del genere sia illegale è un po’ come richiedere che sia proibita la vendita dei coltelli da cucina, in quanto oltre a sfilettare il pesce ci si possono potenzialmente fare altre cose.
Oltre a questo, la RIAA (entità americana) nella propria istanzamette insieme un’accozzaglia di motivazioni diverse, citando il DMCA (una legge statunitense) e subito dopo facendo riferimento a una decisione della Corte Regionale di Amburgo ai sensi del diritto tedesco. (?!?!?)
GitHub è un’entità americana, quindi deve sottostare alle richieste DMCA, tuttavia il fatto che tale atto abbia ripercussioni su tutti gli utenti a livello mondiale è una conseguenza che non deve essere sottovalutata.
Infine, è opportuno spiegare che l’unica possibilità che resta agli sviluppatori, volendo restare su GitHub, è quella di opporsi all’istanza, andando incontro a lunghe e costose vicende giudiziarie. In sostanza, presentare la richiesta per la RIAA è semplice ed economico, contrastarla richiede molto denaro ed è difficile, specie per un progetto open source.
Le reazioni in rete
Oltre alla citata presa di posizione della EFF (che fa quindi ben sperare in un coinvolgimento in difesa degli sviluppatori), non sono mancate numerose reazioni online.
Altre persone hanno cominciato a condividere nuove copie del codice (o, in gergo, forkare) su GitHub stesso, nonché su GitLab, BitBucket e tutte le piattaforme “alternative” ad esso, famose o meno.
Tuttavia, mi vorrei soffermare su due casi che ho visto online e che sono assolutamente fenomenali.
Innanzitutto, l’utente Twitter lrvick ha utilizzato un difetto noto da tempo a GitHub (e considerato “indegno” di essere corretto) per inserire una copia del codice sorgente di YouTube-dl direttamente all’interno del repository DMCA di GitHub.
Hey @GitHub. Remember that security bug where anyone can attach commits to repos they don’t control? That bug you said you wont fix?
It was used to attach the “youtube-dl” source code to your own DMCA repo. Have fun @DMCA.
Quindi, a livello teorico, ora la RIAA dovrebbe richiedere a GitHub di cancellare il repository di tutte le istanze DMCA, in quanto contiene il codice “incriminato”. 😀
Per farsi beffe di YouTube, invece, l’utente GitHub gasman ha condiviso un piccolo pezzo di codice e un video postato su YouTube, che contiene una codifica visuale (in binario) del codice sorgente del programma.
Clicca qui per mostrare contenuto da YouTube. (leggi la privacy policy del servizio)
Scaricando e decodificando questo video, caricato su YouTube, è possibile ottenere una copia del codice di YouTube-dl
A tutti gli effetti, gli utenti ora possono usare YouTube per condividere con gli altri un software usato per scaricare i video di tale sito.
In attesa di vedere l’evolversi della vicenda, è importante capire quali opzioni rimangono per scaricare i video da YouTube e da altri siti web, per scopo personale o comunque per altri usi legittimi.
Innanzitutto, c’è da chiarire che i download del programma sul sito ufficiale sono ancora attivi. Nel dubbio, è meglio usare solo yt-dl.org e ottenere una copia del software da lì. Gli utenti Linux e macOS possono usare anche Homebrew, pip o il proprio gestore di pacchetti.
Chi preferisce provare qualche alternativa può valutare l’uso di The Stream Detector (in accoppiata con streamlink oppure ffmpeg), JDownloader o altri programmi. Nei casi più difficili, può tornare utile leggere la mia guida completa per il download dei contenuti audio e video presenti nelle pagine web.
La cosa più importante rimane, in ogni caso, diffondere la conoscenza di questa vicenda e riflettere sulle conseguenze che atti del genere possono avere sulla nostra fruizione dei contenuti web.
Aggiornamento: il 16 novembre 2020 GitHub ha annunciato di avere reintegrato il repository del progetto, anche in seguito a una risposta ufficiale di EFF e alcune modifiche effettuate sul codice sorgente.
Dal 30 settembre al 2 ottobre 2020 si terrà la terza edizione di Treviso Forensic, uno dei principali appuntamenti tra professionisti (tecnici, avvocati, magistrati, …) che operano nel settore delle scienze tecniche applicate in ambito forense.
L’evento è organizzato dall’Ordine degli Ingegneri di Treviso e favorisce la figura del tecnico forense, con un approccio multidisciplinare che coinvolge diverse scienze.
La mattina del 2 ottobre conterrà una sessione interamente dedicata alla digital forensics e parteciperò con un intervento intitolato “Falsificazione dei messaggi WhatsApp sui dispositivi Android e iOS”.
Qui ve ne anticipo l’introduzione:
In Italia WhatsApp è la piattaforma di messaggistica istantanea più popolare in assoluto, con una penetrazione del mercato dell’84%. Questo fa sì che la produzione delle relative conversazioni si presenti sempre più frequentemente in vari procedimenti. I consulenti tecnici sono chiamati ad estrarre le chat dai dispositivi personali delle parti, in quanto il contenuto dei messaggi non viene conservato sui server.
Trattandosi di messaggi non riscontrabili dai tabulati telefonici, si pone il problema di valutare la genuinità e l’integrità del contenuto delle chat. Il presente lavoro è nato con lo scopo di verificare se fosse possibile per un utente falsificare i messaggi WhatsApp all’interno del proprio dispositivo, con Android o iOS.
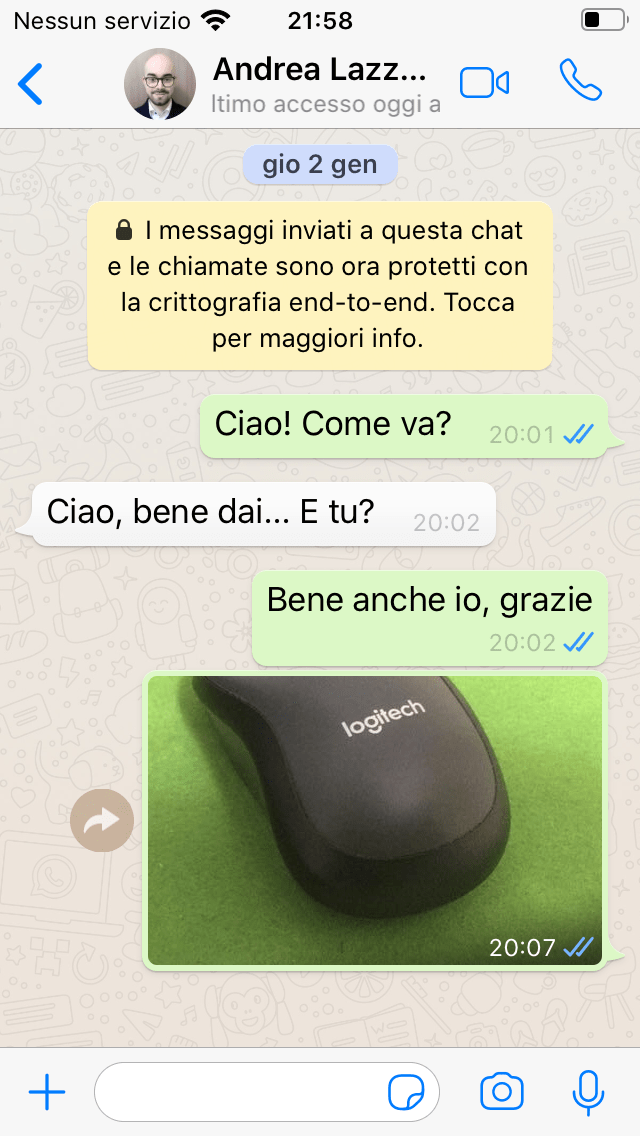
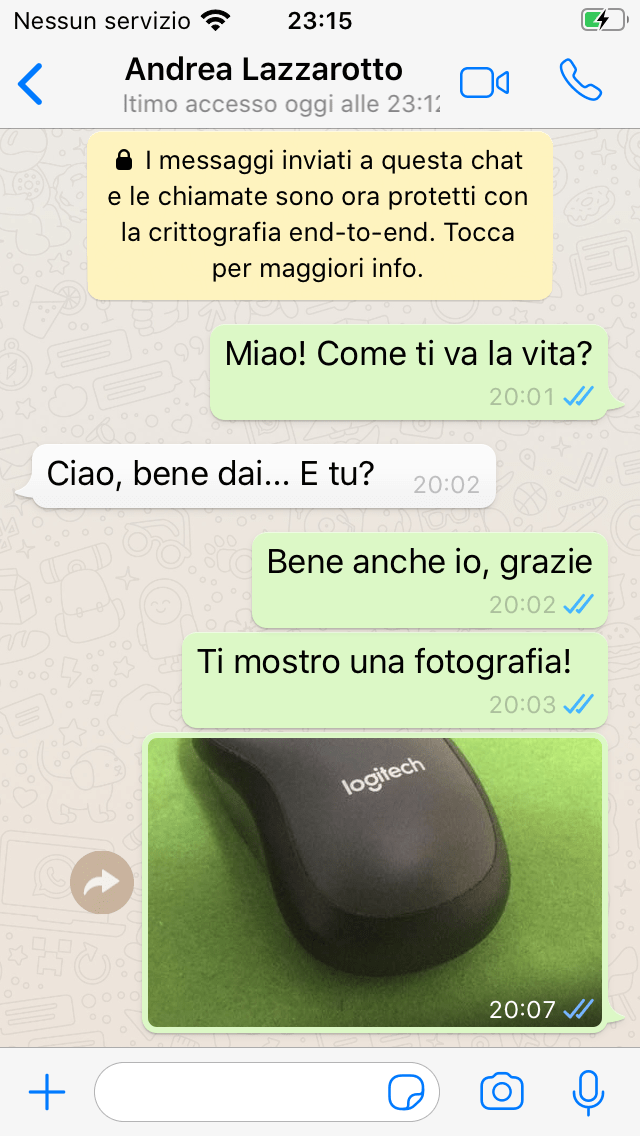
Il talk conterrà un breve riassunto di un argomento che ho già avuto modo di trattare l’anno scorso al convegno ONIF, per poi presentare per la prima volta in assoluto una dimostrazione di messaggi WhatsApp falsificati su iOS.
Prima
Dopo
Esempio di chat modificata
Quest’anno, data la particolare situazione sanitaria causata dalla diffusione del Covid-19, il seminario si terrà in modalità webinar tramite la piattaforma Zoom.
Ciò significa che non potremo godere della vista di una città bella come Treviso, in compenso la partecipazione potrà essere estesa anche alle persone che si trovano più lontano.
Chi mi segue abitualmente già lo sa, da tempo partecipo come relatore a ESC, un incontro non-profit di persone interessate al Software e Hardware Libero, all’Hacking e al DIY che si svolge a fine estate presso Forte Bazzera, vicino a Venezia.
Anche quest’anno ho voluto dedicarmi allo sviluppo software, stavolta però ho proposto un talk riguardante la creazione di app per le piattaforme Android e iOS usando tecnologie web:
La tua prima app Android e iOS con Ionic Framework
Moltissime applicazioni per smartphone hanno una struttura simile e abbastanza semplice. Lo sviluppo nativo richiederebbe di programmarle con linguaggi e ambienti diversi a seconda della piattaforma. Ionic Framework è una piattaforma di sviluppo gratuita e open source che permette di usare una sola codebase esportando poi app ibride per Android, iOS e browser.
Al giorno d’oggi capita sempre più frequentemente di dover acquisire delle prove dai siti web, in particolar modo dai social network. Ci si trova quindi a dover “cristallizzare” il contenuto di una pagina prima che venga alterato oppure cancellato.
Il caso più classico è quello della diffamazione a mezzo Internet: la vittima del fatto ha la necessità di certificare l’offesa alla propria reputazione, avvenuta tramite un commento su un blog o un post su Facebook.
Un’altra circostanza piuttosto frequente è la tutela della proprietà intellettuale e industriale. Le pagine social aziendali attirano potenziali clienti e sono un ottimo strumento di marketing. Dei soggetti terzi potrebbero sfruttare illecitamente marchi, foto di prodotti o contenuti altrui a proprio vantaggio.
Quest’ultimo è un caso che mi è capitato recentemente: la pagina Instagram di un’azienda è stata indebitamente acceduta da una persona che se ne è appropriata, cambiandone il marchio e i dati di contatto. Questo fatto ha comportato l’alterazione di dati informatici (vedasi art. 635 bis c.p.), nonché un evidente danno all’azienda in quanto si è vista sottrarre anche numerose foto dei propri prodotti e i follower della pagina.
Lo screenshot non basta
In tutti questi casi c’è da fare una breve ma importantissima precisazione. Purtroppo alcune persone ritengono ancora sufficiente l’utilizzo degli screenshot come “prova” in un procedimento civile o penale. Il pensiero comune è:
Ho fatto lo screenshot! Ora lo trasmetto al mio avvocato e ti querelo!
Questo ragionamento fa acqua da tutte le parti.
Uno screenshot, vale a dire l’immagine dello schermo (o presunta tale) che “cattura” il contenuto di un sito web o una chat, non si può considerare una prova valida.
Il contenuto di una schermata può essere infatti alterato sia prima che dopo aver prodotto lo “scatto”. Tutto questo non richiede conoscenze tecniche particolarmente elevate, specialmente per le pagine web.
Se non vi ho convinto, potete sempre farmi i complimenti per la mia nomina a “Persona dell’anno 2019”. 😉
Esempio di screenshot assolutamente falso, creato solamente per scopi illustrativi
Ovviamente avrete capito che l’immagine qui sopra non è reale. Ma il punto è che si tratta veramente di una notizia comparsa online, che però è stata modificata prima di catturare la schermata.
Questa è una operazione alla portata di molti (se non quasi tutti), ma anche la modifica dell’immagine a posteriori è un rischio non indifferente.
Per questi motivi, la raccolta della prova che un contenuto è stato pubblicato non si può limitare a uno screenshot. Si deve procedere a cristallizzare la pagina in modo adeguato, prima che venga ulteriormente modificata o rimossa.
Acquisizione di base con i siti di archiviazione
Quasi tutti i profili Instagram sono pubblicamente accessibili. Questo perché Instagram è una vetrina dove le aziende possono rendersi visibili e condividere foto dei prodotti o altri contenuti interessanti per aumentare il proprio seguito.
Anche le persone non iscritte possono vedere i profili, utilizzando un semplice browser web. Pertanto, queste pagine si possono cristallizzare in modo semplice come molti altri siti.
Il modo più facile di cristallizzare pagine pubbliche come questa è adoperare i siti di archiviazione. Questi strumenti forniscono all’utente la possibilità di inserire l’indirizzo (URL) di un documento informatico pubblicato sul web, producendone quindi una copia informatica.
Archive.today (anche conosciuto come archive.fo, archive.is, archive.md, eccetera)
Esistono anche degli strumenti molto più sofisticati e costosi, come ad esempio FAW, usati professionalmente da chi si occupa di digital forensics. Tuttavia, qui mi voglio focalizzare su degli strumenti di base e relativamente semplici.
I siti di archiviazione sono mezzi gratuiti e alla portata di tutti, che permettono di agire in fretta quando si teme che un contenuto compromettente possa essere cancellato, anche prima di essersi rivolti a un consulente tecnico specializzato e/o a un avvocato.
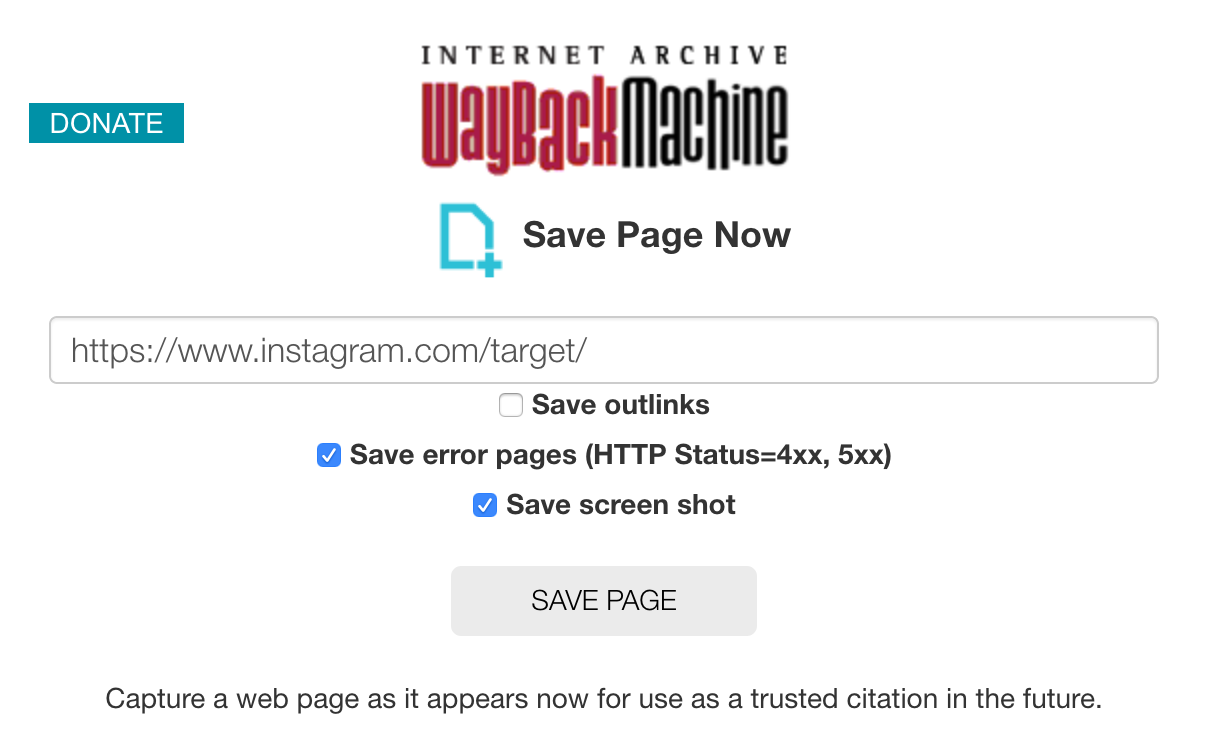
Per acquisire un contenuto con Wayback Machine, bisogna inserirne l’URL nell’apposito modulo di salvataggio, attivare l’opzione che salva anche lo screenshot e poi procedere col pulsante Save Page.
Cristallizzazione di una pagina con la Wayback Machine
A questo punto, Wayback Machine simulerà l’azione di un vero browser e acquisirà il contenuto della pagina comprensivo di codice sorgente (HTML, CSS, JS) e risorse statiche (immagini e eventuali allegati PDF).
Al termine della procedura, si otterranno due link permanenti che certificano lo stato della pagina al momento del salvataggio:
Con Archive.today la procedura è molto simile, con la differenza che si ottiene un unico link da cui si può vedere una riproduzione fedele della pagina e la relativa schermata.
Generalmente le pagine cristallizzate con Archive.today sono un pochino più fedeli all’originale, ma non è una regola ferrea e va presa con le pinze. In ogni caso, le pagine acquisite con Wayback Machine conservano i nomi originali dei file multimediali (che potrebbero essere assai importanti).
Pertanto è spesso opportuno provare a fare l’acquisizione con entrambi gli strumenti, salvando poi gli URL delle copie così ottenute. I due siti forniscono anche gli screenshot, ma essi sono solamente a supporto dell’acquisizione e non la sostituiscono.
Una cosa utile da ricordare è che le pagine salvate su Archive.today possono venire indicizzate dai motori di ricerca. Per questo motivo, potrebbe essere preferibile non usare questo strumento se si ha a che fare con dei contenuti diffamatori.
Usando questa semplice procedura siamo già in una situazione mille volte migliore di chi si ritrova ad aver catturato solo una schermata.
Estrazione dei metadati
Apparentemente, quanto discusso prima sembra coprire al 100% la necessità di acquisire un profilo Instagram. Ma se avete mai adoperato questo social network tramite app, vi sarà venuta in mente la frase idiomatica:
There is more than meets the eye
Infatti il problema fondamentale in questo caso è che un profilo Instagram visualizzato tramite pagina web non contiene tutte le informazioni ottenibili con l’app.
Per esempio, ecco cosa succede con la versione iOS di Instagram:
Target ha indicato un numero di telefono e un indirizzo email che compaiono tramite il tasto Contatta. Tuttavia non c’è traccia di questi dati nella versione web di Instagram. Questo significa che sarebbe impossibile acquisirli dal sito, anche usando strumenti professionali.
Per ovviare a questo problema, possiamo attuare una procedura che simula il comportamento dell’applicazione ufficiale di Instagram usando le relative API private.
Questa parte è più complessa ed è dedicata agli addetti ai lavori, in quanto richiede la realizzazione di un piccolo software.
Dopo aver registrato un account di test su Instagram, possiamo creare un breve programma in linguaggio PHP che sfrutti la libreria Instagram-API. Prima di tutto, è necessario installare la libreria con Composer:
composer require mgp25/instagram-php
Poi si può adattare uno dei tanti semplici esempi già forniti su GitHub. In particolare, bisogna instanziare la classe e provvedere al login con l’utente di prova:
Consiglio di prestare molta attenzione al codice numerico instagram_location_id, anche se non è sempre presente. Questo valore è estremamente interessante perché permette di collegare una pagina Instagram a una pagina Facebook.
Prendendo come esempio l’account Instagram ikeauk, si ottiene il codice 187578611279774, da cui si ricava immediatamente un valido URL su Facebook: https://www.facebook.com/187578611279774/
Considerazioni finali
Grazie ai siti di archiviazione è possibile procedere a una prima cristallizzazione “di base” di un profilo Instagram. Simulando invece il comportamento dell’app per cellulari si può accedere a molti altri metadati, non altrimenti visibili.
L’ultimo consiglio che vi posso dare è quello di unire la procedura in PHP all’uso di mitmproxy per registrare tutti i flussi HTTPS intercorsi durante l’acquisizione. Vi basterà avviarlo e assicurarvi che il proxy sia correttamente impostato nel codice PHP:
Così facendo, potrete finalizzare il lavoro producendo il file registrato da mitmproxy, lo script di acquisizione, il relativo output ridirezionato in un file di testo e un breve report in PDF dentro a un archivio ZIP. Alla fine basterà apporre la firma digitale e la marca temporale.
Aggiornamento del 6 gennaio 2020: in seguito al graditissimo suggerimento di Paolo Dal Checco, ho aggiunto una precisazione sul fatto che le pagine memorizzate da Archive.today sono indicizzabili dai motori di ricerca.
Il 26 ottobre ho partecipato come relatore al Linux Day 2019 organizzato dal Gruppo Utenti GNU/Linux di Vicenza. Il filo conduttore di quest’anno era l’intelligenza artificiale e i video dei vari interventi sono stati poi pubblicati anche su YouTube.
Il mio intervento aveva un carattere piuttosto introduttivo, con lo scopo di presentare una panoramica della disciplina:
Introduzione all’intelligenza artificiale
Questo intervento si propone di fornire ai partecipanti una panoramica chiara, completa e divulgativa sull’Intelligenza Artificiale e la Computer Vision. Partendo da un’introduzione sui concetti di base, verrà spiegato il funzionamento base del Machine Learning e la sua implementazione attraverso le reti neurali. Non mancheranno cenni alle applicazioni quotidiane dell’Intelligenza Artificiale, inclusa la classificazione, la segmentazione e il riconoscimento dei testi.
Mi auguro che questo talk abbia permesso di fare un po’ di chiarezza, sottolineando come l’intelligenza artificiale abbia del potenziale enorme, ma non è perfetta e non è magia. Soprattutto, i robot non conquisteranno il mondo. 😀
Questo è il video su YouTube, come sempre di ottima qualità grazie al lavoro di montaggio di Stefano del LUG Vicenza:
Clicca qui per mostrare contenuto da YouTube. (leggi la privacy policy del servizio)
Il materiale usato per la presentazione è una versione lievemente rivista di ciò che avevo presentato l’anno scorso nel ciclo di incontri Dieci volti dell’Informatica. Lo potete visionare cliccando qui.
Chi segue questo blog da un po’ di tempo sa che nel 2010 avevo pubblicato il mio primo script per salvare i video dal portale Rai, proseguendo poi nel 2012 con un secondo script rinnovato.
Erano tempi bui, in cui gli utenti Linux non potevano neppure vedere facilmente i programmi per via di Silverlight. Lo script aveva lo scopo di integrare e far riprodurre i video MP4 e i flussi MMS tramite un player nativo, per esempio VLC.
Ora i tempi sono cambiati e il sito si è evoluto numerose volte in questi ultimi 7 anni, così come i browser che usiamo per navigare. Adesso i video si possono vedere senza problemi su tutte le piattaforme, ma le numerose modifiche effettuate continuamente nell’arco di tutto questo tempo hanno reso lo script precedente sempre più complicato e difficile da gestire.
Con la nuova grafica di Rai Play ho tagliato i rami secchi, eliminando il supporto a vecchie versioni del sito, vecchi browser e vecchie abitudini di programmazione. Insomma, è stato riscritto tutto daccapo. 😀
Funzionamento dello script
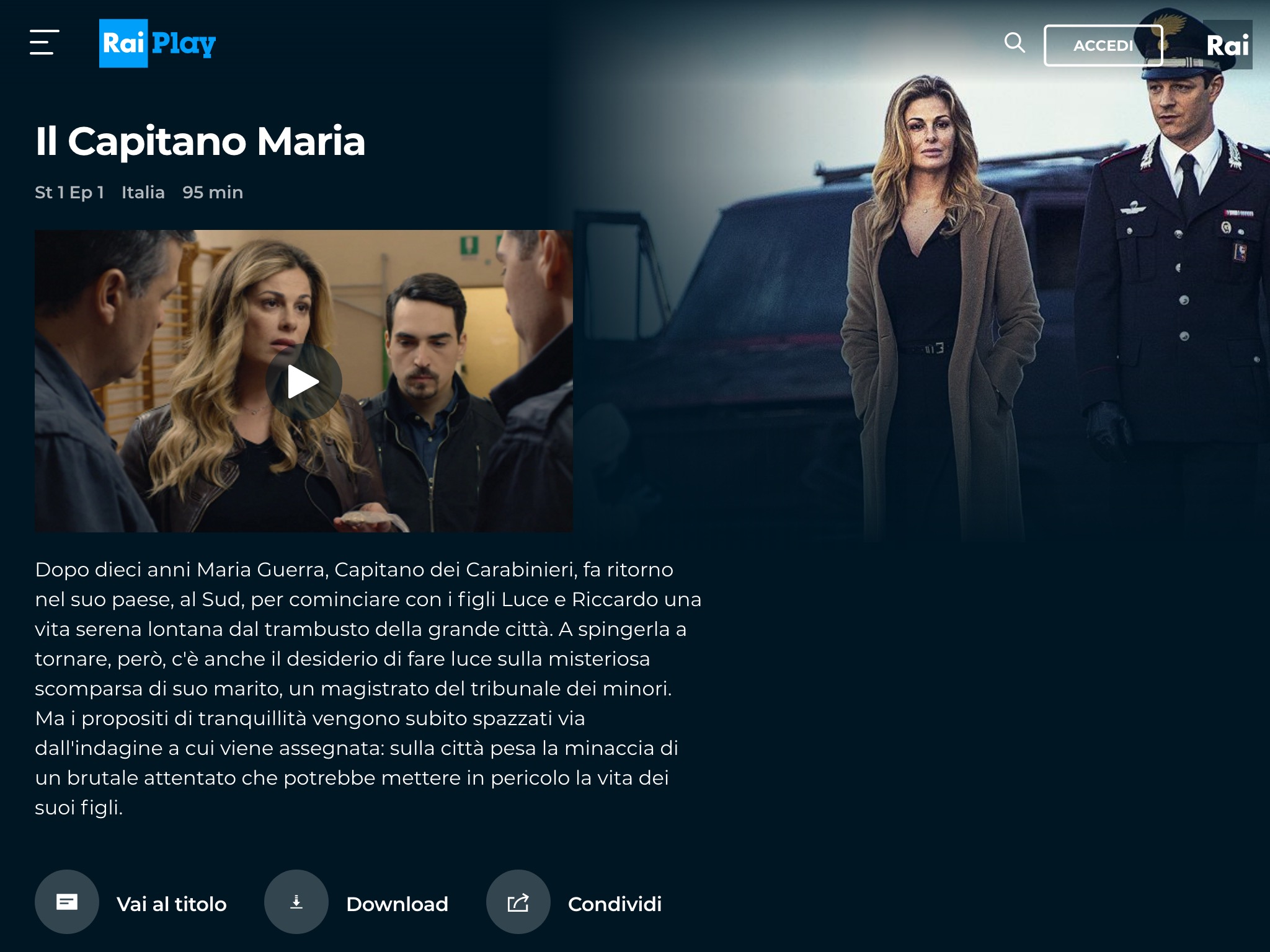
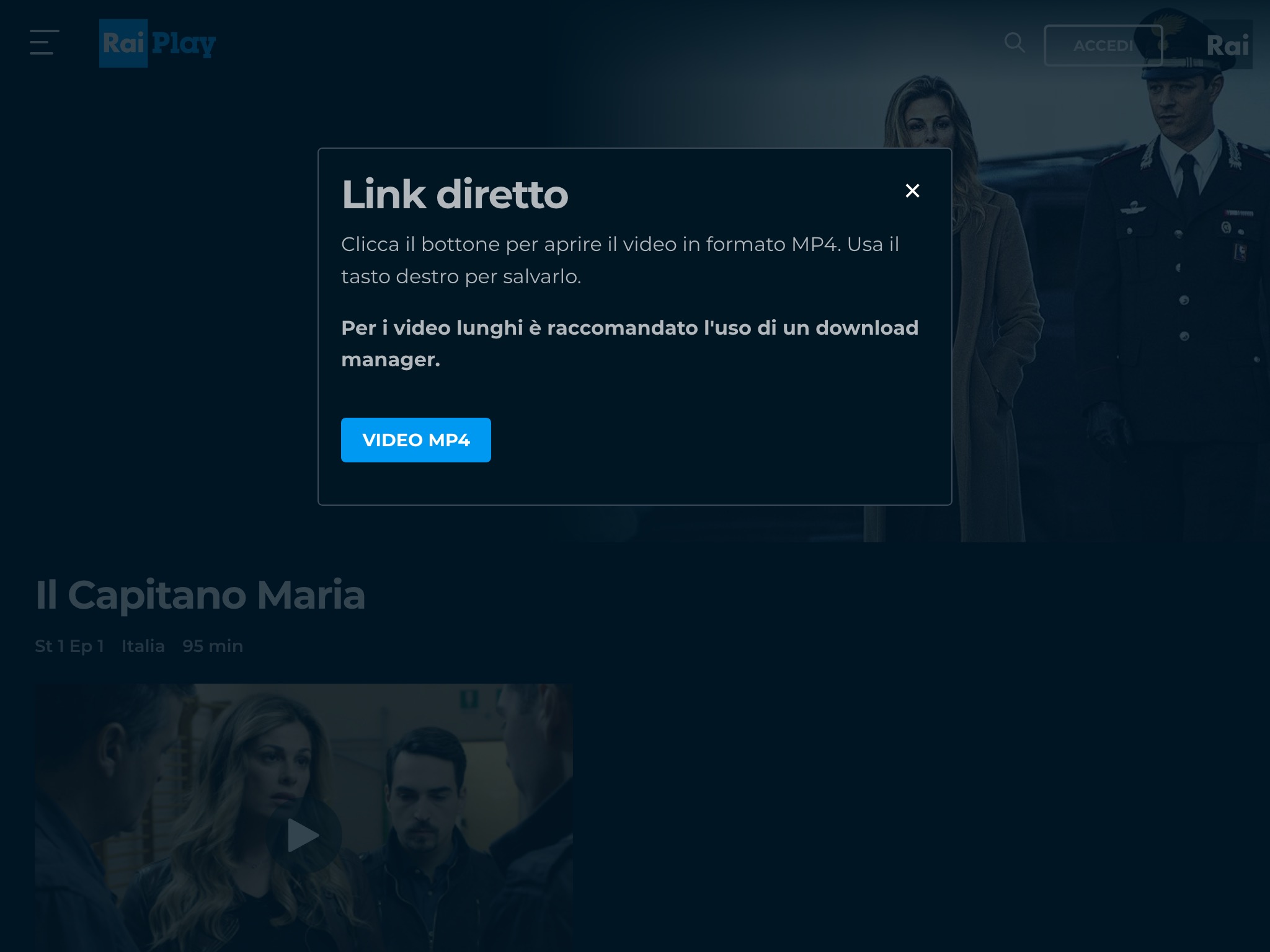
Schermate che mostrano lo script in azione
Il mio script vi consente di scaricare i video da Rai Play senza dover fare alcun login. In tal caso, inibisce la finestra che invita l’utente ad accedere e attiva la navigazione quando si clicca sulle miniature dei video.
Il pulsante per i download viene inserito in due zone diverse:
sotto alla scheda di un episodio
all’interno del player video (vale solo per chi fa il login)
Quando viene premuto il pulsante, parte il processo di ricerca del video MP4. Se viene trovato un file, lo script mostra una finestra modale con il link al video. Altrimenti compare un messaggio di errore.
Estensione per il browser
Prima di installarlo, dovete aggiungere l’estensione adatta al vostro browser. Lo script è sviluppato espressamente per Greasemonkey (versione 4) e Tampermonkey, sui browser rilasciati negli ultimi 2 anni.
Altre piattaforme potrebbero funzionare ma non sono testate né è garantito alcunché. In base al vostro browser, potete usare:
Chrome, Vivaldi, Edge e altri della stessa famiglia: Tampermonkey
NB: si ricorda che, a partire dal 2024, per tutti i principali browser (eccetto Firefox) è obbligatorio attivare la modalità sviluppatore, altrimenti gli script non funzionano!
A questo punto vi basta recarvi alla pagina di download per installare lo script, premendo il pulsante qui sotto. Nella pagina che si aprirà, dovrete cliccare Installa questo script.
Come sempre, ricordate che lo script può funzionare solo se la Rai ha caricato il file in MP4, e non sempre lo fanno. Questo non dipende da me perciò non scandalizzatevi.
Lo script funziona solo ed esclusivamente su Rai Play. Se volete continuare a scaricare da altre sezioni del sito Rai, dovrete installare il vecchio script (che ora viene esplicitamente marcato come Legacy) seguendo il post precedente.
Il vecchio script Rai.tv native video player and direct links – LEGACYnon sarà più aggiornato. Potete naturalmente continuare a usarlo lo stesso, visto che attualmente funziona perfettamente per le altre sezioni del sito Rai.
Per quanto riguarda il nuovo Rai Play video download,vedremo per il futuro.
Come capita a ogni cambio del sito da parte della Rai, ultimamente sto notando interventi di tutti i tipi. Si passa dai commenti gentili e pazienti, a email più o meno insistenti… fino a qualche intervento al limite del passivo-aggressivo di persone che chiaramente non hanno la minima idea del lavoro che c’è dietro a tutto questo.
C’è chi mi scambia per un maggiordomo aspettandosi un aggiornamento a uno schiocco di dita (o all’invio di un commento sui social) e chi pensa che sia dovuto, scontato, ovvio che io passi il weekend a programmare uno script invece di spenderlo con gli amici.
A costo di dire qualcosa di sorprendente, io ho anche altro da fare. 😀 Dall’esperienza di questi anni sto imparando che pubblicare gli script che realizzo per me (come quelli delle TV) è sempre un rischio e porta poi a perdere un sacco di tempo in aggiornamenti e modifiche varie. Ho intitolato questo post (non a caso) “l’ultimissimo script” perché è anche un buon auspicio per il futuro. 😉
Quindi lo script continuerà ad essere quello che è sempre stato: un hobby. Ci lavoro se ho tempo, se ne ho voglia e se poi torna utile anche a me. 🙂