A giugno si terrà un evento organizzato congiuntamente dall’Ordine degli Ingegneri della provincia di Brescia (Commissione Ingegneria Forense) e ONIF (Osservatorio Nazionale Informatica Forense), dal titolo La Scienza del Digitale: evoluzione e riconoscimento della figura dell’Informatico Forense.
L’incontro si svolgerà Martedì 10 giugno, dalle 9:15 alle 16:30, presso la Sala Conferenze di Assoartigiani, Via Cefalonia 66 a Brescia.
Il programma è molto nutrito e si articola in una giornata di approfondimento tecnico-scientifico riguardo l’evoluzione dell’informatica forense, tra strumenti, intelligenza artificiale, responsabilità giuridiche e gestione delle prove digitali.
Sarò presente con un intervento intitolato “Domotica e IoT come fonte di prova: Analisi forense di Home Assistant”, dedicato all’analisi di sistemi ormai onnipresenti, ma talvolta ignorati nonostante la mole di dati che contengono:
La popolarità dei dispositivi IoT ha reso i sistemi domotici sempre più diffusi, ma essi sono spesso trascurati durante le analisi forensi tradizionali.
L’intervento vuole approfondire come Home Assistant, una delle piattaforme domotiche più popolari, può fornire informazioni potenzialmente molto preziose. Attraverso l’analisi dei dati raccolti da Home Assistant, si potrebbe tracciare il movimento dello smartphone dell’utente, accertare l’uso di dispositivi come televisori e luci, e persino identificare se una finestra della casa è stata lasciata aperta. Tutti questi elementi possono essere associati puntualmente a date e orari precisi, in modo da corroborare (o smentire) eventuali dichiarazioni.
Maggiori informazioni sul programma sono disponibili nella locandina, mentre l’iscrizione avviene tramite il portale di ISI Formazione:
La partecipazione all’evento è totalmente gratuita, ma è obbligatorio registrarsi. L’evento garantisce il riconoscimento di 6 CFP per gli ingegneri, e 4 crediti formativi per gli avvocati.
Materiale
L’evento non è stato registrato, ma potete scaricare le slide in PDFcliccando qui.
Il prossimo mese si terrà un evento organizzato da MSAB, con la collaborazione di NUIX, SANS ed E-Trace, dal titolo Nuovi Orizzonti per le Indagini Digitali Forensi: Sfide e Soluzioni. L’incontro avrà luogo l’8 maggio 2025, dalle 08:30 alle 18:30, presso il Grand Hotel Doria di Milano.
Insieme all’amico e collega Paolo Dal Checco, saremo presenti con un intervento intitolato “Web Forensics: Le nuove frontiere delle prove digitali”. Questo sarà dedicato alla sempre più frequente necessità di raccogliere elementi di prova dalle pagine web, che si scontra con l’aumentare della complessità dei siti web moderni.
Il programma è ricco e coprirà molteplici argomenti:
8:45 · Registrazione partecipanti
9:30 · Introduzione
9:45 · Non solo FFS, estrazioni fisiche BFU con XRY Ghennadii Konev & Giovanni Maria Castoldi
10:30 · Coffee break
10:45 · Not so private browsing! Mattia Epifani
11:45 · Rethinking digital investigations: beyond keyword searches Dario Beniamini
12:30 · Web forensics: le nuove frontiere delle prove digitali Paolo Dal Checco & Andrea Lazzarotto
13:15 · Pranzo
14:30 · SANS DFIR trainings: la formazione oltre l’aggiornamento Manlio Longinotti
15:00 · Perquisizione e sequestro del dispositivo “mobile” tra rispetto delle regole processuali e delle garanzie di parte Pier Luca Toselli & Roberto Murenec
15:45 · Coffee break
16:00 · Intervento E-Trace eTrace Digital Security
16:45 · Q&A, demo
18:00 · Termine
Maggiori dettagli sono indicati sul sito web di MSAB:
Recentemente ho iniziato a interessarmi al tema dell’acquisizione forense dei computer prodotti da Apple. Per i PC di altri produttori (solitamente con Windows o Linux) esistono vari programmi per fare una copia forense, ma con i Mac la scelta è piuttosto limitata e i pochi prodotti esistenti sono per di più costosi.
Per questo motivo ho deciso di creare un nuovo progetto. Fuji è un software per l’acquisizione forense per i Mac vecchi e nuovi, inclusi gli ultimissimi modelli con Apple Silicon. Permette di ottenere una cosiddetta estrazione Full File System, adoperando una semplice interfaccia grafica e senza righe di comando.
Interfaccia principale del programma
Fuji è un progetto completamente gratuito e open source, disponibile per il download su GitHub. Dopo averlo annunciato a maggio con un post su LinkedIn, ha avuto un riscontro piuttosto positivo dalla comunità.
Ad agosto sono stato intervistato dalla rivista di settore Forensic Focus, che mi ha fatto alcune domande sul mio lavoro, su questo progetto e sul perché l’ho iniziato:
Ho creato Fuji perché ci sono pochi programmi in grado di eseguire l’acquisizione forense dei Mac moderni. Molti sono costosi e nessuno è gratuito o open source.
C’è stata anche l’opportunità di parlare più in generale di quanto il software open source sia importante nel settore dell’informatica forense:
L’open source facilita la verificabilità di ciò che viene fatto. Immagina se, durante un processo in cui la prova del DNA gioca un ruolo cruciale, il biologo ti dicesse: “Non posso dire come ho estratto il DNA del sospetto dalla scena perché è un segreto commerciale, però fidati.”
Inoltre, ho il piacere di comunicarvi che il 29 settembre 2024 a Praga (Repubblica Ceca) si svolgerà l’annuale edizione del SANS DFIR Europe Summit, uno dei più importanti eventi a livello europeo nel settore dell’informatica forense.
Il programma è davvero folto, e tra le 11 presentazioni ben cinque saranno tenute da professionisti italiani! Sarò presente con un intervento intitolato “Fuji: A New Open Source Tool For Full File System Acquisition of Mac Computers”, proprio per presentare il mio progetto:
The advent of Apple Silicon introduced new challenges for forensic acquisition on macOS devices, as traditional imaging tools like dd or Disk Utility cannot be used due to hardware-level encryption. This issue inspired the creation of Fuji, a free and open-source tool designed for the forensic acquisition of Mac computers.
Fuji leverages native Apple utilities such as ASR and Rsync to perform a Full File System (FFS) live acquisition, thus working even on encrypted drives. It generates DMG files compatible with tools like FTK Imager and Autopsy.
We will explore what Fuji is capable of, the differences between its acquisition modes, and how it was developed using Python.
Maggiori informazioni sul programma e le modalità di iscrizione sono disponibili direttamente sul sito web di SANS:
Colgo l’occasione per ringraziare ONIF (Osservatorio Nazionale Informatica Forense) per il sostegno che mi ha dato nella partecipazione al convegno, nonché in quella degli altri colleghi e soci che presenteranno i loro progetti durante la stessa giornata.
Materiale
L’evento era riservato agli iscritti e non è stato registrato. Però potete scaricare le slide in PDFcliccando qui, oppure visualizzarle sul sito web di SANS.
Questo mese si terrà il primo evento congiunto organizzato da AIP (Associazione Informatici Professionisti) e ONIF (Osservatorio Nazionale Informatica Forense), che ormai da diversi anni sono associazioni di riferimento nei settori della sicurezza informatica e della digital forensics.
Il convegno SecureBiz 2024 si svolgerà Venerdì 10 maggio (09:30–18:00) e sabato 11 maggio 2024 (09:30–13:00), presso il Florence Visitor Center situato in Piazza della Stazione 4 a Firenze.
Il programma è molto nutrito e si articola su due giornate in cui diversi professionisti affronteranno gli aspetti cruciali per trattare gli incidenti informatici in azienda: prevenzione, mitigazione, analisi e gestione.
Sarò presente con un intervento intitolato “Ottenere risposte immediate dall’analisi dei file di log con SQLite”, dedicato all’estrazione rapida di informazioni chiave da una mole di dati spesso corposa:
Gli accertamenti tecnici relativi ad accessi abusivi e furti di dati informatici richiedono spesso l’analisi di grandi quantitativi di log, con migliaia di righe dalle quali è necessario riconoscere elementi ricorrenti e isolare le anomalie. Si rivela altresì importante correlare e incrociare log provenienti da fonti diverse.
L’intervento ha lo scopo di mostrare come utilizzare SQLite per l’analisi dei log e ottenere risposte in modo rapido ed efficace. Si tratta di uno strumento apparentemente semplice, ma molto potente che consente di ridurre il tempo necessario per ricostruire ciò che è avvenuto. Verranno mostrati due esempi pratici relativi ad accessi abusivi a sistemi informatici.
Maggiori informazioni sul programma e le modalità di iscrizione sono disponibili direttamente sul sito dell’evento e su EventBrite:
La partecipazione all’evento è totalmente gratuita, ma è obbligatorio registrarsi. Al momento sono ancora disponibili dei biglietti, perciò vi consiglio di non lasciarvi sfuggire questa opportunità!
Materiale
Potete scaricare le slide cliccando qui, mentre il video è disponibile su YouTube e qui sotto. Non dimenticate di seguire il canale di AIP, per accedere a tutti gli altri interventi della conferenza.
Se vi serve una consulenza tecnica a scopo legale sull’analisi dei file di log o sul furto di dati, potete richiedere questo tipo di servizio tramite la pagina dedicata.
Clicca qui per mostrare contenuto da YouTube. (leggi la privacy policy del servizio)
Da qualche giorno diversi utilizzatori del mio script per scaricare i video da Rai Play mi stanno segnalando che si riscontrano difficoltà nel salvare i video in formato MP4, in particolare in quanto compare un messaggio di errore.
A questo punto è necessaria una piccola parentesi tecnica per capire cosa sta succedendo: lo script funziona “scansionando” i possibili URL di file in formato MP4, quindi chiede al sito Rai quali sono le qualità disponibili (più o meno pesanti) e per ciascun file verifica che il video sia effettivamente scaricabile. Infine, propone all’utente una lista di URL.
Perciò lo script non effettua (né ha mai effettuato) alcun tipo di download. Si limita a mostrare un elenco di link, mentre è l’utente che deve scaricare il file che preferisce.
Data la natura di script che viene eseguito all’interno della pagina, tramite l’aiuto di una piccola estensione, esso si deve limitare ai file MP4. Sarebbe infatti molto complicato creare un programma che registra i flussi video in formato HLS, operazione che richiede il salvataggio di numerosi frammenti che poi vanno nuovamente assemblati.
Di fatto lo script sta funzionando in modo corretto: prova a vedere se ci sono i video in formato MP4 e propone all’utente quelli che si possono salvare. Il problema sorge quando non ci sono file MP4 scaricabili perché Rai li sta bloccando tutti.
Ed eccoci qua.
Serve un altro software per registrare i video
La scelta di usare il termine “registrare”, quando fino a oggi ho sempre parlato di scaricare, non è casuale. Come accennato, i video su Rai Play non sono disponibili solo in formato MP4 ma ci sono anche dei flussi (separati per audio e video) in HLS, che si riconoscono dalla tipica estensione M3U8.
I primi si scaricano, i secondi si devono registrare e questo esula dal mio script. Bisogna usare un programma che registri sia il flusso video che quello audio e poi li unisca insieme per generare un file MP4 o MKV che prima non esisteva.
Per farlo da riga di comando si può usare yt-dlp, che è un fork (versione derivata) di youtube-dl. In questo post vorrei però suggerire l’uso di Stacher, una interfaccia grafica che semplifica l’uso di questi strumenti.
Ci sono tre passaggi che devono essere svolti:
Installare Stacher e lo strumento ffmpeg
Configurare il software
Avviare la registrazione
I primi due passaggi devono essere svolti soltanto una volta, il terzo invece andrà ripetuto sempre.
Aggiornamento del 13 marzo 2024: grazie alla nuova versione del programma yt-dlp, gran parte di questa guida è ora “superflua”. Se volete solo il video in qualità massima installate Stacher e ffmpeg, poi saltate la parte di configurazione e andate direttamente in fondo alla fase di registrazione scegliendo la qualità “bestvideo+bestaudio”.
Sui pochissimi video in cui non dovesse funzionare quella voce, optate per la qualità “best” (funziona solo su programmi in cui non c’è la traccia audio a parte).
Lascio la versione precedente della guida per chi desidera scegliere la dimensione del video o il contenitore di uscita (MP4 / MKV).
Installare il necessario
Potete scaricare la versione 6 di Stacherdal sito ufficiale cliccando qui(copia di archivio). Il software è disponibile per macOS, Windows e Linux (DEB).
Dopo averlo installato, al primo avvio vi dovrebbe chiedere di scaricare youtube-dl (che in realtà sarà yt-dlp). Accettate e lasciate che proceda.
A questo punto è importantissimo scaricare e scompattare una versione specifica di ffmpeg nella cartella del programma. Ciò si può vedere anche cliccando sul menù Something not working? all’ultima voce, che tratta i problemi audio.
Cliccandoci sopra si aprirà questa pagina web con le istruzioni. A questo punto è importante fare una distinzione in base al sistema operativo usato.
Nota bene: saltando questo passaggio è quasi certo che verranno scaricati video senza audio, o si riscontreranno altri problemi.
FFmpeg su Windows
Il progetto yt-dlp fornisce delle versioni già compilate specifiche per Windows, pertanto si può consultare la pagina dei rilasci per vedere che ci sono diversi file ZIP.
Le versioni vengono rilasciate in automatico ogni giorno e purtroppo mi sono reso conto che quelle di alcune date non funzionano. Quando ho pubblicato l’articolo le ultime fornite erano versioni perfettamente funzionanti, ma non tutte sono ancora disponibili.
Vi invito caldamente a usare la versione del 14/02/2024. Essa attualmente non è più disponibile online, quindi ho ricaricato l’archivio sul mio account GitHub per preservarlo. Metto il link diretto allo ZIP su questo pulsante:
Poi è necessario importarlo usando la comodissima voce presente al menù Tools > Import FFmpeg *.zip file. Non bisogna fare altro.
FFmpeg su Linux e macOS
Su queste piattaforme lo strumento va installato con gli appositi gestori di pacchetti. Nel caso di macOS in particolare va usato Homebrew (potete fare riferimento al link indicato in precedenza).
Questo però non basta. Infatti sul sito Rai emerge un piccolo problema di comunicazione tra yt-dlp e ffmpeg che può far fallire la fusione delle tracce audio, nella fase di Postprocessing.
Per questo motivo ho preparato per voi tre script specifici che “mascherano” ffmpeg e correggono i parametri da passare al programma “vero”. Procedete così:
Aprite Stacher e andate su Tools > Open Stacher Home Folder
Copiate i tre file all’interno della cartella appena aperta
I tre file copiati all’interno della cartella di Stacher
In seguito la posizione corretta di ffmpeg dovrà essere configurata nelle impostazioni di Stacher.
Configurare il software
Purtroppo anche Stacher, tramite i suoi strumenti, va in confusione in quanto rileva la presenza di file MP4 ma non riesce a scaricarli. Dobbiamo pertanto “insegnare” al programma quali sono i flussi che deve registrare.
Aprite il menù Stacher > Settings > Advanced. Premete il pulsante per confermare che siete sicuri di ciò che state facendo. 🙂
Scorrete fino a trovare la voce Always run with these arguments, sbloccatela tramite il lucchetto a fianco e incollate la seguente stringa nella casella di testo:
Se usate Linux oppure macOS, dovrete anche tornare su alla voce ffmpeg location e selezionare la cartella dove avete copiato i tre file essenziali per registrare correttamente, cioè .stacher nella vostra home.
Vi ricordo che si tratta di una cartella nascosta, quindi potrebbe essere necessario attivare l’opzione per vedere i file nascosti. Generalmente va premuto Ctrl+H sui sistemi Linux e Shift+Cmd+.su macOS, ma verificate voi in base alla configurazione e versione del vostro sistema operativo.
Ora potete chiudere le impostazioni.
Le opzioni che abbiamo scelto servono a selezionare le qualità migliori tra i flussi video, inoltre istruiscono il programma per specificare che vogliamo unire anche eventuali flussi audio separati.
Questo comprende anche l’audiodescrizione o la lingua originale, se presente.
Se vi state chiedendo il perché della stringa Rai Lazza, in realtà non serve a niente, salvo a farvi riconoscere qual è l’opzione giusta al momento di far partire la registrazione. 😉
Avviare la registrazione del video
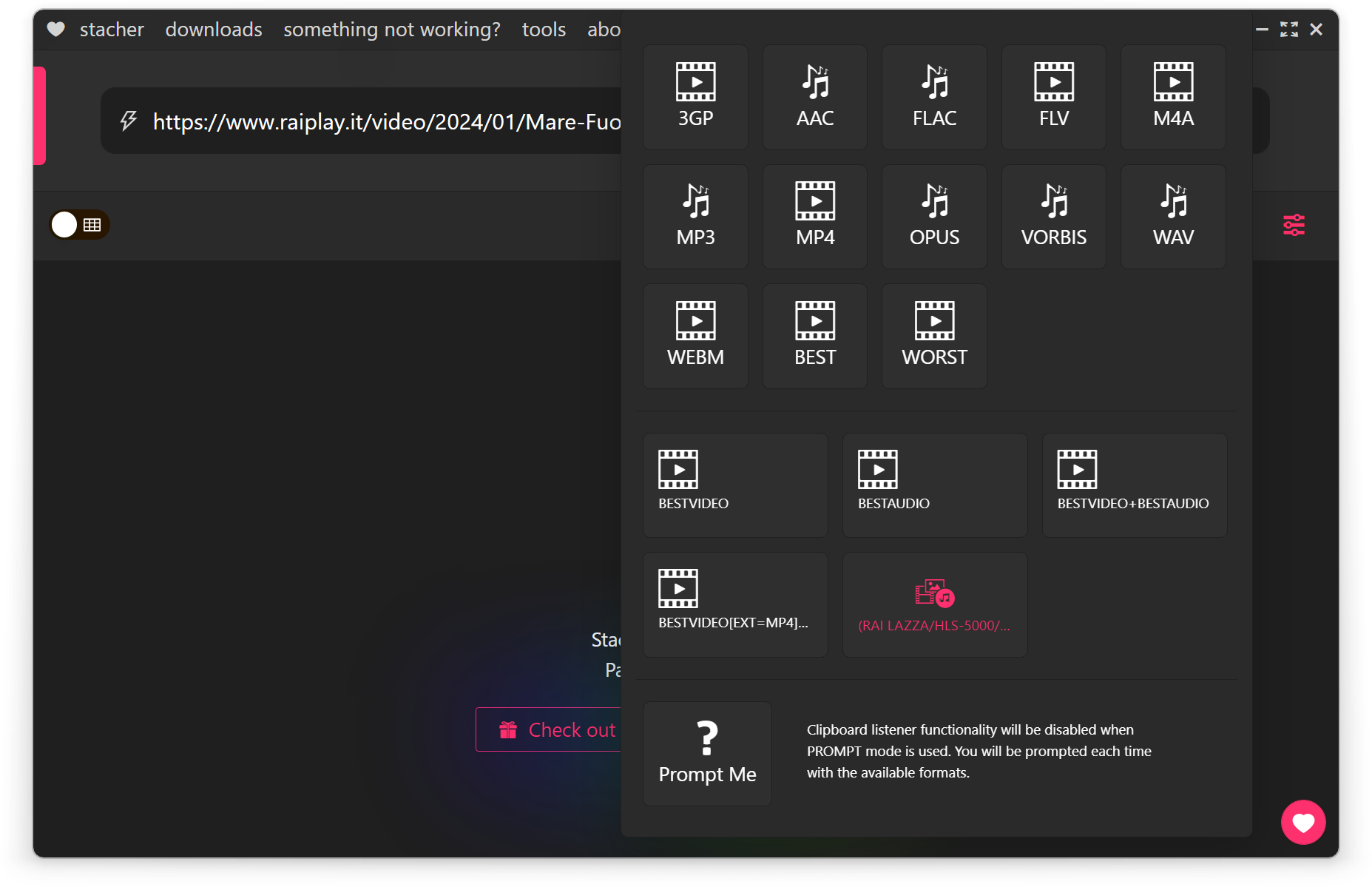
Nel momento in cui volete registrare una puntata da Rai Play, copiate l’URL della pagina del sito e incollatela nella barra di Stacher. Prima di tutto, assicuratevi di selezionare la qualità corretta del video, cliccando sul menù del formato.
Dovreste riconoscerla in modo abbastanza semplice dal nome “Rai Lazza”:
Lista dei formati disponibili nell’interfaccia di Stacher
Una volta selezionato il formato corretto, cliccate l’icona a forma di freccia verso il basso e attendete che il download venga completato. Per impostazione predefinita i video vengono collocati nella cartella Download, ma potete scegliere la posizione che preferite.
Il risultato sarà un file MP4 con le tracce unite, a meno che non decidiate di cambiare formato come descritto in fondo all’articolo.
Chi vuole sul serio qualcosa trova una strada, gli altri una scusa.
Proverbio di origine africana
Ovviamente questo è un metodo possibile, ce ne sono anche altri che consentono di scegliere quali tracce audio si desidera salvare, eccetera. Ma per iniziare dovrebbe essere sufficiente.
Se i file MP4 continueranno a essere in gran parte bloccati, il mio script per il browser avrà sempre meno senso di esistere. Chi lo sa, dopo tanti anni potrebbe andare finalmente in pensione!
Domande frequenti
Dopo aver ricevuto numerosi commenti al post, aggiungo una sezione relativa alle principali domande che sono state pubblicate dai lettori.
Perché su Windows il programma scarica tre file separati con video e tracce audio ma non li unisce?
Per un caso malauguratissimo, quando ho scritto l’articolo l’ultima versione del programma ffmpeg era perfettamente funzionante, ma alcune versioni rilasciate nei giorni successivi invece davano problemi. Chi ha seguito la mia guida nei primi tempi dopo la pubblicazione potrebbe aver riscontrato questo errore.
Perché su Linux e macOS il programma scarica tre file separati con video e tracce audio ma non li unisce?
Questo si verifica per un problema che dipende da come il software interagisce con ffmpeg. L’articolo è stato aggiornato fornendo degli script che aggirano il problema.
Come fare a ottenere un video in “formato” MKV?
In realtà MKV è un contenitore video, così come MP4. Il formato della traccia video sul sito Rai rimane comunque H264. Detto ciò, per cambiare il contenitore è sufficiente cambiare il parametro relativo al remuxing, per esempio così:
In sostanza dovete solo modificare la parte finale da mp4 a mkv.
I video sono in alta qualità, come si può registrare in bassa qualità?
Questa è forse la domanda più strana e inaspettata che potessi ricevere. Di solito le lamentele arrivano se un video si vede male, non se si vede bene. 🙂 In ogni caso, nella stringa consigliata ho incluso un filtro sulla larghezza (in pixel) del flusso video.
Potete notare che ci sono dei pezzi relativi al valore 9999:
best[width<=9999]
Questa stringa si ripete più volte. Per ottenere una qualità inferiore vi basterà rimpiazzare il valore 9999 con la larghezza massima che volete ottenere. Vi ricordo che molti video sul sito Rai sono disponibili in 1920×1080, 1440×810, 1280×720, 1024×568.
Dunque potreste scegliere di cambiare la stringa così:
Tuttavia dovete fare attenzione: non tutti i video sono disponibili in tutte le risoluzioni, perciò il valore indica solo un limite massimo. Potreste ottenere una qualità molto inferiore rispetto a quella che avete richiesto.
Perché si ottiene l’errore 403: Forbidden?
Generalmente i casi sono due: o vi trovate all’estero e la Rai vi sta bloccando, oppure non avete configurato il software come scritto nella guida.
Come si possono salvare i sottotitoli?
Conviene usare l’apposita opzione presente in Stacher, come ha consigliato l’utente Yupi in un suo commento.
Stacher registra solo da Rai Play o funziona anche con altri siti web?
Il software che si occupa di registrare i video è yt-dlp, il quale supporta centinaia di siti web. Tuttavia questo articolo è specifico per Rai Play e di conseguenza anche i parametri che vi ho consigliato.
Gli altri siti dovrebbero funzionare ma non escludo che i parametri che vi ho fatto impostare possano causare qualche “pasticcio”. Siamo comunque fuori tema rispetto a questo post. 😉
Aggiornamento del 12/02/2024: i parametri da inserire sono stati modificati per tenere conto di alcuni video con qualità “strane”, che altrimenti sarebbero sfuggite.
Aggiornamento del 25/02/2024: è stato aggiunto un metodo per risolvere i problemi di registrazione di alcuni video su Linux e macOS. Ho inserito anche una sezione di domande frequenti.
Aggiornamento del 27/02/2024: ora viene indicata una specifica versione di ffmpeg per Windows, per assicurarsi che chiunque segua la guida usi la stessa build.
Aggiornamento del 13/03/2024: grazie alla nuova versione del programma yt-dlp, alcune parti di questa guida sono ora superflue. Ho aggiunto una nota che spiega che gli utenti senza necessità particolari possono limitarsi a usare “bestvideo+bestaudio”.
Aggiornamento del 08/01/2025: ho modificato il link al sito di Stacher, per chiarire che la guida fa riferimento alla versione 6 del programma.
Anche quest’anno torna l’appuntamento con l’informatica forense con il convegno organizzato dall’associazione ONIF (Osservatorio Nazionale Informatica Forense). L’evento è giunto alla sua settima edizione, intitolata “Il favoloso mondo di Amelia pervaso da Digital Forensics e Cybersecurity”.
Il convegno si svolgerà Venerdì 20 ottobre 2023 dalle ore 09:00 alle 18:00, nella consueta e suggestiva cornice del Chiostro Boccarini di Amelia, un bellissimo borgo in provincia di Terni.
Il programma è davvero ricco, con interventi relativi all’informatica forense, la cybersecurity e l’informatica giuridica. Tra i relatori e ospiti si annoverano operatori delle forze dell’ordine, personalità istituzionali, giuristi e consulenti tecnici membri di ONIF.
Sarò presente con un intervento intitolato “Acquisizione forense con FIT — Stato dell’arte e prospettive future”, dedicato alla cristallizzazione di contenuti dal web:
L’acquisizione forense di contenuti da Internet è una tematica piuttosto ampia e in continua evoluzione, riguardando non solo semplici siti, ma anche contenuti multimediali, applicazioni web complesse e messaggi email.
Attualmente esistono diverse soluzioni proprietarie dedicate a questo tipo di lavoro.
Il progetto open source FIT, sviluppato attivamente da alcuni soci ONIF, mira a introdurre uno strumento di libero utilizzo, modulare ed estendibile per affrontare la raccolta dei contenuti tramite Internet.
L’intervento intende descrivere le caratteristiche peculiari di FIT, i vantaggi rispetto ad altre soluzioni, nonché alcune possibilità di sviluppi futuri per migliorarlo ulteriormente.
Maggiori informazioni sul programma, le modalità di iscrizione e gli alloggi convenzionati sono disponibili direttamente sul sito web di ONIF:
I biglietti sono letteralmente “andati a ruba” subito dopo l’apertura delle prenotazioni su EventBrite, tuttavia consiglio di tenere d’occhio la pagina ufficiale perché probabilmente verrà aperta una lista d’attesa, nel caso ci fossero cancellazioni.
Materiale
Potete scaricare le slide cliccando qui, mentre il video è disponibile su YouTube e qui sotto. Non dimenticate di seguire il canale di ONIF, per accedere a tutti gli altri interventi della conferenza.
Se vi serve una consulenza tecnica per documentare contenuti presenti sul web a scopo legale, potete richiedere questo tipo di servizio tramite la pagina dedicata.
Clicca qui per mostrare contenuto da YouTube. (leggi la privacy policy del servizio)
La serie di serate divulgative, gratuite e aperte a tutti del LUG di Vicenza continua fino a fine mese.
Il 20 giugno terrò un intervento dedicato agli adeguamenti necessari per poter pubblicare un sito web con WordPress in modo che sia rispettoso del GDPR e della privacy degli utilizzatori:
WordPress è il gestore di contenuti utilizzato dal 65% dei siti web che si basano su un CMS. Si tratta di una piattaforma versatile e completa, ma che può presentare alcune problematiche di privacy se usato nella sua configurazione predefinita.
Gli autori di siti web possono avere l’impressione che adeguarsi al GDPR sia un processo lungo, tedioso e oltremodo scomodo. Durante questo intervento vedremo che, in realtà, bastano davvero pochi e semplici aggiustamenti per garantire il massimo rispetto della privacy dei nostri visitatori.
Avremo modo di affrontare alcune tematiche piuttosto comuni relative ai banner che informano riguardo l’utilizzo dei cookie, ma anche gli embed di video da siti esterni e l’uso di dati personali nei commenti del sito.
Potete scaricare le slide cliccando qui, mentre il video è disponibile su YouTube e qui sotto. Il progetto Monk è scaricabile a questo indirizzo.
Se volete che il vostro sito venga aggiornato e controllato in modo professionale, potete richiedere questo tipo di servizio tramite la pagina dei contatti.
Clicca qui per mostrare contenuto da YouTube. (leggi la privacy policy del servizio)
Anche per l’anno 2023 il LUG di Vicenza sta organizzando una fitta serie di serate divulgative, gratuite e aperte a tutti.
Il 28 marzo terrò un intervento dedicato a una navigazione maggiormente consapevole, per fruire dei nostri contenuti preferiti ma con un occhio di riguardo alla tutela dei nostri dati personali, riducendo la profilazione e il tracking:
La maggior parte dei siti web e dei social network più famosi raccoglie moltissimi dati sugli utenti, spesso senza consenso, e utilizza queste informazioni per creare profili dettagliati che permettono di mostrare pubblicità sempre più mirata. Inoltre, spesso vengono usate tecniche di tracking per controllare le attività degli utenti anche fuori dalla piattaforma.
I frontend alternativi sono una soluzione che ci permette di fruire dei contenuti che ci interessano, riducendo però l’esposizione dei nostri dati e il tracciamento pervasivo. Durante la serata verranno illustrati alcuni esempi di frontend alternativi per siti popolari come YouTube, Twitter e Reddit, con informazioni pratiche su come utilizzarli al meglio.
Vedremo anche qualche consiglio utile applicabile su tutti i siti web.
L’enfasi sarà dedicata a questi interessanti strumenti, che sono facilissimi da usare, ma seguirà anche qualche piccola “chicca” relativa al rifiuto dei cookie-wall e alla riscoperta di una tecnologia un po’ trascurata, cioè i feed RSS.
Dal 12 al 14 settembre 2022 torna Treviso Forensic, uno dei principali appuntamenti tra professionisti (tecnici, avvocati, magistrati, …) che operano nel settore delle scienze tecniche applicate in ambito forense.
L’evento è organizzato dall’Ordine degli Ingegneri di Treviso, adotta un approccio multidisciplinare e predilige il confronto tra esperienze differenti utilizzando le tavole rotonde.
La mattina del 13 settembre conterrà una sessione interamente dedicata alla digital forensics, presieduta dall’Ing. Paolo Reale. Io parteciperò con un intervento intitolato “Nuove tecniche di analisi sulla falsificazione di chat WhatsApp e recupero dei messaggi originali”.
La successiva tavola rotonda sarà particolarmente interessante, in quanto verterà sulla tecnologia e i risvolti legali delle intercettazioni con il cosiddetto captatore informatico o “trojan di stato”, strumento che viene utilizzato anche in Italia in determinate situazioni.
Durante il mio talk darò alcuni spunti su degli accertamenti che si possono svolgere nel tentativo di rilevare le tracce dei messaggi WhatsApp falsificati, tematica che avevo introdotto in parte a Treviso Forensic 2020.
Quest’anno, il seminario si svolgerà sia in presenza al Campus Universitario di Treviso, sia online. Ci si può ancora iscrivere per entrambe le modalità.
Il 27 maggio 2022, dalle 14:30 alle 18:30, sarò relatore in un webinar interamente dedicato ai rudimenti della digital forensics, all’interno del ciclo di eventi “Cybersecurity: Concetti base e nel lavoro quotidiano”.
L’incontro, di natura divulgativa, verterà sulla disciplina dell’informatica forense all’interno del panorama legislativo italiano. Saranno introdotti i principali concetti di base propri della materia, il metodo scientifico, la normativa che regola i reati informatici e i tipi di analisi che possono essere svolte su computer e smartphone.
Tramite una dimostrazione del software Autopsy, i partecipanti potranno anche vedere dal vivo una parte del lavoro di analisi svolto su un caso pratico. L’intervento è particolarmente consigliato a informatici, consulenti tecnici, avvocati, giuristi, ingegneri e appassionati di discipline tecnico-scientifiche.
Il talk si svolgerà online e sarà trasmesso in streaming su piattaforma Google Meet. Per partecipare è obbligatorio iscriversi gratuitamente tramite Eventbrite:
Va precisato che un’eventuale registrazione video verrà messa a disposizione solamente a coloro che si sono regolarmente iscritti all’evento.
L’evento è organizzato da InnovationLab Dolomiti, un progetto finanziato dalla Regione Veneto, con l’obiettivo di qualificare le competenze digitali per incrementare la consapevolezza sui temi dell’innovazione e della digitalizzazione.