
Al giorno d’oggi capita sempre più frequentemente di dover acquisire delle prove dai siti web, in particolar modo dai social network. Ci si trova quindi a dover “cristallizzare” il contenuto di una pagina prima che venga alterato oppure cancellato.
Il caso più classico è quello della diffamazione a mezzo Internet: la vittima del fatto ha la necessità di certificare l’offesa alla propria reputazione, avvenuta tramite un commento su un blog o un post su Facebook.
Un’altra circostanza piuttosto frequente è la tutela della proprietà intellettuale e industriale. Le pagine social aziendali attirano potenziali clienti e sono un ottimo strumento di marketing. Dei soggetti terzi potrebbero sfruttare illecitamente marchi, foto di prodotti o contenuti altrui a proprio vantaggio.
Quest’ultimo è un caso che mi è capitato recentemente: la pagina Instagram di un’azienda è stata indebitamente acceduta da una persona che se ne è appropriata, cambiandone il marchio e i dati di contatto. Questo fatto ha comportato l’alterazione di dati informatici (vedasi art. 635 bis c.p.), nonché un evidente danno all’azienda in quanto si è vista sottrarre anche numerose foto dei propri prodotti e i follower della pagina.
Lo screenshot non basta
In tutti questi casi c’è da fare una breve ma importantissima precisazione. Purtroppo alcune persone ritengono ancora sufficiente l’utilizzo degli screenshot come “prova” in un procedimento civile o penale. Il pensiero comune è:
Ho fatto lo screenshot! Ora lo trasmetto al mio avvocato e ti querelo!
Questo ragionamento fa acqua da tutte le parti.
Uno screenshot, vale a dire l’immagine dello schermo (o presunta tale) che “cattura” il contenuto di un sito web o una chat, non si può considerare una prova valida.
Il contenuto di una schermata può essere infatti alterato sia prima che dopo aver prodotto lo “scatto”. Tutto questo non richiede conoscenze tecniche particolarmente elevate, specialmente per le pagine web.
Se non vi ho convinto, potete sempre farmi i complimenti per la mia nomina a “Persona dell’anno 2019”. 😉
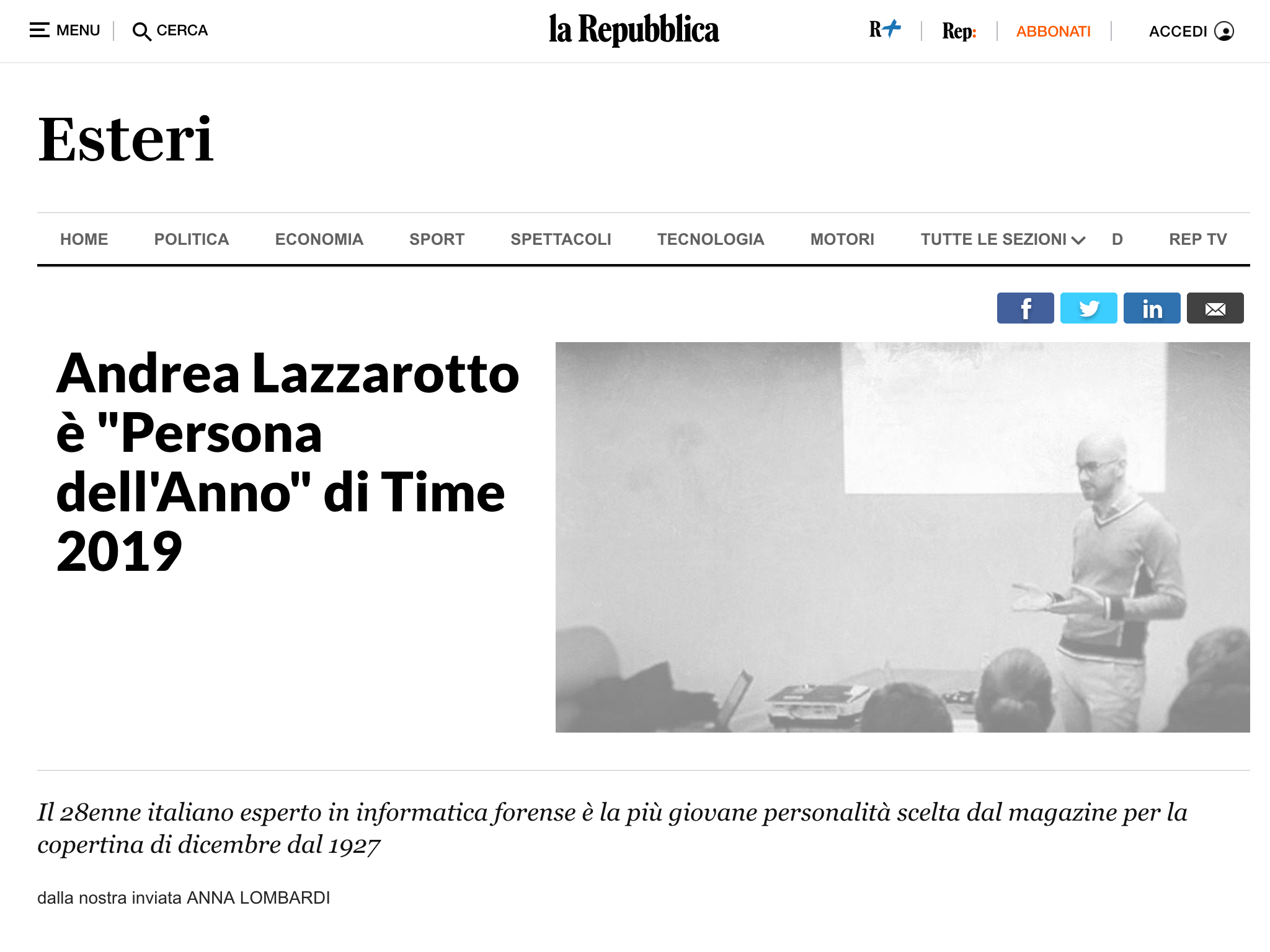
Ovviamente avrete capito che l’immagine qui sopra non è reale. Ma il punto è che si tratta veramente di una notizia comparsa online, che però è stata modificata prima di catturare la schermata.
Questa è una operazione alla portata di molti (se non quasi tutti), ma anche la modifica dell’immagine a posteriori è un rischio non indifferente.
Per questi motivi, la raccolta della prova che un contenuto è stato pubblicato non si può limitare a uno screenshot. Si deve procedere a cristallizzare la pagina in modo adeguato, prima che venga ulteriormente modificata o rimossa.
Acquisizione di base con i siti di archiviazione
Quasi tutti i profili Instagram sono pubblicamente accessibili. Questo perché Instagram è una vetrina dove le aziende possono rendersi visibili e condividere foto dei prodotti o altri contenuti interessanti per aumentare il proprio seguito.
Anche le persone non iscritte possono vedere i profili, utilizzando un semplice browser web. Pertanto, queste pagine si possono cristallizzare in modo semplice come molti altri siti.
Prendiamo ad esempio il profilo della nota catena statunitense Target: https://www.instagram.com/target/
Il modo più facile di cristallizzare pagine pubbliche come questa è adoperare i siti di archiviazione. Questi strumenti forniscono all’utente la possibilità di inserire l’indirizzo (URL) di un documento informatico pubblicato sul web, producendone quindi una copia informatica.
I principali sono:
- Wayback Machine (gestito da Internet Archive)
- Archive.today (anche conosciuto come archive.fo, archive.is, archive.md, eccetera)
Esistono anche degli strumenti molto più sofisticati e costosi, come ad esempio FAW, usati professionalmente da chi si occupa di digital forensics. Tuttavia, qui mi voglio focalizzare su degli strumenti di base e relativamente semplici.
I siti di archiviazione sono mezzi gratuiti e alla portata di tutti, che permettono di agire in fretta quando si teme che un contenuto compromettente possa essere cancellato, anche prima di essersi rivolti a un consulente tecnico specializzato e/o a un avvocato.
Per acquisire un contenuto con Wayback Machine, bisogna inserirne l’URL nell’apposito modulo di salvataggio, attivare l’opzione che salva anche lo screenshot e poi procedere col pulsante Save Page.
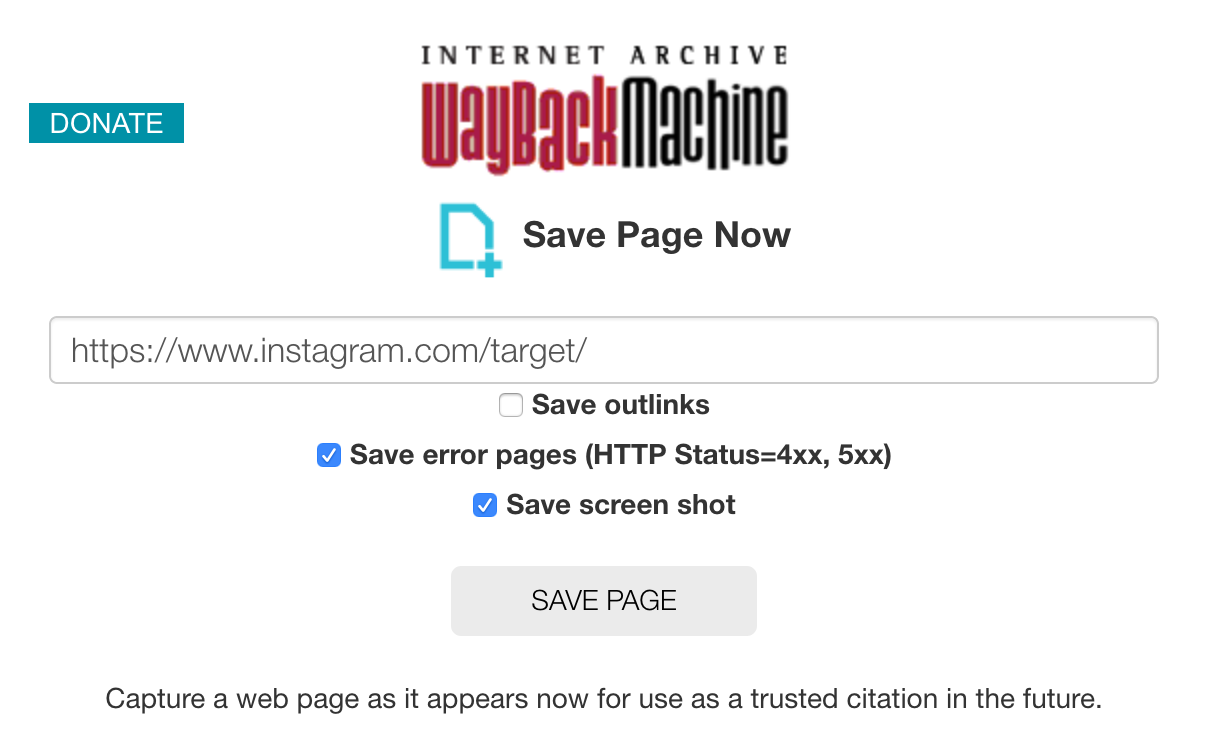
A questo punto, Wayback Machine simulerà l’azione di un vero browser e acquisirà il contenuto della pagina comprensivo di codice sorgente (HTML, CSS, JS) e risorse statiche (immagini e eventuali allegati PDF).
Al termine della procedura, si otterranno due link permanenti che certificano lo stato della pagina al momento del salvataggio:
- Copia di archivio: https://web.archive.org/web/20200105171207/https://www.instagram.com/target/
- Schermata: https://web.archive.org/web/20200105171207/http://web.archive.org/screenshot/https://www.instagram.com/target/
Con Archive.today la procedura è molto simile, con la differenza che si ottiene un unico link da cui si può vedere una riproduzione fedele della pagina e la relativa schermata.
Nel nostro esempio: https://archive.md/0kTgO
Generalmente le pagine cristallizzate con Archive.today sono un pochino più fedeli all’originale, ma non è una regola ferrea e va presa con le pinze. In ogni caso, le pagine acquisite con Wayback Machine conservano i nomi originali dei file multimediali (che potrebbero essere assai importanti).
Pertanto è spesso opportuno provare a fare l’acquisizione con entrambi gli strumenti, salvando poi gli URL delle copie così ottenute. I due siti forniscono anche gli screenshot, ma essi sono solamente a supporto dell’acquisizione e non la sostituiscono.
Una cosa utile da ricordare è che le pagine salvate su Archive.today possono venire indicizzate dai motori di ricerca. Per questo motivo, potrebbe essere preferibile non usare questo strumento se si ha a che fare con dei contenuti diffamatori.
Usando questa semplice procedura siamo già in una situazione mille volte migliore di chi si ritrova ad aver catturato solo una schermata.
Estrazione dei metadati
Apparentemente, quanto discusso prima sembra coprire al 100% la necessità di acquisire un profilo Instagram. Ma se avete mai adoperato questo social network tramite app, vi sarà venuta in mente la frase idiomatica:
There is more than meets the eye
Infatti il problema fondamentale in questo caso è che un profilo Instagram visualizzato tramite pagina web non contiene tutte le informazioni ottenibili con l’app.
Per esempio, ecco cosa succede con la versione iOS di Instagram:


Target ha indicato un numero di telefono e un indirizzo email che compaiono tramite il tasto Contatta. Tuttavia non c’è traccia di questi dati nella versione web di Instagram. Questo significa che sarebbe impossibile acquisirli dal sito, anche usando strumenti professionali.
Per ovviare a questo problema, possiamo attuare una procedura che simula il comportamento dell’applicazione ufficiale di Instagram usando le relative API private.
Questa parte è più complessa ed è dedicata agli addetti ai lavori, in quanto richiede la realizzazione di un piccolo software.
Dopo aver registrato un account di test su Instagram, possiamo creare un breve programma in linguaggio PHP che sfrutti la libreria Instagram-API. Prima di tutto, è necessario installare la libreria con Composer:
composer require mgp25/instagram-phpPoi si può adattare uno dei tanti semplici esempi già forniti su GitHub. In particolare, bisogna instanziare la classe e provvedere al login con l’utente di prova:
$ig = new \InstagramAPI\Instagram();
try {
$ig->login($username, $password);
} catch (\Exception $e) {
echo 'Something went wrong: ' . $e->getMessage() . "\n";
exit(0);
}Poi si possono richiedere tutti i metadati del profilo Instagram:
$ig->debug = true;
$userId = $ig->people->getUserIdForName('target');
$information = $ig->people->getInfoById($userId);L’output sarà simile al seguente:
GET: https://i.instagram.com/api/v1/users/209372398/info/
→ 0B
← 200 1.28kB
RESPONSE: {"user": {"pk": 209372398, "username": "target", "full_name": "Target", "is_private": false, "profile_pic_url": "https://instagram.fmxp1-1.fna.fbcdn.net/v/t51.2885-19/s150x150/10616997_545412705606932_1457477944_a.jpg?_nc_ht=instagram.fmxp1-1.fna.fbcdn.net\u0026_nc_ohc=qznruIvb6aYAX9yMilW\u0026oh=ffd42565e3e93beec8d527f54e17f72c\u0026oe=5EABFBBC", "is_verified": true, "has_anonymous_profile_picture": false, "media_count": 1647, "geo_media_count": 0, "follower_count": 4259469, "following_count": 5011, "following_tag_count": 12, "biography": "Your happy place on Instagram. \u2728\nTag @Target in your pics for a chance to be featured.\nShop our feed:", "biography_with_entities": {"raw_text": "Your happy place on Instagram. \u2728\nTag @Target in your pics for a chance to be featured.\nShop our feed:", "entities": [{"user": {"id": 209372398, "username": "target"}}]}, "external_url": "http://tgt.biz/ShopTarget", "external_lynx_url": "https://l.instagram.com/?u=http%3A%2F%2Ftgt.biz%2FShopTarget\u0026e=ATPSau2TC3aUeL8YfryH5-RiMm6G6Tpd07GDJANXe9moIp23lH-fHFfJd7EPb-PlwqdxztXSpN8bAEYPpw", "total_igtv_videos": 7, "has_igtv_series": false, "total_ar_effects": 0, "usertags_count": 2829304, "is_favorite": false, "is_favorite_for_stories": false, "is_favorite_for_highlights": false, "live_subscription_status": "default", "is_interest_account": true, "has_recommend_accounts": false, "has_chaining": true, "hd_profile_pic_url_info": {"url": "https://instagram.fmxp1-1.fna.fbcdn.net/v/t51.2885-19/10616997_545412705606932_1457477944_a.jpg?_nc_ht=instagram.fmxp1-1.fna.fbcdn.net\u0026_nc_ohc=qznruIvb6aYAX9yMilW\u0026oh=955504de4807130f11983896ece1e7a4\u0026oe=5E9D0CC6", "width": 180, "height": 180}, "mutual_followers_count": 0, "show_shoppable_feed": true, "shoppable_posts_count": 253, "can_be_reported_as_fraud": true, "merchant_checkout_style": "none", "has_highlight_reels": true, "direct_messaging": "UNKNOWN", "fb_page_call_to_action_id": "", "address_street": "", "business_contact_method": "CALL", "category": "Retail Company", "city_id": 0, "city_name": "", "contact_phone_number": "+18004400680", "is_call_to_action_enabled": false, "latitude": 0.0, "longitude": 0.0, "public_email": "target.SocialMedia@target.com", "public_phone_country_code": "1", "public_phone_number": "8004400680", "zip": "", "instagram_location_id": "", "is_business": true, "account_type": 2, "can_hide_category": true, "can_hide_public_contacts": true, "should_show_category": true, "should_show_public_contacts": true, "should_show_tabbed_inbox": false, "can_see_primary_country_in_settings": false, "include_direct_blacklist_status": true, "is_potential_business": true, "is_bestie": false, "has_unseen_besties_media": false, "show_account_transparency_details": true, "show_leave_feedback": false, "auto_expand_chaining": false, "highlight_reshare_disabled": false, "show_post_insights_entry_point": false, "about_your_account_bloks_entrypoint_enabled": false}, "status": "ok"}In particolare, all’interno della risposta JSON è possibile individuare i seguenti campi:
"public_email": "target.SocialMedia@target.com",
"public_phone_country_code": "1",
"public_phone_number": "8004400680",Consiglio di prestare molta attenzione al codice numerico instagram_location_id, anche se non è sempre presente. Questo valore è estremamente interessante perché permette di collegare una pagina Instagram a una pagina Facebook.
Prendendo come esempio l’account Instagram ikeauk, si ottiene il codice 187578611279774, da cui si ricava immediatamente un valido URL su Facebook: https://www.facebook.com/187578611279774/
Considerazioni finali
Grazie ai siti di archiviazione è possibile procedere a una prima cristallizzazione “di base” di un profilo Instagram. Simulando invece il comportamento dell’app per cellulari si può accedere a molti altri metadati, non altrimenti visibili.
L’ultimo consiglio che vi posso dare è quello di unire la procedura in PHP all’uso di mitmproxy per registrare tutti i flussi HTTPS intercorsi durante l’acquisizione. Vi basterà avviarlo e assicurarvi che il proxy sia correttamente impostato nel codice PHP:
$ig->setProxy('http://127.0.0.1:8080');
$ig->setVerifySSL(false);Così facendo, potrete finalizzare il lavoro producendo il file registrato da mitmproxy, lo script di acquisizione, il relativo output ridirezionato in un file di testo e un breve report in PDF dentro a un archivio ZIP. Alla fine basterà apporre la firma digitale e la marca temporale.
Aggiornamento del 6 gennaio 2020: in seguito al graditissimo suggerimento di Paolo Dal Checco, ho aggiunto una precisazione sul fatto che le pagine memorizzate da Archive.today sono indicizzabili dai motori di ricerca.

Articolo molto interessante ed approfondito.
Anch’io pensavo che bastasse catturare uno screenshot come valido supporto per provare una violazione su internet, ma evidentemente mi sbagliavo.
Grazie per avermi chiarito le idee in proposito, e per aver spiegato alcuni metodi molto interessanti di raccolta informazioni ad uso forense e/o personale 🙂
Eh sì, purtroppo c’è ancora questa percezione errata e a volte le persone arrivano con solo uno screenshot “per le mani”, mentre il contenuto originale è già stato cancellato. È sempre opportuno rivolgersi rapidamente a un consulente tecnico quando si ha intenzione di adire le vie legali.
Caro Lazza, sapessi quante volte leggo di troll frignoni su sistemi tipo Disqus che pensano che basti uno screenshot per denunciare qualcuno, grazie per la precisazione…
Grazie, articolo molto interessante. Non ho ancora avuto modo di provare il metodo consigliato, ma è possibile usando le API di Instagram estrapolare e fare una copia di backup anche dei messaggi vocali all’interno dei Direct Messages? Lo chiedo perché ho avuto modo di usare sia la funzione di download dei dati di un profilo interna a Instragram, sia software di acquisizione forense che costano svariate migliaia di euro, ma nessuno riesce a estrapolare e fare copia dei messaggi vocali di una chat, che molto spesso possono contenere minacce, diffamazioni e quant’altro di rilevante da un punto di vista di infrazione della legge.
Davide, assolutamente sì. Le API accedono ai dati disponibili alle applicazioni mobili.
Se conosci il nickname o il codice utente dell’interlocutore, puoi usare il metodo
getThreadByParticipants:Ottenendo così un oggetto con all’interno un campo
threadche contiene un campoitems, cioè i messaggi dal più recente al più vecchio:Puoi quindi realizzare un piccolo script che iteri lungo tutto il thread, ove necessario, scaricando gli elementi multimediali o producendone gli URL che poi andrai a scaricare a parte col metodo che ritieni più opportuno. 😉
Excelente artigo.
obrigado pela partilha.
Bom ano 2020!!!
Io dovrei acquisire (con validità giuridica) degli screenshot di specifici post che una persona ha pubblicato nel corso del tempo sul proprio profilo Facebook. In questi casi i sistemi indicati nell’articolo non funzionano perchè l’inidirzzo url è sempre quello del profilo ma il contenuto della pagina è lunghissimo quindi non riescono a memorizzare tutto (e neppure servirebbe); dovrebbero fare lo screenshot solo della parte a video. C’è qualcosa che lo può fare?
Grazie
Attenzione che il solo screenshot non ha molta utilità, è opportuno cristallizzare i contenuti in modo consono. Lo accennavo anche nel post proprio per evitare possibili fraintendimenti. 🙂
Se si devono acquisire specifici post, conviene decidere quali sono i più importanti e poi acquisirne ciascuno separatamente, invece di puntare al profilo Facebook nel suo insieme.
Per maggiori informazioni e per concordare un eventuale incarico, su questa pagina c’è il modulo per contattarmi.
Una possibilità potrebbe essere quella di certificare in qualche modo un’immagine acquisita. Con una tecnologia tipo blockchain. Cosa ne pensi?
Cosa intendi per “certificare”? Se immagini l’uso della blockchain per marcare temporalmente un qualche tipo di hash, quello già si può fare apponendo una marca temporale a norma di legge. 🙂
Articolo davvero interessante! La situazione, con il solo screenshot, non è certo ottimale, forse però è meno disastrosa di quanto sembra.
Leggevo di una recente sentenza della cassazione (che però non ho approfondito nel testo specifico, quindi l’idea che mi sono fatto potrebbe non essere correttissima) che dichiarava le copie di email e messaggi in generale come prove valide equiparandole alle copie meccaniche (essenzialmente, le fotocopie), che non sono automaticamente valide come prove certe, ma neanche automaticamente non valide, né invalidabili indicando motivazioni (troppo) generiche, anche se tecniche (credo).
Insomma, la palla passa alla controparte, insieme all’onere della (contro-)prova: il modo migliore per contestare l’attendibilità di un certo messaggio, a questo punto, è confutarne il contenuto (se non se ne può mettere in dubbio l’avvenuta spedizione/pubblicazione – a seconda del contesto – come per esempio di una lettera non raccomandata, ma se per esempio contiene una firma la questione si complica di nuovo). Addurre motivazioni tecniche, ma generiche, su quanto sia semplice alterare un certo messaggio potrebbe non bastare, perchè il giudice chiederà cose del tipo: ma questo messaggio è stato alterato oppure no? Ci sono evidenze di alterazione? Un messaggio con un contenuto diverso è mai stato inviato in quella data a quella persona? E qual’era il contenuto originale secondo il mittente?
E qui interviene il rischio che il querelato (per diffamazione o altro) presenti una copia diversa, avendo modificato un post online (come giustamente fatto notare in questo articolo), oppure avendo modificato (se possibile) la propria copia di un messaggio di chat (o simile) con le stesse tecniche che potrebbero essere state usate dal querelante. Però, l’esistenza di un messaggio (online) con un testo diverso potrebbe non bastare al querelato per togliersi d’impiccio: dato che la documentazione del querelante viene accettata salvo prova del contrario (per quanto ho capito), il giudice potrebbe prestare attenzione (o accogliere un’obiezione relativa) alla data della versione presente in rete (e a metadati come i campi http sulle modifiche), per cui l’aver modificato un post dopo aver ricevuto una querela potrebbe risultare alquanto sospetto.
Così però si va a basare tutto sull’interpretazione del giudice, sempre che la questione non si complichi ancora, perchè, nel caso di post online (su blog o social media) potrebbero esistere copie delle versioni precedenti conservate (forse anche con un pizzico di paranoia) dal titolare del sito (del servizio) per tutelarsi da eventuali coinvolgimenti (al di là delle manleve contrattuali – e comunque si potrebbe chiedere una copia del contenuto contestulamente a una richiesta di rimozione di materiale diffamatorio, sensibile o similare secondo quanto previsto dalla legge).
Sicuramente, ad ogni modo, è meglio partire “bene” fin dall’inizio producendo una documentazione più difficile da contestare, e i servizi citati nell’articolo possono essere molto utili allo scopo. A rigore, però, anche questi servizi non sono esattamente “super-partes”, ovvero non possono avere la stessa credibilità della testimonianza (o della certificazione) di un pubblico ufficiale, o di una raccomandata A/R, ma almeno sono terze parti neutrali, quindi possono essere considerati al pari di un testimone attendibile. A rigore, potrebbero subire anche un attacco informatico, come ad esempio un’alterazione dei dns che li reindirizzi verso un sito contraffatto, ma sarebbe uno scenario meno credibile e difficile da dimostrare – se la memoria non mi inganna, un’altra sentenza aveva stabilito che la possibilità di un’alterazione di un “contenuto” a causa di una violazione telematica va dimostrata.
Personalmente, però, ritengo che sarebbe meglio avere a disposizione strumenti tecnico-legali più attendibili. Ormai quasi tutti i siti sono migrati al protocollo https, per i (pochi) siti rimasti “in chiaro” si possono avere problemi di connessione su alcuni browser, e qualche volta si ha anche la possibilità di avere una copia in pdf delle pagine web prodotta direttamente dal sito. Ecco: si potrebbe richiedere a determinati siti (in particolare ai social media) di produrre una copia pdf firmata per le pagine web, utilizzando semplicemente lo stesso certificato di firma usato per il sito (quindi, la chiave privata cripterebbe un hash del documento e la chiave pubblica, normalmente trasmessa dal sito, consentirebbe la verifica della firma – senza esborsi ulteriori per il titolare del servizio). Ovviamente, il procedimento sarebbe simile per i contenuti multimediali (audiomessaggi ecc.).
Un procedimento simile sarebbe particolarmente utile nel caso di matariale presente in aree private, come messaggi privati di altri utenti, o comunicazioni da parte del gestore del servizio,,, con il quale potrebbe aprirsi un qualche tipo di contenzioso (in casi estremi, il concetto potrebe estendersi anche alle copie elettroniche della corrispondenza non raccomandata e non-pec di un ente pubblico). Ovviamente, la cristallizazione di questo tipo di materiale con servizi online come la Wayback machine non è altrettanto semplice, e il materiale in questione, per quanto improbabile, potrebbe essere teoricamente modificato… In questi casi, come si può ottenere una copia più attendibile del materiale online?
Hai accennato a tantissime cose in un solo commento, vediamo di rispondere ai punti principali. 🙂
Ma chi l’ha detto che non si può? Se uno pensa di cavarsela con lo screenshot (vero o meno) di un post, basterà chiedergli di mostrare il post originale… che magari nel frattempo è già stato cancellato.
Sì certamente, l’esempio più attinente sono i siti di archiviazione citati nel post, ma queste copie vanno fatte prima che diventi tardi. 😉 E allora non siamo più nel caso “ho solo uno screenshot”.
“Super partes” è sinonimo di posizione neutrale. 😛 Però grazie che hai citato i pubblici ufficiali, mi hai fatto venire in mente che a volte sento dire che è una buona idea far “certificare” un post sul web da un notaio.
Però il problema è che il notaio può certificare che sta vedendo qualcosa sul suo schermo, non può certificare che quel contenuto è effettivamente su Facebook o su un altro sito. Soprattutto, si va a perdere tutto ciò che non è visibile (codice sorgente, metadati, codici identificativi utente, nomi delle risorse multimediali, ecc) e che spesso si rivela invece determinante per completare correttamente il lavoro.
C’è da capire se il signor Tizio, imputato, sia più portato a modificare una stampa oppure procedere a un MITM sui DNS. E per il certificato TLS come fa? Viola pure la certification authority? 😀
Ma non è, in pratica, la stessa cosa che ottieni facendo l’acquisizione della pagina e registrando tutte le richieste HTTP(S), comprese le chiavi di sessione? Con il vantaggio che ciò funziona su qualsiasi sito, compreso quello del signor Tizio che lui ha aperto per diffamare Caio e di certo non implementerà quella funzione di export “certificato”. 🙂
Per le aree riservate si registra un’acquisizione dopo aver effettuato il login, così i cookie di sessione permettono di accedere alle risorse di interesse. Si può scegliere tra diverse soluzioni software tra cui FAW, Webrecorder/Conifer, o il già citato mitmproxy con un browser a piacere.
Volevo semplicemente rigraziarti per la condivisione gratuita degli script di Mediaset e Rai TV,
due piccoli gioelli che per anni mi hanno consentito di scaricare centinaia di episodi e serie intere delle finction e dei programmi televisivi che piacevano a mia Mamma.
Oggi sono per caso mi sono imbattuto in un link al tuo blog che ho chiaramente cliccato, al termine di una breve passeggiata tra le pagine del tuo blog, mi sono imbattuto in questo post che definire di qualita’ e’ decisamente poco.
Essendo un affamato di “conoscenza” , che nonostante la non piu’ giovane eta’ (58), continua a voler Imparare qualcosa di nuovo, navigo spesso alla ricerca di articoli di questo genere ti posso garantire che non e’ facile trovare qualcosa di simile,
una cascata di informazioni qualitativamente “ben oltre la media” che fluiscono nel tuo cervello senza grossi problemi.
A mio parere sei un Fenomeno mica da ridere e quando mi trovo dinnanzi dei Fenomeni, prima o poi, in un modo o nell’altro, trovo la maniera di fargli sapere quanto apprezzo il lavoro “lavoro”
Lo faccio perche’ ritengo che sia giusto e doveroso dare ‘ “mazzate a chi se le merita”
ma anche fare “compimenti a chi se li merita” e tu te li meriti senza ombra di dubbio.
Un grosso saluto dall’Oriente
Enzo Miracapillo
Grazie per i complimenti. 🙂