Video della seconda serata delle Ubuntu Nights, svoltasi a Bassano del Grappa (VI) il 27 giugno 2012. Roberto Pigato spiega come personalizzare Ubuntu con temi, icone e wallpaper a rotazione.
Le serate sono realizzate da GrappaLUG.
Informatica forense, sviluppo software e consulenza
Video della seconda serata delle Ubuntu Nights, svoltasi a Bassano del Grappa (VI) il 27 giugno 2012. Roberto Pigato spiega come personalizzare Ubuntu con temi, icone e wallpaper a rotazione.
Le serate sono realizzate da GrappaLUG.
Video della prima serata delle Ubuntu Nights, svoltasi a Bassano del Grappa (VI) il 13 giugno 2012. Michele Piotto spiega come installare Ubuntu e procedere alle prime configurazioni.
Le serate sono realizzate da GrappaLUG.
È già da un po’ di tempo che se ne parla, i siti di alcune delle maggiori televisioni (Rai e Mediaset) utilizzano la tecnologia Silverlight per pubblicare molti video che si possono (ri)vedere online. Si tratta di un sacco di programmi, fiction, telegiornali, eccetera forniti direttamente dalle suddette reti televisive, quindi si tratta di uno streaming perfettamente legale.
Il problema è che Silverlight è una tecnologia proprietaria di Microsoft che non è molto ben supportata da Linux. È vero, esiste il progetto Moonlight (sostanzialmente fermo), il quale però non supporta a pieno la riproduzione dei video di questi portali. Inoltre non è possibile scaricare le puntate offerte con tecnologia Smooth Streaming allo stesso modo in cui si fa solitamente con i siti che pubblicano video in Flash. Perciò tutto questo complica usi perfettamente legittimi (e prevedibili) dei video, come ad esempio poterli guardare in treno senza avere un computer con connessione 3G.
Per Linux esiste un progetto chiamato smooth-dl, realizzato da Antonio Ospite, un prolifico sviluppatore di software libero. Per i dettagli sul progetto e la tecnologia di Smooth Streaming, vi rimando al suo articolo che è scritto molto meglio di quanto potrei fare io.
Smooth-dl è però ancora in uno stato “non perfetto”, nel senso che non supporta tutti i siti che offrono video con questa tecnologia, ma lavora bene con il sito Rai. Esiste un software più completo chiamato ismdownloader, che però è realizzato per Windows. Perciò ho deciso di realizzare uno script che “maschera” il programma sotto Wine, e arricchisce la visualizzazione dello stato del download calcolando la percentuale rimanente e mostrandola a video. Di seguito vi spiegherò come effettuare la prima configurazione e poi usare lo script. Se volete fare la stessa cosa usando Mac OS X leggete la guida dedicata.
Per evitare di “far confusione” e mischiare il programma che useremo per il download con altri eventuali software che girano sotto Wine, vi farò creare un “contenitore” personalizzato con una copia a se stante del disco “C:” simulato. Per prima cosa quindi nel terminale create la directory, dichiaratela come il prefisso di Wine che andrete ad utilizzare e poi “forzate” Wine all’uso dell’architettura a 32bit:
mkdir -p $HOME/.smoothwine export WINEPREFIX=$HOME/.smoothwine WINEARCH=win32 winecfg
Appena finisce di creare la configurazione e vi apre la finestra di Wine, potete chiuderla e proseguire. A questo punto vi servirà Winetricks, che solitamente (perlomeno su Ubuntu) viene installato assieme a Wine, altrimenti provvedete ad installarlo dal vostro gestore di pacchetti. Winetricks si occuperà di scaricare l’ambiente .Net Framework, che servirà poi ad eseguire il programma per il download vero e proprio dei video:
winetricks dotnet20
Seguite la semplice procedura nella finestra che si aprirà e .Net verrà installato. Ora non vi resta altro da fare che cliccare questo link e salvare il file EXE, per poi copiarlo nella cartella che potete aprire usando questo comando:
xdg-open $WINEPREFIX/drive_c
Questo termina la configurazione di Wine. Giunti a questo punto potete procurarvi una copia dello script smooth.sh col comando seguente, che lo salva nella vostra cartella home:
wget "http://cl.ly/code/3d063j2H1p1M/smooth-lin.sh" -O $HOME/smooth.sh chmod +x $HOME/smooth.sh
Ovviamente se volete potete spostarlo dove vi pare, l’importante poi è richiamarlo correttamente.
La parte di configurazione di cui sopra andrà fatta solo la prima volta, in seguito potete limitarvi all’utilizzo dello script come segue. Supponendo che lo script sia nella vostra home e la vostra directory corrente nel terminale sia altresì la medesima cartella, potete semplicemente richiamarlo come segue:
./smooth.sh "http://url/del/manifest" "nome"
Il primo parametro sarà l’URL del cosiddetto file “manifest” relativo al video. Qui viene il problema: ogni pagina web avrà un manifest diverso, e il metodo per ricavarne l’URL varia da sito a sito. Per questo motivo non posso dirvi dettagliatamente come fare a trovarlo in generale, perché la spiegazione sarebbe molto lunga. Per certi siti come quelli di Rai e Mediaset ci sono già delle indicazioni in rete, in ogni caso questo sarà oggetto di un mio prossimo articolo, dedicato appositamente a scovare gli URL dei video online.
Il secondo parametro è il nome (preferibilmente senza spazi) desiderato per il file video (senza estensione). Una volta terminato il download, il video verrà salvato nella vostra home con estensione MKV. Sebbene il contenitore sia Matroska, la codifica vera e propria di audio e video dipende soltanto dal sito web da cui scaricate, quindi potrebbe variare. In ogni caso con VLC e gli opportuni codec dovreste riuscire a visualizzare tutto e potete sempre convertire i video con Arista Transcoder.
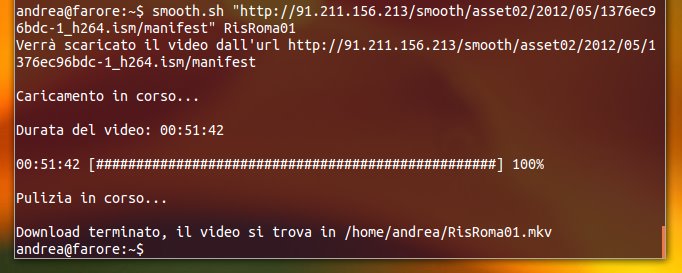
Come ogni cosa, anche lo script ha i suoi limiti. Il download non si può mettere in pausa, perché il programma originale non lo permette, e ogni tanto succede che l’eseguibile sotto Wine vada in crash. In generale comunque funziona bene, e avendo aggiunto il calcolo della percentuale (non presente in origine) penso di averlo reso abbastanza gradevole anche dal punto di vista estetico. La codifica del video finale è un po’ un terno al lotto, ma quasi sempre non crea nessun problema con VLC.
L’unico difetto visibile dei video è la presenza sporadica di lievissime macchioline nere, ma a dire il vero non so se imputare la cosa al programma che si occupa del download oppure al sito web che fornisce i video. In definitiva comunque i risultati sono buoni e con una risoluzione niente male. Il prezzo da pagare è l’uso di Wine e di qualche componente proprietario, ma d’altronde abbiamo a che fare con tecnologie Microsoft ed è difficile evitarlo del tutto.
Un’altra cosa (facilmente sistemabile) è che gli MKV prodotti possono dare problemi con l’avanzamento veloce e il riavvolgimento. Leggete questo articolo per sapere come risolvere. 😉
Spero di poter finire presto anche il post dedicato a “scovare gli URL” in modo da poter completare questa serie di articoli sul salvataggio dei video, che sembrano essere i più gettonati nel blog. Che ne pensate dello script? Vi tornerà utile?

Ieri è arrivata a tutti gli utenti di Spool una email di avviso che notificava la chiusura del servizio, e conteneva un allegato con i link salvati nel proprio account. Le parti salienti sono:
Dear Spooler,
We’re writing to inform you that Spool has shut down. Your bookmarks are attached to this email. […] It’s been a pleasure to build Spool for you and we’ve been flattered with the overwhelmingly positive feedback we’ve received. However, after careful consideration, we’ve decided to pursue our vision in a new way. […]
Successivamente è stato pubblicato nel loro blog l’annuncio ufficiale dell’acquisizione e le istruzioni per salvare i propri “segnalibri”. Ed è proprio qui, secondo me, che c’è stato il grande fraintendimento di fondo.
Spool è nato come servizio per poter fruire in modo semplice dei contenuti video in flash disponibili online. In sostanza, trovandosi di fronte a un video in Flash su Android o iPhone, bastava inviare il link a Spool e il sito si occupava di registrarlo, convertirlo e salvarlo per la visualizzazione sul telefono, anche offline.
Era una funzionalità esclusiva di Spool, ancora attualmente non esiste un altro servizio di memorizzazione di pagine da leggere che sia in grado di fare lo stesso, e sappiamo bene come l’esigenza attuale non sia solo quella di scaricare e convertire video sul PC ma anche di farlo sul proprio dispositivo mobile, specialmente ora che anche su Android sta cominciando a sparire Flash (per fortuna, aggiungo io).
Dopo un certo periodo di tempo, Spool ha cominciato a inserire una nuova funzione di “social bookmarking”, cercando di scimmiottare piuttosto male una via di mezzo tra Twitter e Delicious, perdendo di vista qual era l’obiettivo di vera unicità: l’accesso ai video. Quindi si è arrivati ad un punto in cui per poter vedere un video, si doveva avviare una sorta di processo di salvataggio e condivisione di un segnalibro (e quindi togliere ogni volta la casella di spunta) semplicemente per dire al programma “registrami ‘sto video e poi riproducilo”.
Questo tipo di cambio improvviso di rotta mi ha confuso non poco, e penso lo stesso valga per molti utenti “dei primi tempi” di Spool. Ora il servizio ha chiuso e consiglia di passare a Delicious o Pocket (ex Read It Later) i quali sono buoni servizi ma non hanno alcuna funzione equiparabile al generico “registratore di video” che funzionava su qualsiasi sito, persino sulle presentazioni SlideRocket! La cosa da sperare vivamente è che Facebook sappia fare buon uso della funzionalità e riportarla a disposizione degli utenti, ma finora nessuno sa come andrà a finire. Voi che ne pensate?
A causa di un piccolo disguido abbiamo dovuto spostare (in termini di luogo) le ultime due serate delle già annunciate Ubuntu Nights. I talk si svolgeranno sempre a Bassano del Grappa (VI), ma stavolta al Patronato della Santissima Trinità, a fianco del Color Cafè.
Vi devo avvertire inoltre che sono stati scambiati gli appuntamenti dell’11 e del 25 luglio: vale a dire che l’11 ci sarà il mio talk sui PPA, mentre il 25 quello su Gnome 3. Questo comunque non dovrebbe essere un problema visto che in genere chi partecipa alle nostre conferenze ama esserci a tutto il ciclo senza perdersi neppure un appuntamento. 😉
Come sempre trovate tutte le informazioni più aggiornate sul volantino ufficiale e presto anche sul sito e nel Twitter di GrappaLUG.
GrappaLUG organizza, a partire dal 13 giugno, le Ubuntu Nights: quattro serate a Bassano del Grappa per scoprire tutte le caratteristiche dell’ultima versione di Ubuntu e imparare a personalizzarla in ogni dettaglio.
Vi riporto parte della locandina ufficiale che potete trovare linkata in basso per tutti i dettagli su luoghi, date, orari e descrizioni particolareggiate:
La nuova versione di Ubuntu, la distribuzione Linux più diffusa al mondo, introduce alcune novità che la rendono ancora più completa e semplice da usare. In una serie di 4 serate verranno introdotti i temi principali da conoscere per scoprire anche alcuni degli aspetti meno conosciuti.
L’ingresso è libero e gratuito.
via Ubuntu Nights.
Vi avevo già scritto che ho cancellato Windows dal primo giorno in cui ho ricevuto il mio portatile e anche che mi era stato possibile trovare un modo per aggiornare lo stesso il BIOS. Purtroppo la guida che avevo scritto è valida solo per computer Dell, e non è neppure troppo semplice da seguire. Non solo, non sono neppure sicuro sia ancora valida.
Giusto oggi sono per caso venuto a conoscenza che già da un po’ era uscita una nuova versione del BIOS per il Dell XPS M1530 e ho trovato quasi per caso un modo semplicissimo per aggiornarlo: è sufficiente infatti creare un disco live minimale di FreeDOS per permettere al programma di partire. Il metodo che vi vado a spiegare prevede che il produttore del PC fornisca un file eseguibile di aggiornamento che sia compatibile con MS-DOS, fortunatamente questo succede quasi sempre.
La procedura si basa sulle indicazioni di CGSecurity per fare un disco live di TestDisk e nell’esempio uso il nome del mio file, specificamente 1530_A12.EXE. Dovete naturalmente adattare le istruzioni cambiando il nome.
Assumendo che abbiate il file eseguibile a portata di mano, scaricate il kit per creare dischi FreeDOS e scompattatelo:
wget -N http://www.fdos.info/bootdisks/ISO/FDOEMCD.builder.zip unzip FDOEMCD.builder.zip cd FDOEMCD/CDROOT
Ora tenete aperto il terminale nella directory in cui siete appena entrati (CDROOT) e con il file manager copiateci dentro l’eseguibile. A questo punto dovete aggiungere una riga al file AUTORUN.bat:
echo "M1530_A12.EXE" >> AUTORUN.BAT unix2dos AUTORUN.BAT
L’ultimo comando ci assicura di avere il file correttamente formattato per sistemi DOS (se non avete il pacchetto dovrete installarlo). Non resta altro da fare che generare l’immagine ISO da masterizzare (la troverete dentro a FDOEMCD):
cd .. mkisofs -o bios-update.iso -V "Bios CD" -b isolinux/isolinux.bin -no-emul-boot -boot-load-size 4 -boot-info-table -N -J -r -c boot.catalog -hide boot.catalog -hide-joliet boot.catalog CDROOT
Fatto ciò vi consiglio caldamente di testare il disco in una macchina virtuale. Ovviamente non riuscirà a procedere con l’aggiornamento, ma almeno potrete assicurarvi che parta correttamente. Dato che la ISO avrà una dimensione irrisoria e userete il disco una volta sola, vi raccomando l’uso di un CD-RW. 😉
A dire il vero non mi capita spesso di utilizzare Wine, per il semplice fatto che in genere trovo per Linux tutto ciò di cui ho bisogno. Tuttavia in questo periodo sto facendo un lavoro di gruppo per un esame e ho deciso di installare il client Windows di Evernote per sfruttare le funzioni che l’interfaccia web non offre. Avevo provato Nevernote/Nixnote ma a volte scombina il layout di alcune note, e comunque si tratta solo di una situazione temporanea.
Se c’è una cosa che non apprezzo particolarmente di Wine, comunque, è la perseveranza con cui rimane non integrato con tutto il resto del sistema. Ovviamente non si può pretendere di avere un look perfettamente analogo a GNOME o KDE, però non capisco proprio come la loro implementazione del font Tahoma (basata in realtà sul Bitstream Vera Sans) sia stata realizzata di proposito con i caratteri senza antialiasing a determinate dimensioni, per imitare il comportamento discutibile di alcune versioni di Windows.
Per chi non lo sapesse, l’antialiasing (o più precisamente l’hinting, nel caso dei font) è una sfumatura dei pixel per migliorare la leggibilità. Sapete già che sono abbastanza esigente dal punto di vista dell’integrazione grafica dei software, però in questo caso costituisce anche un problema serio di leggibilità delle finestre.
Ho scoperto recentemente che si può installare il Tahoma semplicemente usando winetricks e questo risolve parzialmente il problema. Tuttavia personalmente ho notato che Evernote continuava a non metterlo in alcune schermate (e presumibilmente anche altri programmi per Windows). Per questo motivo ho deciso di trovare una soluzione alternativa e già che c’ero anche di applicare un tema trovato in rete tempo fa. Il procedimento non è lungo ma il risultato è molto soddisfacente.
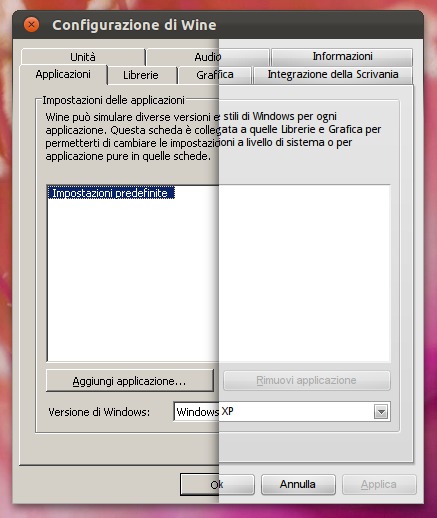
Partiamo dal tema: si tratta di uno stile per Windows XP chiamato Wooden e lo potete scaricare da questo sito russo (cliccate dove vedete scritto “wooden.zip [7.74 Mb]“). Una volta scompattato, andate nelle preferenze di Wine alla scheda Integrazione della Scrivania e premete Installa un tema: Vi verrà chiesto di scegliere il file con estensione .msstyles. Tenete presente che in alcune finestre i bottoni rimarranno senza angoli arrotondati, però in genere avrà tutto un’aspetto migliore e i colori somiglieranno al tema di Ubuntu.
Riguardo ai font, la mia idea è stata quella di usare la famiglia Droid Sans (quella dei primi dispositivi Android, per intenderci) e inserire nella cartella di sistema di Wine una copia dei file appositamente rinominati. Per farlo, dovrete assicurarvi tramite il Software Center (o gestore di pacchetti della vostra distribuzione) di avere installati questi font e anche il pacchetto fonttools, necessario per quello che andremo a fare tra poco. Per installarli su Ubuntu si può fare così:
sudo apt-get install ttf-droid fonttools
A questo punto è il momento di copiare i font nell’apposita directory:
cd ~/.wine/drive_c/windows/Fonts/ cp /usr/share/fonts/truetype/ttf-droid/DroidSans.ttf tahoma.ttf cp /usr/share/fonts/truetype/ttf-droid/DroidSans-Bold.ttf tahomabd.ttf
Come anticipato prima, ai font dev’essere attribuito un nuovo nome. Non è sufficiente rinominare i file perché all’interno contengono salvato il nome originale. Andiamo quindi a convertire i file in formato XML per poi sostituire il nome con Tahoma:
ttx tahoma*.ttf rm tahoma*.ttf sed -si "s/Droid\ Sans/Tahoma/g" tahoma*.ttx sed -si "s/DroidSans/Tahoma/g" tahoma*.ttx ttx tahoma*.ttx rm tahoma*.ttx
In sostanza dopo la prima conversione sostituiamo con sed tutte le occorrenze necessarie e poi procediamo alla riconversione, mentre i comandi rm fanno pulizia quando serve. A questo punto il gioco è fatto, basta avviare un programma che gira con Wine per notare la differenza. Ho provato anche con altri font, compreso quello di Ubuntu, ma i risultati erano meno soddisfacenti. Voi che ne dite? 🙂
Fino all’anno scorso, lo ammetto, avevo un comportamento poco corretto (e soprattutto poco sicuro) in termini di password. Come molte persone, utilizzavo una manciata di 3 o 4 parole d’ordine abbastanza semplici per quasi tutti i siti web.
Questo tipo di scelta può sembrare comoda, ma ha delle conseguenze molto serie in termini di sicurezza: per fare un esempio, se vi registrate su un forum con la stessa password che usate per la casella email, il proprietario del sito potrebbe riuscire a violare la vostra posta elettronica e utilizzarla per inviare spam.
Inizialmente ero un po’ riluttante a cambiare la situazione, ma poi qualche mese fa mi sono deciso. Mi ha incentivato il fatto che mi sono “inventato” un metodo per generare password diverse per ciascun sito, riuscendo allo stesso tempo a ricordarle tutte (o alla peggio, riducendo a 2 o 3 i tentativi in caso non le ricordassi). Non mi ha stupito affatto scoprire alcuni giorni fa che non sono stato il primo ad usare questo meccanismo. Infatti la fondazione Mozilla aveva pubblicato online un video estremamente chiaro e semplice.
Ne sono venuto a conoscenza nella newsletter inviata il 29 febbraio agli iscritti al sito di Firefox, ma il video è del 2011 ed è stato inserito recentemente in una guida che lo spiega in dettaglio. In realtà il mio metodo è lievemente diverso per la scelta della “parte fissa” e qualche altra piccolezza, ma tutto sommato è analogo.
Come potete notare è molto facile da usare e non richiede grandi sforzi di memoria. Quando ho iniziato ad adoperarlo, mi sono impegnato ad esportare da Firefox tutte le password salvate e iniziare a modificare quelle più semplici e soprattutto quelle dedicate ai siti più importanti o utilizzati. In particolare, vi consiglio di controllare (ed eventualmente aggiornare) le password di:
Il metodo più semplice per aggiornarsi tutte le password (o quasi) è quello di sistemarne una alla volta man mano che ci si trova a fare login in un sito e si nota che la password usata è troppo semplice. Provateci e ben presto avrete messo in sicurezza tutto quanto.
In realtà esistono anche dei casi in cui una password semplice può andare bene. Pensate ad esempio ad un sito che vi permette solo di fare un mini biglietto da visita online con link al vostro profilo Facebook e Twitter. In tali circostanze un malintenzionato potrebbe, nel peggiore dei casi, modificarvi il nome o l’avatar e poco altro. Tuttavia dev’essere l’eccezione e non la regola.
Se siete utenti Google (specialmente Gmail, ma non solo) vi consiglio anche di attivare la funzionalità per il login in due passaggi (il concetto è simile all’autenticazione biometrica) che aggiunge un livello di sicurezza niente male. Il sistema è spiegato benissimo in questo post di Roberto Scaccia.
Spero che questo post sia utile a spronare chi di noi è un po’ più pigro in fatto di password, dimostrando che non è poi così difficile cambiare metodo. Voi che ne pensate? Avete altri meccanismi per proteggere i vostri account? Fatemi sapere!
Circa tre settimane fa sono stato contattato dalla divisione tedesca di CONVAR, un’azienda che si occupa di soluzioni professionali di Data Recovery. Mi hanno scritto per propormi una recensione del loro nuovo prodotto, chiamato BytePac. Non mi capita spesso di fare recensioni di prodotti, ma avendone letto le caratteristiche e visto un video del suo utilizzo, mi ha colpito particolarmente ed ho deciso di accettare facendone una prova imparziale e critica.
Oltretutto, con GrappaLUG spesso e volentieri ci troviamo a lavorare per il recupero e la reinstallazione di PC più o meno vecchi. Per questo utilizziamo frequentemente dei cavi di collegamento da IDE/SATA a USB prodotti perlopiù in Cina (almeno quello che possiedo io). Avere la possibilità di riceverne uno tedesco e valutarne la qualità mi è sembrato parecchio interessante.
A una prima impressione si potrebbe dire che “BytePac è un case per hard disk SATA”: fin qui non sembra nulla di entusiasmante né innovativo. Basta però dire che è fatto totalmente in cartone e già la cosa si fa interessante! Infatti è un prodotto unico nel suo genere, viene spedito imballato in una scatola che è essa stessa parte del kit e può essere utilizzata per archiviare fino a 3 dischi.

La confezione contiene tre BytePac in cartone e l’insieme dei cavi di collegamento (quindi si può usare un’unità alla volta, il che è perfettamente ragionevole).
Nel video ufficiale di presentazione del prodotto lo potete vedere direttamente in azione:
Come si può notare il kit è estremamente semplice e veloce da utilizzare. Inoltre contiene ciò che serve, senza inutili fronzoli che si trovano solitamente nei vari tipi di case per hard disk.
Non avrei scritto questo post se non avessi notato qualche differenza rispetto ad altri prodotti dello stesso tipo (sarebbe stato inutile annoiarvi con cose già viste). Però secondo me le differenze ci sono e sul sito ufficiale potete trovare un decalogo dettagliato dei vantaggi di BytePac. Io vorrei soffermarmi solo su quelli che personalmente trovo più interessanti:
Forse ho un po’ divagato, però mi sembravano gli aspetti più importanti. Dal punto di vista tecnico comunque si può dire che la “struttura” in carta è stata davvero ben pensata, fornendo un’ottima areazione al disco e allo stesso tempo un collegamento con cavi di ottima qualità. Il fatto di usare un adattatore intermedio consente di cambiare tipo di connessione in futuro (ad esempio da USB2 a USB3 oppure Thunderbolt) assicurando di poter sempre accedere ai dati.
Come tutte le cose, anche BytePac ha alcuni lati negativi. Vi elenco le mie impressioni in merito:
Secondo me BytePac è davvero un prodotto interessante, sotto punti di vista che non riguardano solamente l’ambito informatico. Penso che alla fine gli aspetti migliorabili non ne pregiudichino affatto la qualità complessiva. Voi che ne dite?
Qui in fondo metto la galleria completa delle foto che ho fatto durante il test, così potete vedere bene come è fatto e come funziona.











